mCoT: Multilingual Instruction Tuning for Reasoning Consistency in Language Models
2406.02301
0
0

Abstract
Large language models (LLMs) with Chain-of-thought (CoT) have recently emerged as a powerful technique for eliciting reasoning to improve various downstream tasks. As most research mainly focuses on English, with few explorations in a multilingual context, the question of how reliable this reasoning capability is in different languages is still open. To address it directly, we study multilingual reasoning consistency across multiple languages, using popular open-source LLMs. First, we compile the first large-scale multilingual math reasoning dataset, mCoT-MATH, covering eleven diverse languages. Then, we introduce multilingual CoT instruction tuning to boost reasoning capability across languages, thereby improving model consistency. While existing LLMs show substantial variation across the languages we consider, and especially low performance for lesser resourced languages, our 7B parameter model mCoT achieves impressive consistency across languages, and superior or comparable performance to close- and open-source models even of much larger sizes.
Create account to get full access
Overview
- This paper explores a technique called "Smooth Reward Tuning" to improve the reasoning capabilities of large language models.
- The researchers find that applying this technique can lead to better performance on tasks that require multi-step reasoning and chain-of-thought processes.
- The paper builds on previous work on chain-of-thought reasoning in language models, multi-step reasoning across languages, and maintaining internal consistency in chain-of-thought reasoning.
Plain English Explanation
Large language models like GPT-3 have become remarkably adept at tasks like generating human-like text, answering questions, and even engaging in basic reasoning. However, these models can struggle with more complex, multi-step reasoning problems that require chain-of-thought processes.
The researchers in this paper introduce a technique called "Smooth Reward Tuning" to address this limitation. The key idea is to train the language model not just to produce the right final answer, but to generate a smooth, coherent chain of reasoning steps that lead to that answer.
Imagine you asked a language model to solve a complex math problem. A traditional model might just spit out the final solution, without showing its work. In contrast, the "Smooth Reward Tuning" approach encourages the model to walk through the problem step-by-step, explaining its thinking in a clear and logical way.
The researchers find that this technique leads to significant improvements in the model's ability to reason about complex, multi-step problems across a variety of domains. It helps the model maintain internal consistency in its chain-of-thought reasoning, rather than jumping between unrelated ideas.
Overall, this research represents an important step forward in making large language models more reliable and trustworthy for real-world applications that require robust reasoning capabilities.
Technical Explanation
The key innovation in this paper is the "Smooth Reward Tuning" technique, which the researchers apply to fine-tune large language models like GPT-3 for improved reasoning abilities.
The core idea is to modify the training objective to not just reward the model for producing the correct final answer, but to also encourage it to generate a smooth, coherent chain of reasoning steps that lead to that answer. This is achieved by introducing a "smoothness" term in the loss function, which penalizes abrupt transitions or jumps between different steps in the reasoning process.
The researchers evaluate this approach on a range of reasoning-focused benchmarks, including multi-step math reasoning, logical inference, and commonsense reasoning. They find that models trained with Smooth Reward Tuning significantly outperform their baseline counterparts, particularly on tasks that require chained, multi-step reasoning.
The authors also provide insights into the mechanisms behind this performance boost. They show that Smooth Reward Tuning leads to more internally consistent reasoning, with the model maintaining a coherent train of thought throughout the problem-solving process.
Critical Analysis
While the Smooth Reward Tuning technique presented in this paper is a promising step forward, there are a few important caveats and limitations to consider:
-
Generalization Challenges: The researchers primarily evaluate their approach on synthetic or curated benchmarks. It remains to be seen how well these models would perform on more realistic, open-ended reasoning tasks encountered in the real world.
-
Computational Overhead: Incorporating the "smoothness" term into the training objective adds additional computational complexity and training time, which could be a barrier for practical deployment.
-
Interpretability Limitations: The paper does not provide much insight into the internal decision-making processes of the Smooth Reward Tuning models. Improving the interpretability of these systems would be an important area for future research.
-
Potential Biases: As with any machine learning model, there are concerns about the models learning and perpetuating societal biases present in the training data. Careful evaluation and mitigation of these biases would be crucial.
Despite these limitations, this work represents an important advance in the field of large language model reasoning, and the Smooth Reward Tuning technique could serve as a valuable building block for developing more reliable and trustworthy AI systems.
Conclusion
This paper introduces a novel "Smooth Reward Tuning" technique that significantly improves the reasoning capabilities of large language models. By encouraging the models to generate smooth, coherent chains of reasoning steps, the researchers are able to achieve better performance on a variety of multi-step reasoning tasks.
The findings of this work contribute to a growing body of research aimed at enhancing the reasoning abilities of language models, moving them closer to the goal of human-level intelligence. While challenges remain, this paper represents an important step forward in the quest to build AI systems that can engage in robust, trustworthy reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, Alex Smola
0
0
Large language models (LLMs) have shown impressive performance on complex reasoning by leveraging chain-of-thought (CoT) prompting to generate intermediate reasoning chains as the rationale to infer the answer. However, existing CoT studies have primarily focused on the language modality. We propose Multimodal-CoT that incorporates language (text) and vision (images) modalities into a two-stage framework that separates rationale generation and answer inference. In this way, answer inference can leverage better generated rationales that are based on multimodal information. Experimental results on ScienceQA and A-OKVQA benchmark datasets show the effectiveness of our proposed approach. With Multimodal-CoT, our model under 1 billion parameters achieves state-of-the-art performance on the ScienceQA benchmark. Our analysis indicates that Multimodal-CoT offers the advantages of mitigating hallucination and enhancing convergence speed. Code is publicly available at https://github.com/amazon-science/mm-cot.
5/21/2024
On the Hardness of Faithful Chain-of-Thought Reasoning in Large Language Models
Sree Harsha Tanneru, Dan Ley, Chirag Agarwal, Himabindu Lakkaraju
0
0
As Large Language Models (LLMs) are increasingly being employed in real-world applications in critical domains such as healthcare, it is important to ensure that the Chain-of-Thought (CoT) reasoning generated by these models faithfully captures their underlying behavior. While LLMs are known to generate CoT reasoning that is appealing to humans, prior studies have shown that these explanations do not accurately reflect the actual behavior of the underlying LLMs. In this work, we explore the promise of three broad approaches commonly employed to steer the behavior of LLMs to enhance the faithfulness of the CoT reasoning generated by LLMs: in-context learning, fine-tuning, and activation editing. Specifically, we introduce novel strategies for in-context learning, fine-tuning, and activation editing aimed at improving the faithfulness of the CoT reasoning. We then carry out extensive empirical analyses with multiple benchmark datasets to explore the promise of these strategies. Our analyses indicate that these strategies offer limited success in improving the faithfulness of the CoT reasoning, with only slight performance enhancements in controlled scenarios. Activation editing demonstrated minimal success, while fine-tuning and in-context learning achieved marginal improvements that failed to generalize across diverse reasoning and truthful question-answering benchmarks. In summary, our work underscores the inherent difficulty in eliciting faithful CoT reasoning from LLMs, suggesting that the current array of approaches may not be sufficient to address this complex challenge.
7/2/2024
📊
Empowering Multi-step Reasoning across Languages via Tree-of-Thoughts
Leonardo Ranaldi, Giulia Pucci, Federico Ranaldi, Elena Sofia Ruzzetti, Fabio Massimo Zanzotto
0
0
Reasoning methods, best exemplified by the well-known Chain-of-Thought (CoT), empower the reasoning abilities of Large Language Models (LLMs) by eliciting them to solve complex tasks in a step-by-step manner. Although they are achieving significant success, the ability to deliver multi-step reasoning remains limited to English because of the imbalance in the distribution of pre-training data, which makes other languages a barrier. In this paper, we propose Cross-lingual Tree-of-Thoughts (Cross-ToT), a method for aligning Cross-lingual CoT reasoning across languages. The proposed method, through a self-consistent cross-lingual prompting mechanism inspired by the Tree-of-Thoughts approach, provides multi-step reasoning paths in different languages that, during the steps, lead to the final solution. Experimental evaluations show that our method significantly outperforms existing prompting methods by reducing the number of interactions and achieving state-of-the-art performance.
6/24/2024
Towards Faithful Chain-of-Thought: Large Language Models are Bridging Reasoners
Jiachun Li, Pengfei Cao, Yubo Chen, Kang Liu, Jun Zhao
0
0
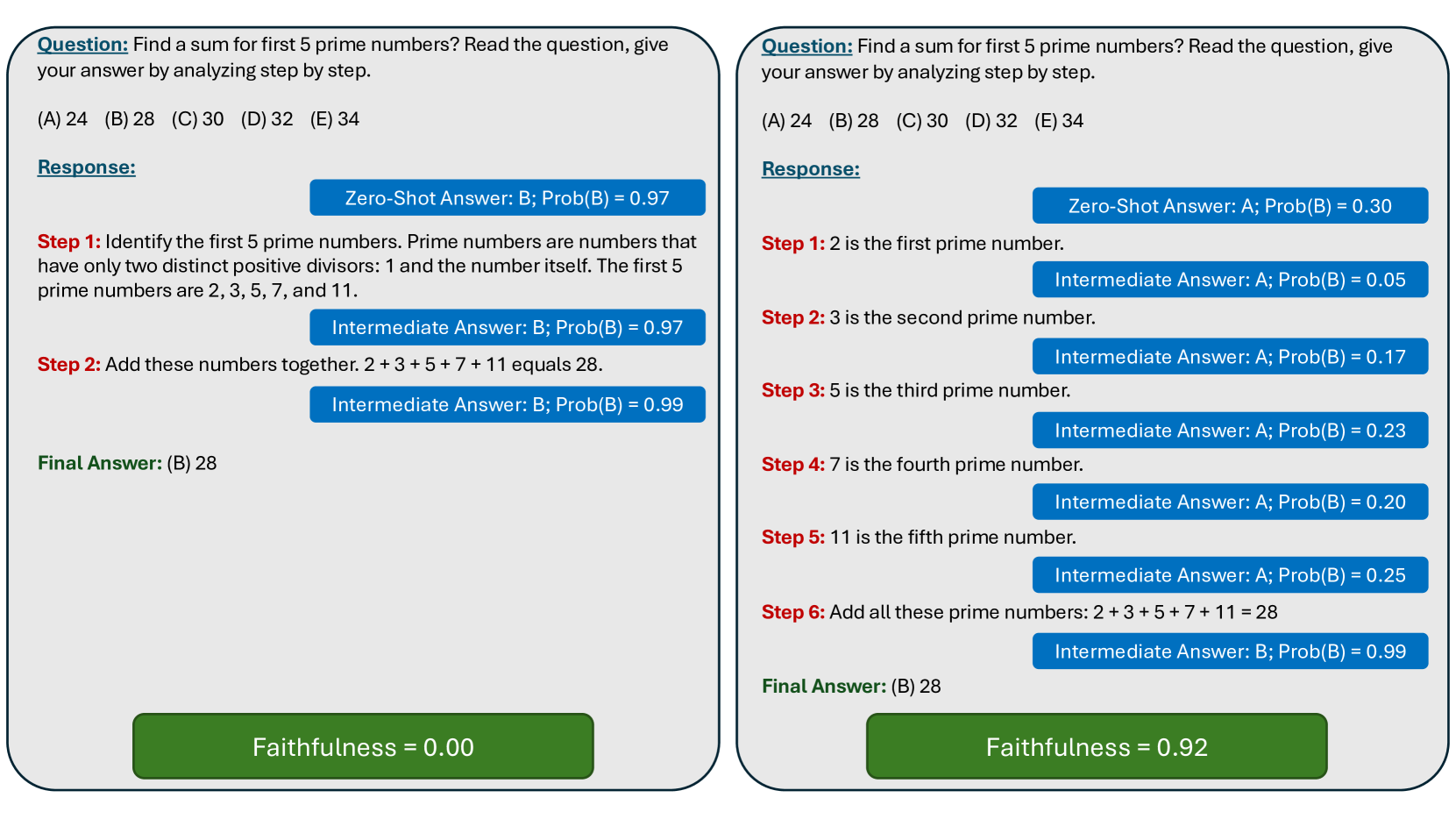
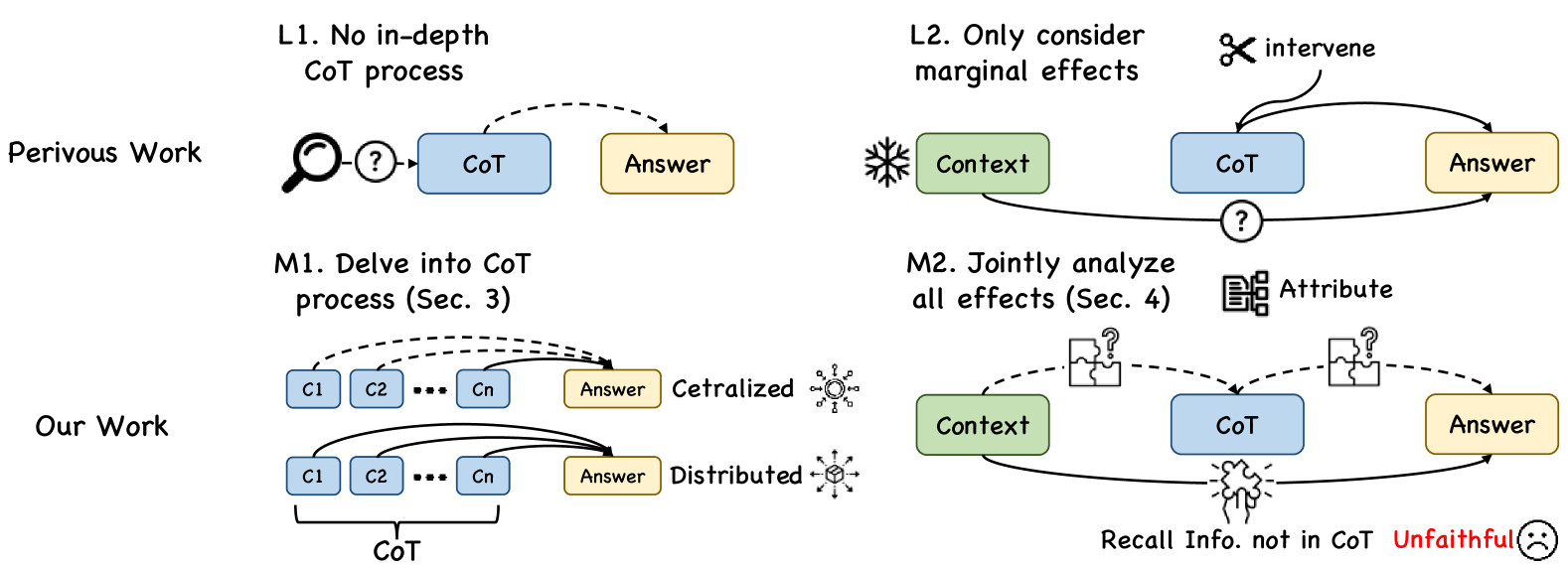
Large language models (LLMs) suffer from serious unfaithful chain-of-thought (CoT) issues. Previous work attempts to measure and explain it but lacks in-depth analysis within CoTs and does not consider the interactions among all reasoning components jointly. In this paper, we first study the CoT faithfulness issue at the granularity of CoT steps, identify two reasoning paradigms: centralized reasoning and distributed reasoning, and find their relationship with faithfulness. Subsequently, we conduct a joint analysis of the causal relevance among the context, CoT, and answer during reasoning. The result proves that, when the LLM predicts answers, it can recall correct information missing in the CoT from the context, leading to unfaithfulness issues. Finally, we propose the inferential bridging method to mitigate this issue, in which we use the attribution method to recall information as hints for CoT generation and filter out noisy CoTs based on their semantic consistency and attribution scores. Extensive experiments demonstrate that our approach effectively alleviates the unfaithful CoT problem.
5/30/2024