Maximum Entropy Inverse Reinforcement Learning of Diffusion Models with Energy-Based Models

0
Sign in to get full access
Overview
- This paper proposes a novel approach for learning diffusion models using energy-based models and maximum entropy inverse reinforcement learning.
- The key ideas are to use energy-based models to capture the complex dynamics of diffusion processes and to leverage maximum entropy inverse reinforcement learning to learn the underlying reward function that governs the diffusion.
- The paper demonstrates the effectiveness of this approach on several benchmark tasks and highlights its potential for applications in areas like reinforcement learning, generative modeling, and decision-making.
Plain English Explanation
The paper introduces a new way to model and learn complex diffusion processes, which are systems where something (like information, heat, or a disease) spreads out over time. The researchers use a type of machine learning model called an "energy-based model" to capture the dynamics of the diffusion. Energy-based models can represent complicated patterns and behaviors in a flexible way.
To train these energy-based diffusion models, the researchers use a technique called "maximum entropy inverse reinforcement learning." This means they try to learn the underlying "reward function" that is driving the diffusion process, without directly observing it. The key insight is that by finding the reward function that best explains the observed diffusion, they can then use that to build a powerful model of the dynamics.
The paper on learning energy-based models by cooperative diffusion and the paper on convergence of model-free entropy-regularized inverse reinforcement provide important background on the technical approaches used in this work.
The researchers demonstrate that their approach works well on several benchmark tasks, showing that it can accurately model complex diffusion processes. They highlight how this could be useful in areas like reinforcement learning, where you want to infer the underlying rewards that drive an agent's behavior, as well as in generative modeling and decision-making.
Technical Explanation
The paper proposes a novel framework for learning diffusion models using energy-based models and maximum entropy inverse reinforcement learning (ME-IRL). The key elements are:
-
Energy-Based Diffusion Models: The researchers model the diffusion process using an energy-based model, which can capture the complex dynamics and patterns of the diffusion. This builds on prior work on learning energy-based models by cooperative diffusion.
-
Maximum Entropy Inverse Reinforcement Learning: To train the energy-based diffusion model, the researchers use a maximum entropy inverse reinforcement learning (ME-IRL) approach. This allows them to learn the underlying reward function that governs the diffusion process, without directly observing it. The paper on convergence of model-free entropy-regularized inverse reinforcement provides important background on ME-IRL.
-
Diffusion Spectral Representation: The researchers also introduce a diffusion spectral representation, which provides a compact and informative way to represent the diffusion dynamics. This builds on ideas from the paper on diffusion spectral representation for reinforcement learning.
-
Experimental Evaluation: The researchers evaluate their approach on several benchmark tasks, including simulated diffusion processes and real-world datasets. They show that their energy-based diffusion models with ME-IRL can accurately capture the underlying dynamics and outperform alternative methods.
The researchers also discuss connections to other related work, such as the paper on EM distillation for one-step diffusion models and the paper on learning iterative reasoning through energy diffusion.
Critical Analysis
The paper presents a well-designed and thorough approach for learning diffusion models using energy-based models and maximum entropy inverse reinforcement learning. The researchers carefully address important technical challenges and provide strong experimental results to validate their approach.
One potential limitation is that the method relies on the ability to accurately model the diffusion dynamics using energy-based models. While the researchers demonstrate the effectiveness of this approach, it may be challenging to apply in domains with very complex or high-dimensional diffusion processes.
Additionally, the paper does not extensively discuss potential issues or caveats with the maximum entropy inverse reinforcement learning approach. It would be helpful to see a more in-depth discussion of the limitations and assumptions of this technique, as well as potential ways to address them.
Overall, the paper makes a valuable contribution to the field of diffusion modeling and reinforcement learning. The proposed framework offers a promising direction for further research and potential real-world applications.
Conclusion
This paper introduces a novel approach for learning diffusion models using energy-based models and maximum entropy inverse reinforcement learning. By capturing the complex dynamics of diffusion processes with energy-based models and leveraging the power of maximum entropy inverse reinforcement learning to infer the underlying reward function, the researchers have developed a flexible and effective framework for modeling and understanding diffusion phenomena.
The results demonstrate the potential of this approach for a range of applications, from reinforcement learning and generative modeling to decision-making and beyond. As the field of diffusion modeling continues to evolve, this work represents an important step forward, highlighting the value of combining advanced machine learning techniques to tackle complex real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Maximum Entropy Inverse Reinforcement Learning of Diffusion Models with Energy-Based Models
Sangwoong Yoon, Himchan Hwang, Dohyun Kwon, Yung-Kyun Noh, Frank C. Park
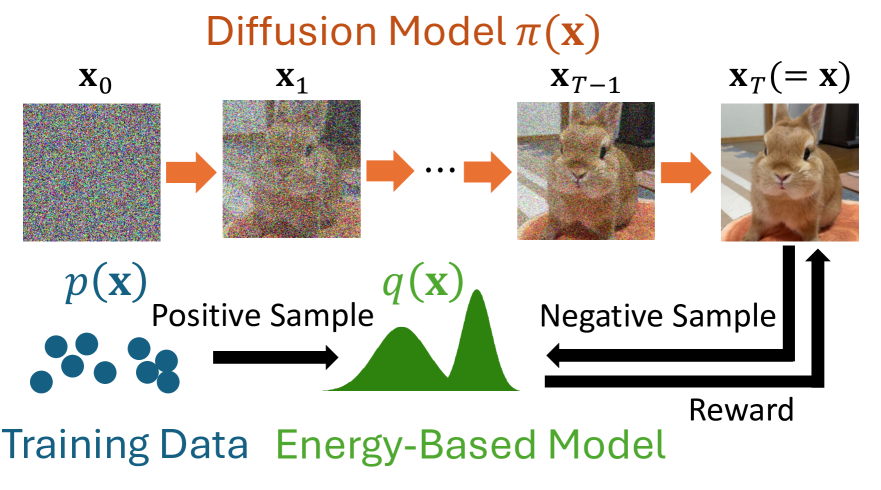
We present a maximum entropy inverse reinforcement learning (IRL) approach for improving the sample quality of diffusion generative models, especially when the number of generation time steps is small. Similar to how IRL trains a policy based on the reward function learned from expert demonstrations, we train (or fine-tune) a diffusion model using the log probability density estimated from training data. Since we employ an energy-based model (EBM) to represent the log density, our approach boils down to the joint training of a diffusion model and an EBM. Our IRL formulation, named Diffusion by Maximum Entropy IRL (DxMI), is a minimax problem that reaches equilibrium when both models converge to the data distribution. The entropy maximization plays a key role in DxMI, facilitating the exploration of the diffusion model and ensuring the convergence of the EBM. We also propose Diffusion by Dynamic Programming (DxDP), a novel reinforcement learning algorithm for diffusion models, as a subroutine in DxMI. DxDP makes the diffusion model update in DxMI efficient by transforming the original problem into an optimal control formulation where value functions replace back-propagation in time. Our empirical studies show that diffusion models fine-tuned using DxMI can generate high-quality samples in as few as 4 and 10 steps. Additionally, DxMI enables the training of an EBM without MCMC, stabilizing EBM training dynamics and enhancing anomaly detection performance.
Read more7/2/2024

0
Feedback Efficient Online Fine-Tuning of Diffusion Models
Masatoshi Uehara, Yulai Zhao, Kevin Black, Ehsan Hajiramezanali, Gabriele Scalia, Nathaniel Lee Diamant, Alex M Tseng, Sergey Levine, Tommaso Biancalani
Diffusion models excel at modeling complex data distributions, including those of images, proteins, and small molecules. However, in many cases, our goal is to model parts of the distribution that maximize certain properties: for example, we may want to generate images with high aesthetic quality, or molecules with high bioactivity. It is natural to frame this as a reinforcement learning (RL) problem, in which the objective is to fine-tune a diffusion model to maximize a reward function that corresponds to some property. Even with access to online queries of the ground-truth reward function, efficiently discovering high-reward samples can be challenging: they might have a low probability in the initial distribution, and there might be many infeasible samples that do not even have a well-defined reward (e.g., unnatural images or physically impossible molecules). In this work, we propose a novel reinforcement learning procedure that efficiently explores on the manifold of feasible samples. We present a theoretical analysis providing a regret guarantee, as well as empirical validation across three domains: images, biological sequences, and molecules.
Read more7/19/2024
🌐
0
Learning Energy-Based Models by Cooperative Diffusion Recovery Likelihood
Yaxuan Zhu, Jianwen Xie, Yingnian Wu, Ruiqi Gao
Training energy-based models (EBMs) on high-dimensional data can be both challenging and time-consuming, and there exists a noticeable gap in sample quality between EBMs and other generative frameworks like GANs and diffusion models. To close this gap, inspired by the recent efforts of learning EBMs by maximizing diffusion recovery likelihood (DRL), we propose cooperative diffusion recovery likelihood (CDRL), an effective approach to tractably learn and sample from a series of EBMs defined on increasingly noisy versions of a dataset, paired with an initializer model for each EBM. At each noise level, the two models are jointly estimated within a cooperative training framework: samples from the initializer serve as starting points that are refined by a few MCMC sampling steps from the EBM. The EBM is then optimized by maximizing recovery likelihood, while the initializer model is optimized by learning from the difference between the refined samples and the initial samples. In addition, we made several practical designs for EBM training to further improve the sample quality. Combining these advances, our approach significantly boost the generation performance compared to existing EBM methods on CIFAR-10 and ImageNet datasets. We also demonstrate the effectiveness of our models for several downstream tasks, including classifier-free guided generation, compositional generation, image inpainting and out-of-distribution detection.
Read more4/19/2024
🏅
0
Convergence of a model-free entropy-regularized inverse reinforcement learning algorithm
Titouan Renard, Andreas Schlaginhaufen, Tingting Ni, Maryam Kamgarpour
Given a dataset of expert demonstrations, inverse reinforcement learning (IRL) aims to recover a reward for which the expert is optimal. This work proposes a model-free algorithm to solve entropy-regularized IRL problem. In particular, we employ a stochastic gradient descent update for the reward and a stochastic soft policy iteration update for the policy. Assuming access to a generative model, we prove that our algorithm is guaranteed to recover a reward for which the expert is $varepsilon$-optimal using $mathcal{O}(1/varepsilon^{2})$ samples of the Markov decision process (MDP). Furthermore, with $mathcal{O}(1/varepsilon^{4})$ samples we prove that the optimal policy corresponding to the recovered reward is $varepsilon$-close to the expert policy in total variation distance.
Read more4/24/2024