MATHSENSEI: A Tool-Augmented Large Language Model for Mathematical Reasoning
2402.17231
1
0

Abstract
Tool-augmented Large Language Models (TALMs) are known to enhance the skillset of large language models (LLMs), thereby, leading to their improved reasoning abilities across many tasks. While, TALMs have been successfully employed in different question-answering benchmarks, their efficacy on complex mathematical reasoning benchmarks, and the potential complementary benefits offered by tools for knowledge retrieval and mathematical equation solving are open research questions. In this work, we present MathSensei, a tool-augmented large language model for mathematical reasoning. We study the complementary benefits of the tools - knowledge retriever (Bing Web Search), program generator + executor (Python), and symbolic equation solver (Wolfram-Alpha API) through evaluations on mathematical reasoning datasets. We perform exhaustive ablations on MATH, a popular dataset for evaluating mathematical reasoning on diverse mathematical disciplines. We also conduct experiments involving well-known tool planners to study the impact of tool sequencing on the model performance. MathSensei achieves 13.5% better accuracy over gpt-3.5-turbo with Chain-of-Thought on the MATH dataset. We further observe that TALMs are not as effective for simpler math word problems (in GSM-8K), and the benefit increases as the complexity and required knowledge increases (progressively over AQuA, MMLU-Math, and higher level complex questions in MATH). The code and data are available at https://github.com/Debrup-61/MathSensei.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- MathSensei is a tool-augmented large language model developed for mathematical reasoning tasks.
- It aims to combine the power of large language models with specialized tools to enhance mathematical problem-solving capabilities.
- The research is supported by Rakuten India Enterprise Private Limited.
Plain English Explanation
MathSensei is a new system that combines a powerful language model, which is like a very smart computer program that can understand and generate human-like text, with specialized tools to help it solve math problems. The idea is that by using both the language model's broad knowledge and the specialized tools, MathSensei can become better at mathematical reasoning and problem-solving than either one on its own.
The language model allows MathSensei to understand math concepts and problems in natural language, just like a human would. But the specialized tools, like calculators or step-by-step solvers, give it additional capabilities to work through complex math steps and arrive at solutions.
This combination of a powerful language understanding model and targeted math tools is intended to make MathSensei a more effective assistant for tasks like tutoring, homework help, or even advanced mathematical research. By drawing on both broad language skills and specialized math abilities, the hope is that MathSensei can provide more comprehensive and insightful support for a wide range of mathematical challenges.
Technical Explanation
The paper presents the design and evaluation of MathSensei, a tool-augmented large language model for mathematical reasoning. The key elements include:
- Architecture: MathSensei is built on top of a base large language model, which is then integrated with various mathematical tools and solvers. This allows the system to leverage the language understanding capabilities of the base model while also tapping into specialized mathematical capabilities.
- Training: The language model is pre-trained on a large corpus of text data, then fine-tuned on a dataset of math-related content. The specialized tools are also trained on relevant mathematical datasets.
- Evaluation: The researchers evaluate MathSensei's performance on a range of math-focused benchmarks, including algebraic word problems, symbolic reasoning tasks, and open-ended mathematical challenges. Comparisons are made to both human experts and other AI systems.
The results suggest that the tool-augmented approach of MathSensei leads to significant improvements in mathematical reasoning abilities compared to either the base language model or the standalone tools on their own. The system demonstrates strong performance across the evaluated tasks, indicating its potential as an assistive technology for mathematical problem-solving.
Critical Analysis
The paper provides a thorough description of the MathSensei system and its evaluation, highlighting its potential benefits. However, a few important caveats and limitations are worth noting:
- The evaluation is focused on a relatively narrow set of benchmark tasks, and it's unclear how MathSensei would perform on a broader range of real-world mathematical challenges. Further testing in diverse, open-ended scenarios would be helpful.
- The integration of the language model and specialized tools is not described in great detail, leaving some uncertainty about the specific mechanisms and interactions involved.
- While the results are promising, the paper does not address potential issues like bias, reliability, or security concerns that could arise from deploying such a system in practice.
Additional research exploring these areas would help strengthen the overall assessment of MathSensei's capabilities and limitations. Nonetheless, the core idea of combining language understanding with targeted mathematical tools is an interesting and potentially impactful approach worth further exploration.
Conclusion
MathSensei represents an innovative attempt to enhance mathematical reasoning capabilities by integrating a powerful language model with specialized mathematical tools and solvers. The results suggest this tool-augmented approach can lead to significant improvements in performance across a variety of math-focused tasks, highlighting its potential as an assistive technology for mathematical problem-solving.
While the current evaluation is promising, further research is needed to fully understand MathSensei's strengths, weaknesses, and real-world applicability. Exploring a broader range of challenges, improving the integration of the language model and tools, and addressing potential deployment concerns would all be valuable next steps. Overall, the MathSensei project demonstrates the promise of combining advanced language understanding with domain-specific capabilities to tackle complex cognitive tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
New!MuMath-Code: Combining Tool-Use Large Language Models with Multi-perspective Data Augmentation for Mathematical Reasoning
Shuo Yin, Weihao You, Zhilong Ji, Guoqiang Zhong, Jinfeng Bai
0
0
The tool-use Large Language Models (LLMs) that integrate with external Python interpreters have significantly enhanced mathematical reasoning capabilities for open-source LLMs, while tool-free methods chose another track: augmenting math reasoning data. However, a great method to integrate the above two research paths and combine their advantages remains to be explored. In this work, we firstly include new math questions via multi-perspective data augmenting methods and then synthesize code-nested solutions to them. The open LLMs (i.e., Llama-2) are finetuned on the augmented dataset to get the resulting models, MuMath-Code ($mu$-Math-Code). During the inference phase, our MuMath-Code generates code and interacts with the external python interpreter to get the execution results. Therefore, MuMath-Code leverages the advantages of both the external tool and data augmentation. To fully leverage the advantages of our augmented data, we propose a two-stage training strategy: In Stage-1, we finetune Llama-2 on pure CoT data to get an intermediate model, which then is trained on the code-nested data in Stage-2 to get the resulting MuMath-Code. Our MuMath-Code-7B achieves 83.8 on GSM8K and 52.4 on MATH, while MuMath-Code-70B model achieves new state-of-the-art performance among open methods -- achieving 90.7% on GSM8K and 55.1% on MATH. Extensive experiments validate the combination of tool use and data augmentation, as well as our two-stage training strategy. We release the proposed dataset along with the associated code for public use.
5/14/2024
Mathify: Evaluating Large Language Models on Mathematical Problem Solving Tasks
Avinash Anand, Mohit Gupta, Kritarth Prasad, Navya Singla, Sanjana Sanjeev, Jatin Kumar, Adarsh Raj Shivam, Rajiv Ratn Shah
0
0
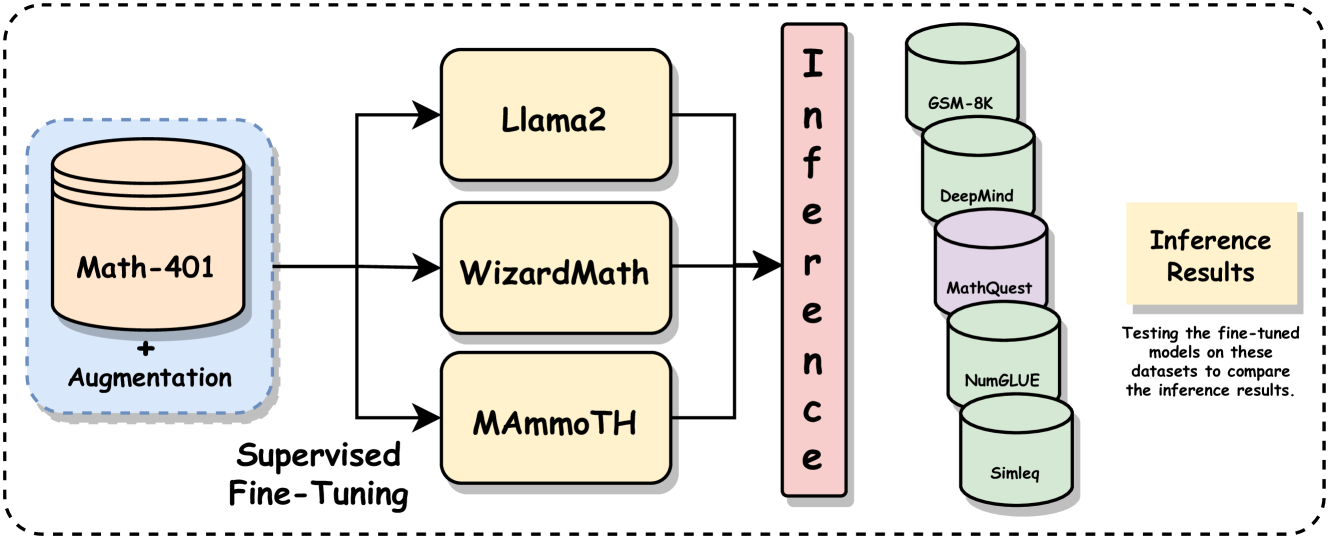
The rapid progress in the field of natural language processing (NLP) systems and the expansion of large language models (LLMs) have opened up numerous opportunities in the field of education and instructional methods. These advancements offer the potential for tailored learning experiences and immediate feedback, all delivered through accessible and cost-effective services. One notable application area for this technological advancement is in the realm of solving mathematical problems. Mathematical problem-solving not only requires the ability to decipher complex problem statements but also the skill to perform precise arithmetic calculations at each step of the problem-solving process. However, the evaluation of the arithmetic capabilities of large language models remains an area that has received relatively little attention. In response, we introduce an extensive mathematics dataset called MathQuest sourced from the 11th and 12th standard Mathematics NCERT textbooks. This dataset encompasses mathematical challenges of varying complexity and covers a wide range of mathematical concepts. Utilizing this dataset, we conduct fine-tuning experiments with three prominent LLMs: LLaMA-2, WizardMath, and MAmmoTH. These fine-tuned models serve as benchmarks for evaluating their performance on our dataset. Our experiments reveal that among the three models, MAmmoTH-13B emerges as the most proficient, achieving the highest level of competence in solving the presented mathematical problems. Consequently, MAmmoTH-13B establishes itself as a robust and dependable benchmark for addressing NCERT mathematics problems.
4/23/2024

Large Language Models for Mathematical Reasoning: Progresses and Challenges
Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, Wenpeng Yin
0
0
Mathematical reasoning serves as a cornerstone for assessing the fundamental cognitive capabilities of human intelligence. In recent times, there has been a notable surge in the development of Large Language Models (LLMs) geared towards the automated resolution of mathematical problems. However, the landscape of mathematical problem types is vast and varied, with LLM-oriented techniques undergoing evaluation across diverse datasets and settings. This diversity makes it challenging to discern the true advancements and obstacles within this burgeoning field. This survey endeavors to address four pivotal dimensions: i) a comprehensive exploration of the various mathematical problems and their corresponding datasets that have been investigated; ii) an examination of the spectrum of LLM-oriented techniques that have been proposed for mathematical problem-solving; iii) an overview of factors and concerns affecting LLMs in solving math; and iv) an elucidation of the persisting challenges within this domain. To the best of our knowledge, this survey stands as one of the first extensive examinations of the landscape of LLMs in the realm of mathematics, providing a holistic perspective on the current state, accomplishments, and future challenges in this rapidly evolving field.
4/8/2024

MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T. Kwok, Zhenguo Li, Adrian Weller, Weiyang Liu
0
0
Large language models (LLMs) have pushed the limits of natural language understanding and exhibited excellent problem-solving ability. Despite the great success, most existing open-source LLMs (e.g., LLaMA-2) are still far away from satisfactory for solving mathematical problem due to the complex reasoning procedures. To bridge this gap, we propose MetaMath, a fine-tuned language model that specializes in mathematical reasoning. Specifically, we start by bootstrapping mathematical questions by rewriting the question from multiple perspectives without extra knowledge, which results in a new dataset called MetaMathQA. Then we fine-tune the LLaMA-2 models on MetaMathQA. Experimental results on two popular benchmarks (i.e., GSM8K and MATH) for mathematical reasoning demonstrate that MetaMath outperforms a suite of open-source LLMs by a significant margin. Our MetaMath-7B model achieves 66.4% on GSM8K and 19.4% on MATH, exceeding the state-of-the-art models of the same size by 11.5% and 8.7%. Particularly, MetaMath-70B achieves an accuracy of 82.3% on GSM8K, slightly better than GPT-3.5-Turbo. We release all the MetaMathQA dataset, the MetaMath models with different model sizes and the training code for public use.
5/6/2024