Learning Energy-Based Models by Cooperative Diffusion Recovery Likelihood

0
🌐
Sign in to get full access
Overview
- Training energy-based models (EBMs) on high-dimensional data can be challenging and time-consuming
- There is a noticeable gap in sample quality between EBMs and other generative models like GANs and diffusion models
- The paper proposes a new approach called Cooperative Diffusion Recovery Likelihood (CDRL) to address this gap
Plain English Explanation
Energy-based models (EBMs) are a type of machine learning model that can be used to generate new data, such as images. However, training EBMs on complex, high-dimensional data like images can be difficult and take a long time.
Additionally, the quality of the samples generated by EBMs has typically been lower than the quality of samples generated by other types of generative models, such as Generative Adversarial Networks (GANs) and diffusion models.
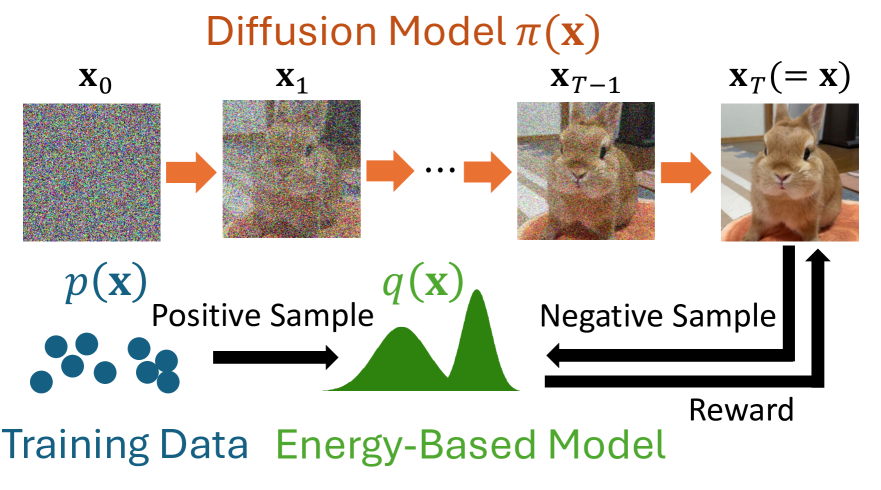
To address this gap, the researchers in this paper propose a new approach called Cooperative Diffusion Recovery Likelihood (CDRL). The key ideas behind CDRL are:
- Training a series of EBMs on increasingly noisy versions of the dataset, rather than just one EBM.
- Pairing each EBM with an "initializer" model that generates starting points for the EBM to refine.
- Training the EBM and initializer model cooperatively, with the initializer learning from the differences between its initial samples and the refined samples from the EBM.
By using this cooperative training approach and combining it with some other practical techniques, the researchers were able to significantly improve the quality of the samples generated by their EBM-based models, compared to previous EBM methods.
Technical Explanation
The core of the CDRL approach is to train a series of EBMs, each defined on an increasingly noisy version of the dataset, along with an "initializer" model for each EBM. The EBM and initializer are trained cooperatively: the initializer generates starting points that are then refined by a few steps of Markov Chain Monte Carlo (MCMC) sampling from the corresponding EBM. The EBM is then optimized by maximizing the likelihood of recovering the refined samples from the noisy starting points, while the initializer is optimized to learn from the differences between its initial samples and the refined samples.
The researchers also made several practical design choices to further improve the sample quality, such as using a combination of different MCMC step sizes and annealing schedules, and applying techniques like input jittering and augmentation.
The CDRL approach was evaluated on the CIFAR-10 and ImageNet datasets, where it significantly outperformed previous EBM methods in terms of sample quality. The researchers also demonstrated the effectiveness of their models on several downstream tasks, including classifier-free guided generation, compositional generation, image inpainting, and out-of-distribution detection.
Critical Analysis
The paper presents a novel and effective approach to training EBMs on high-dimensional data. The cooperative training framework, where the initializer model and EBM model learn from each other, is a clever way to address the sample quality gap between EBMs and other generative models.
However, the paper does not discuss the computational complexity and training time of the CDRL approach, which could be a potential limitation, especially when scaling to larger datasets. Additionally, the paper does not delve into the theoretical justification for the cooperative training framework or provide an in-depth analysis of why it leads to improved sample quality.
It would also be interesting to see how CDRL compares to more recent advances in diffusion models, such as DriftRec or Imitation Game, which have also shown impressive results on high-dimensional data generation.
Conclusion
The Cooperative Diffusion Recovery Likelihood (CDRL) approach proposed in this paper is a significant step forward in training high-quality energy-based models on complex, high-dimensional data. By combining a cooperative training framework with a series of EBMs defined on noisy versions of the dataset, the researchers were able to substantially improve the sample quality compared to previous EBM methods.
The demonstrated effectiveness of CDRL on a range of downstream tasks, such as classifier-free guided generation, compositional generation, and out-of-distribution detection, suggests that this approach could have broad applications in the field of generative modeling and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
0
Learning Energy-Based Models by Cooperative Diffusion Recovery Likelihood
Yaxuan Zhu, Jianwen Xie, Yingnian Wu, Ruiqi Gao
Training energy-based models (EBMs) on high-dimensional data can be both challenging and time-consuming, and there exists a noticeable gap in sample quality between EBMs and other generative frameworks like GANs and diffusion models. To close this gap, inspired by the recent efforts of learning EBMs by maximizing diffusion recovery likelihood (DRL), we propose cooperative diffusion recovery likelihood (CDRL), an effective approach to tractably learn and sample from a series of EBMs defined on increasingly noisy versions of a dataset, paired with an initializer model for each EBM. At each noise level, the two models are jointly estimated within a cooperative training framework: samples from the initializer serve as starting points that are refined by a few MCMC sampling steps from the EBM. The EBM is then optimized by maximizing recovery likelihood, while the initializer model is optimized by learning from the difference between the refined samples and the initial samples. In addition, we made several practical designs for EBM training to further improve the sample quality. Combining these advances, our approach significantly boost the generation performance compared to existing EBM methods on CIFAR-10 and ImageNet datasets. We also demonstrate the effectiveness of our models for several downstream tasks, including classifier-free guided generation, compositional generation, image inpainting and out-of-distribution detection.
Read more4/19/2024
0
Maximum Entropy Inverse Reinforcement Learning of Diffusion Models with Energy-Based Models
Sangwoong Yoon, Himchan Hwang, Dohyun Kwon, Yung-Kyun Noh, Frank C. Park
We present a maximum entropy inverse reinforcement learning (IRL) approach for improving the sample quality of diffusion generative models, especially when the number of generation time steps is small. Similar to how IRL trains a policy based on the reward function learned from expert demonstrations, we train (or fine-tune) a diffusion model using the log probability density estimated from training data. Since we employ an energy-based model (EBM) to represent the log density, our approach boils down to the joint training of a diffusion model and an EBM. Our IRL formulation, named Diffusion by Maximum Entropy IRL (DxMI), is a minimax problem that reaches equilibrium when both models converge to the data distribution. The entropy maximization plays a key role in DxMI, facilitating the exploration of the diffusion model and ensuring the convergence of the EBM. We also propose Diffusion by Dynamic Programming (DxDP), a novel reinforcement learning algorithm for diffusion models, as a subroutine in DxMI. DxDP makes the diffusion model update in DxMI efficient by transforming the original problem into an optimal control formulation where value functions replace back-propagation in time. Our empirical studies show that diffusion models fine-tuned using DxMI can generate high-quality samples in as few as 4 and 10 steps. Additionally, DxMI enables the training of an EBM without MCMC, stabilizing EBM training dynamics and enhancing anomaly detection performance.
Read more7/2/2024

0
Improving Adversarial Energy-Based Model via Diffusion Process
Cong Geng, Tian Han, Peng-Tao Jiang, Hao Zhang, Jinwei Chen, S{o}ren Hauberg, Bo Li
Generative models have shown strong generation ability while efficient likelihood estimation is less explored. Energy-based models~(EBMs) define a flexible energy function to parameterize unnormalized densities efficiently but are notorious for being difficult to train. Adversarial EBMs introduce a generator to form a minimax training game to avoid expensive MCMC sampling used in traditional EBMs, but a noticeable gap between adversarial EBMs and other strong generative models still exists. Inspired by diffusion-based models, we embedded EBMs into each denoising step to split a long-generated process into several smaller steps. Besides, we employ a symmetric Jeffrey divergence and introduce a variational posterior distribution for the generator's training to address the main challenges that exist in adversarial EBMs. Our experiments show significant improvement in generation compared to existing adversarial EBMs, while also providing a useful energy function for efficient density estimation.
Read more6/11/2024
👀
0
Learning Latent Space Hierarchical EBM Diffusion Models
Jiali Cui, Tian Han
This work studies the learning problem of the energy-based prior model and the multi-layer generator model. The multi-layer generator model, which contains multiple layers of latent variables organized in a top-down hierarchical structure, typically assumes the Gaussian prior model. Such a prior model can be limited in modelling expressivity, which results in a gap between the generator posterior and the prior model, known as the prior hole problem. Recent works have explored learning the energy-based (EBM) prior model as a second-stage, complementary model to bridge the gap. However, the EBM defined on a multi-layer latent space can be highly multi-modal, which makes sampling from such marginal EBM prior challenging in practice, resulting in ineffectively learned EBM. To tackle the challenge, we propose to leverage the diffusion probabilistic scheme to mitigate the burden of EBM sampling and thus facilitate EBM learning. Our extensive experiments demonstrate a superior performance of our diffusion-learned EBM prior on various challenging tasks.
Read more5/29/2024