Maximum diffusion reinforcement learning
2309.15293
0
0

Abstract
Robots and animals both experience the world through their bodies and senses. Their embodiment constrains their experiences, ensuring they unfold continuously in space and time. As a result, the experiences of embodied agents are intrinsically correlated. Correlations create fundamental challenges for machine learning, as most techniques rely on the assumption that data are independent and identically distributed. In reinforcement learning, where data are directly collected from an agent's sequential experiences, violations of this assumption are often unavoidable. Here, we derive a method that overcomes this issue by exploiting the statistical mechanics of ergodic processes, which we term maximum diffusion reinforcement learning. By decorrelating agent experiences, our approach provably enables single-shot learning in continuous deployments over the course of individual task attempts. Moreover, we prove our approach generalizes well-known maximum entropy techniques, and robustly exceeds state-of-the-art performance across popular benchmarks. Our results at the nexus of physics, learning, and control form a foundation for transparent and reliable decision-making in embodied reinforcement learning agents.
Create account to get full access
Introduction
The research paper explores a novel reinforcement learning technique called "Maximum Diffusion Reinforcement Learning." This approach aims to tackle the challenge of exploration in reinforcement learning environments by encouraging the agent to take actions that maximize the diffusion of its state visitation distribution. The key idea is to create an exploration strategy that leads to more diverse and informative experiences, ultimately improving the agent's learning and performance.
Results
Temporal correlations hinder performance
The paper presents experiments demonstrating that temporally correlated exploration strategies, such as random walk or epsilon-greedy, can lead to suboptimal performance. These strategies often result in the agent getting stuck in local regions of the state space, limiting its ability to discover valuable information.
Maximum diffusion exploration and learning
To address this issue, the researchers propose the "Maximum Diffusion Reinforcement Learning" (MDRL) algorithm. MDRL encourages the agent to take actions that maximize the diffusion, or spread, of its state visitation distribution. This exploration strategy helps the agent cover a wider range of the state space, leading to more informative experiences and improved learning.
The paper provides empirical evidence showing that MDRL outperforms traditional exploration methods in various reinforcement learning environments, including reduce-risk-assistive-rl-policies-diffusion, sample-efficient-robust-multi-agent-rl, and surprise-adaptive-intrinsic-motivation-unsupervised-rl.
Critical Analysis
The paper provides a novel and promising approach to exploration in reinforcement learning, but it also acknowledges several limitations and areas for further research. For example, the authors note that the computational overhead of calculating the diffusion of the state visitation distribution may be a challenge for large-scale or real-time applications. Additionally, the paper suggests that the MDRL approach may be less effective in environments with sparse rewards or highly complex dynamics.
Conclusion
The "Maximum Diffusion Reinforcement Learning" paper presents an innovative exploration strategy that can improve the performance of reinforcement learning agents. By encouraging the agent to take actions that maximize the diffusion of its state visitation distribution, the MDRL algorithm helps the agent explore a wider range of the state space and gather more informative experiences. While the approach has some limitations, it offers a valuable contribution to the field of reinforcement learning and could inspire further research on efficient exploration techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Deep Dive into Model-free Reinforcement Learning for Biological and Robotic Systems: Theory and Practice
Yusheng Jiao, Feng Ling, Sina Heydari, Nicolas Heess, Josh Merel, Eva Kanso
0
0
Animals and robots exist in a physical world and must coordinate their bodies to achieve behavioral objectives. With recent developments in deep reinforcement learning, it is now possible for scientists and engineers to obtain sensorimotor strategies (policies) for specific tasks using physically simulated bodies and environments. However, the utility of these methods goes beyond the constraints of a specific task; they offer an exciting framework for understanding the organization of an animal sensorimotor system in connection to its morphology and physical interaction with the environment, as well as for deriving general design rules for sensing and actuation in robotic systems. Algorithms and code implementing both learning agents and environments are increasingly available, but the basic assumptions and choices that go into the formulation of an embodied feedback control problem using deep reinforcement learning may not be immediately apparent. Here, we present a concise exposition of the mathematical and algorithmic aspects of model-free reinforcement learning, specifically through the use of textit{actor-critic} methods, as a tool for investigating the feedback control underlying animal and robotic behavior.
5/21/2024
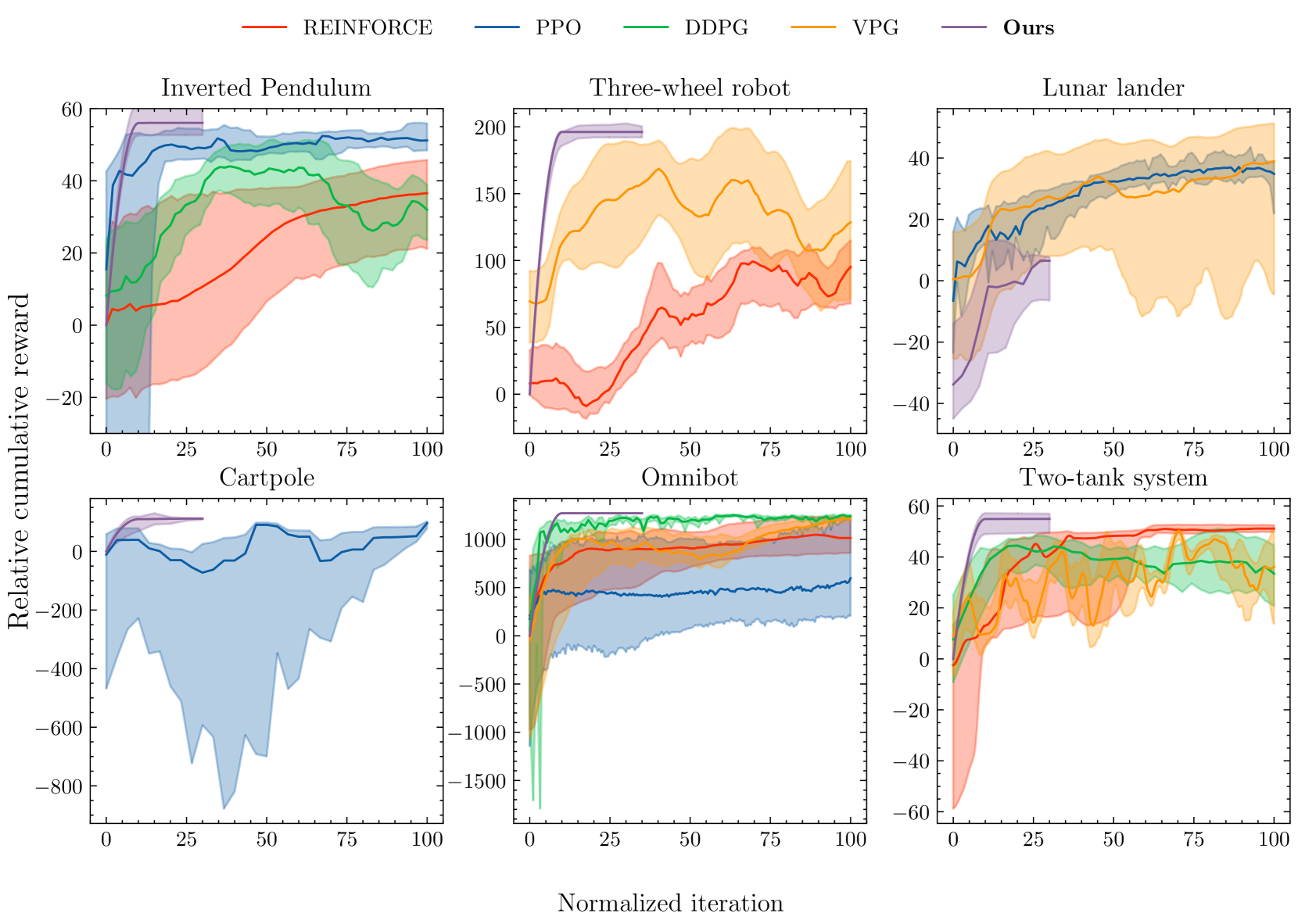
An approach to improve agent learning via guaranteeing goal reaching in all episodes
Pavel Osinenko, Grigory Yaremenko, Georgiy Malaniya, Anton Bolychev
0
0
Reinforcement learning is commonly concerned with problems of maximizing accumulated rewards in Markov decision processes. Oftentimes, a certain goal state or a subset of the state space attain maximal reward. In such a case, the environment may be considered solved when the goal is reached. Whereas numerous techniques, learning or non-learning based, exist for solving environments, doing so optimally is the biggest challenge. Say, one may choose a reward rate which penalizes the action effort. Reinforcement learning is currently among the most actively developed frameworks for solving environments optimally by virtue of maximizing accumulated reward, in other words, returns. Yet, tuning agents is a notoriously hard task as reported in a series of works. Our aim here is to help the agent learn a near-optimal policy efficiently while ensuring a goal reaching property of some basis policy that merely solves the environment. We suggest an algorithm, which is fairly flexible, and can be used to augment practically any agent as long as it comprises of a critic. A formal proof of a goal reaching property is provided. Simulation experiments on six problems under five agents, including the benchmarked one, provided an empirical evidence that the learning can indeed be boosted while ensuring goal reaching property.
5/30/2024
🏅
Reducing Risk for Assistive Reinforcement Learning Policies with Diffusion Models
Andrii Tytarenko
0
0
Care-giving and assistive robotics, driven by advancements in AI, offer promising solutions to meet the growing demand for care, particularly in the context of increasing numbers of individuals requiring assistance. This creates a pressing need for efficient and safe assistive devices, particularly in light of heightened demand due to war-related injuries. While cost has been a barrier to accessibility, technological progress is able to democratize these solutions. Safety remains a paramount concern, especially given the intricate interactions between assistive robots and humans. This study explores the application of reinforcement learning (RL) and imitation learning, in improving policy design for assistive robots. The proposed approach makes the risky policies safer without additional environmental interactions. Through experimentation using simulated environments, the enhancement of the conventional RL approaches in tasks related to assistive robotics is demonstrated.
5/14/2024
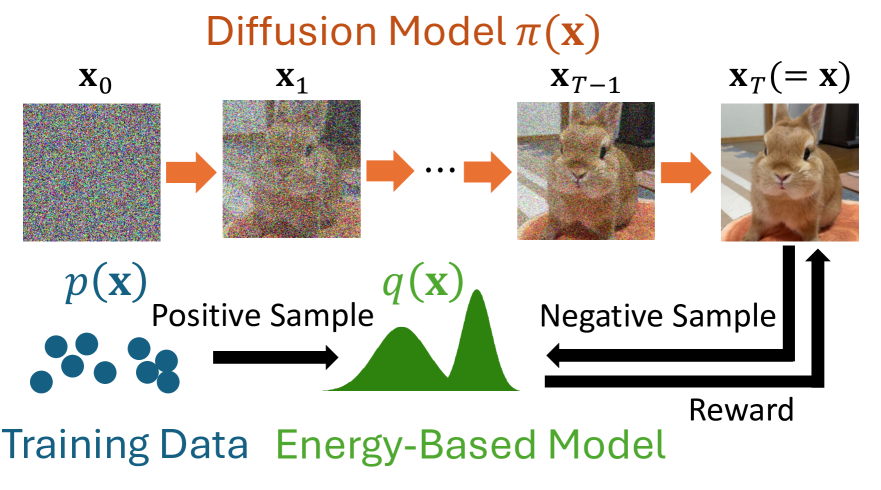
Maximum Entropy Inverse Reinforcement Learning of Diffusion Models with Energy-Based Models
Sangwoong Yoon, Himchan Hwang, Dohyun Kwon, Yung-Kyun Noh, Frank C. Park
0
0
We present a maximum entropy inverse reinforcement learning (IRL) approach for improving the sample quality of diffusion generative models, especially when the number of generation time steps is small. Similar to how IRL trains a policy based on the reward function learned from expert demonstrations, we train (or fine-tune) a diffusion model using the log probability density estimated from training data. Since we employ an energy-based model (EBM) to represent the log density, our approach boils down to the joint training of a diffusion model and an EBM. Our IRL formulation, named Diffusion by Maximum Entropy IRL (DxMI), is a minimax problem that reaches equilibrium when both models converge to the data distribution. The entropy maximization plays a key role in DxMI, facilitating the exploration of the diffusion model and ensuring the convergence of the EBM. We also propose Diffusion by Dynamic Programming (DxDP), a novel reinforcement learning algorithm for diffusion models, as a subroutine in DxMI. DxDP makes the diffusion model update in DxMI efficient by transforming the original problem into an optimal control formulation where value functions replace back-propagation in time. Our empirical studies show that diffusion models fine-tuned using DxMI can generate high-quality samples in as few as 4 and 10 steps. Additionally, DxMI enables the training of an EBM without MCMC, stabilizing EBM training dynamics and enhancing anomaly detection performance.
7/2/2024