Calibrating Reasoning in Language Models with Internal Consistency
2405.18711
0
0
Abstract
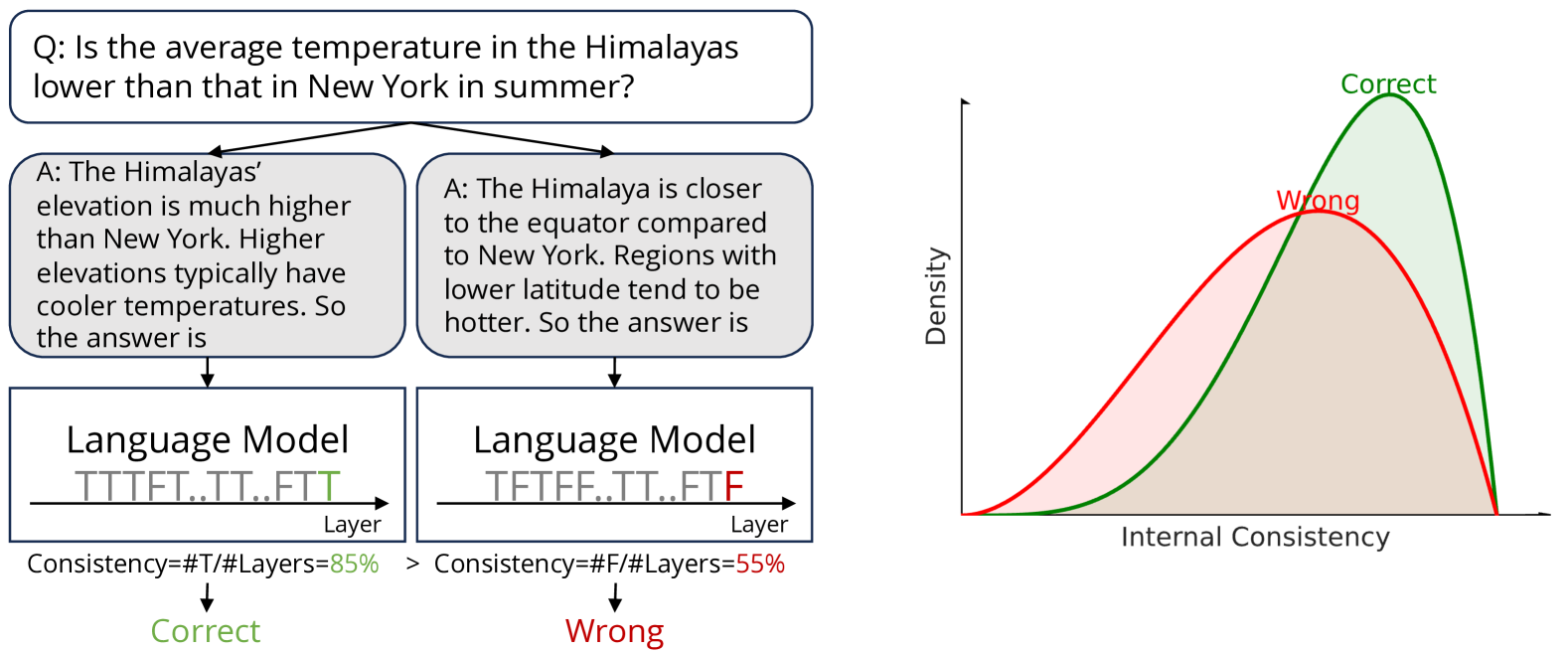
Large language models (LLMs) have demonstrated impressive capabilities in various reasoning tasks, aided by techniques like chain-of-thought (CoT) prompting that elicits verbalized reasoning. However, LLMs often generate text with obvious mistakes and contradictions, raising doubts about their ability to robustly process and utilize generated rationales. In this work, we investigate CoT reasoning in LLMs through the lens of internal representations, focusing on how these representations are influenced by generated rationales. Our preliminary analysis reveals that while generated rationales improve answer accuracy, inconsistencies emerge between the model's internal representations in middle layers and those in final layers, potentially undermining the reliability of their reasoning processes. To address this, we propose internal consistency as a measure of the model's confidence by examining the agreement of latent predictions decoded from intermediate layers. Extensive empirical studies across different models and datasets demonstrate that internal consistency effectively distinguishes between correct and incorrect reasoning paths. Motivated by this, we propose a new approach to calibrate CoT reasoning by up-weighting reasoning paths with high internal consistency, resulting in a significant boost in reasoning performance. Further analysis uncovers distinct patterns in attention and feed-forward modules across layers, providing insights into the emergence of internal inconsistency. In summary, our results demonstrate the potential of using internal representations for self-evaluation of LLMs.
Create account to get full access
Overview
- This paper explores methods for calibrating the reasoning capabilities of large language models to improve their internal consistency.
- The researchers propose using prompts that require step-by-step reasoning to evaluate and improve the models' ability to maintain logical consistency throughout a multi-step process.
- The findings have implications for developing more trustworthy and transparent language models that can engage in faithful and reliable reasoning.
Plain English Explanation
Large language models, like GPT-3, have become incredibly powerful at generating human-like text. However, these models can sometimes produce responses that are logically inconsistent or nonsensical. This is because they don't have a strong grasp of step-by-step reasoning and can lose track of their own logical flow.
The researchers in this paper wanted to find a way to "calibrate" or adjust the language models to be more consistent in their reasoning. To do this, they developed prompts that required the models to walk through a multi-step logical process. By evaluating how well the models maintained coherence and internal consistency when answering these prompts, the researchers were able to identify areas for improvement.
The key insight is that prompts forcing models to engage in chained reasoning expose their weaknesses in a way that simpler prompts do not. This allows developers to target specific shortcomings and refine the models to become more reliable and trustworthy when tasked with complex reasoning.
Overall, this work represents an important step towards building language AI systems that can think through problems in a step-by-step, logically coherent way - just like humans do. By focusing on internal consistency, the researchers hope to create language models that are more transparent and faithful in their reasoning.
Technical Explanation
The paper begins by outlining the challenge of ensuring large language models (LLMs) maintain logical consistency during multi-step reasoning tasks. The authors note that while LLMs excel at natural language generation, they can struggle to uphold internal coherence when faced with prompts requiring chained logical inferences.
To address this, the researchers propose a framework for "calibrating" LLMs to improve their reasoning capabilities. The core idea is to develop prompts that force the models to engage in step-by-step logical processing, and then evaluate the internal consistency of the responses. By identifying areas where the models fail to maintain coherence, the researchers can target specific weaknesses and refine the models accordingly.
The paper outlines several types of prompts designed to probe the models' reasoning abilities, including:
- Multi-step math problems
- Chain-of-thought tasks that build logical arguments
- Open-ended reasoning challenges that require tracking context over multiple steps
The researchers then apply these prompts to evaluate the performance of various LLMs, including GPT-3, GPT-J, and Chinchilla. They find that the models exhibit significant inconsistencies when tackling the more complex, multi-step reasoning tasks, despite performing well on simpler prompts.
Based on these findings, the authors propose techniques for fine-tuning the LLMs to improve their internal consistency. This includes methods like temperature scaling, prompt engineering, and targeted dataset curation. Through iterative evaluation and refinement, the goal is to develop language models that can reliably engage in transparent, step-by-step reasoning.
Critical Analysis
The researchers acknowledge several limitations in their work. First, the prompts used to evaluate the models' reasoning abilities are relatively narrow in scope. While effective at exposing consistency issues, the prompts may not fully capture the breadth of real-world reasoning challenges language models will face.
Additionally, the paper does not delve deeply into the underlying causes of the models' inconsistent behavior. While the authors propose methods for improving performance, a more thorough investigation into the fundamental flaws or biases in the models' training or architecture could lead to more robust solutions.
There is also an open question around how to effectively measure and benchmark the reasoning capabilities of language models. The prompts used in this paper provide a useful starting point, but developing a comprehensive, standardized framework for evaluating reasoning skills remains an area for further research.
Overall, this paper represents an important step towards building more trustworthy and transparent language models. By focusing on internal consistency, the researchers have identified a critical weakness that must be addressed to unlock the full potential of large language models in high-stakes applications. However, continued innovation and rigorous testing will be necessary to realize this goal.
Conclusion
This paper introduces a novel approach for calibrating the reasoning capabilities of large language models to improve their internal consistency and transparency. By developing prompts that require step-by-step logical processing, the researchers were able to expose significant weaknesses in the models' ability to maintain coherence during complex reasoning tasks.
The findings suggest that while current LLMs excel at natural language generation, they still struggle to engage in the kind of faithful, reliable reasoning that humans rely on. To address this, the authors propose techniques for fine-tuning and refining the models to better uphold logical consistency.
Ultimately, this work represents an important step towards developing language AI systems that can be trusted to provide transparent and trustworthy outputs, even when tackling complex, multi-step problems. As large language models become increasingly integrated into high-stakes applications, ensuring their reasoning capabilities are properly calibrated will be crucial for maintaining public trust and realizing the full societal benefits of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Evaluating Consistency and Reasoning Capabilities of Large Language Models
Yash Saxena, Sarthak Chopra, Arunendra Mani Tripathi
0
0
Large Language Models (LLMs) are extensively used today across various sectors, including academia, research, business, and finance, for tasks such as text generation, summarization, and translation. Despite their widespread adoption, these models often produce incorrect and misleading information, exhibiting a tendency to hallucinate. This behavior can be attributed to several factors, with consistency and reasoning capabilities being significant contributors. LLMs frequently lack the ability to generate explanations and engage in coherent reasoning, leading to inaccurate responses. Moreover, they exhibit inconsistencies in their outputs. This paper aims to evaluate and compare the consistency and reasoning capabilities of both public and proprietary LLMs. The experiments utilize the Boolq dataset as the ground truth, comprising questions, answers, and corresponding explanations. Queries from the dataset are presented as prompts to the LLMs, and the generated responses are evaluated against the ground truth answers. Additionally, explanations are generated to assess the models' reasoning abilities. Consistency is evaluated by repeatedly presenting the same query to the models and observing for variations in their responses. For measuring reasoning capabilities, the generated explanations are compared to the ground truth explanations using metrics such as BERT, BLEU, and F-1 scores. The findings reveal that proprietary models generally outperform public models in terms of both consistency and reasoning capabilities. However, even when presented with basic general knowledge questions, none of the models achieved a score of 90% in both consistency and reasoning. This study underscores the direct correlation between consistency and reasoning abilities in LLMs and highlights the inherent reasoning challenges present in current language models.
4/26/2024
Towards Faithful Chain-of-Thought: Large Language Models are Bridging Reasoners
Jiachun Li, Pengfei Cao, Yubo Chen, Kang Liu, Jun Zhao
0
0
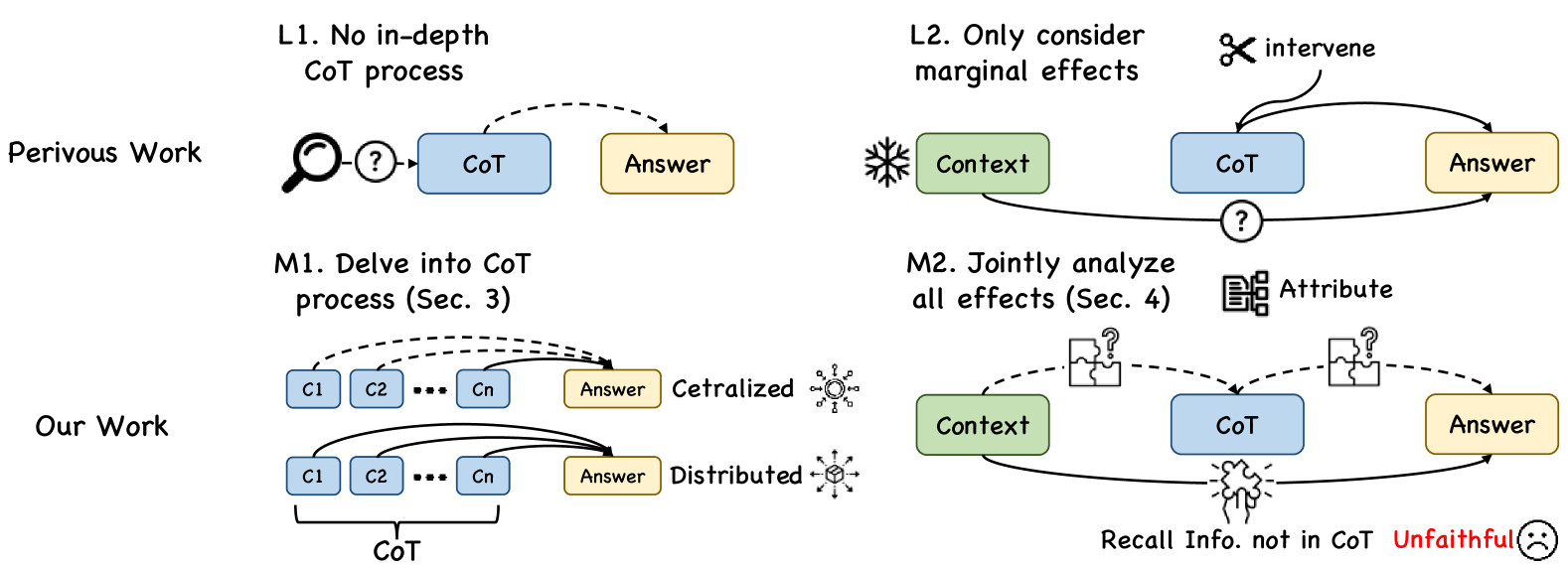
Large language models (LLMs) suffer from serious unfaithful chain-of-thought (CoT) issues. Previous work attempts to measure and explain it but lacks in-depth analysis within CoTs and does not consider the interactions among all reasoning components jointly. In this paper, we first study the CoT faithfulness issue at the granularity of CoT steps, identify two reasoning paradigms: centralized reasoning and distributed reasoning, and find their relationship with faithfulness. Subsequently, we conduct a joint analysis of the causal relevance among the context, CoT, and answer during reasoning. The result proves that, when the LLM predicts answers, it can recall correct information missing in the CoT from the context, leading to unfaithfulness issues. Finally, we propose the inferential bridging method to mitigate this issue, in which we use the attribution method to recall information as hints for CoT generation and filter out noisy CoTs based on their semantic consistency and attribution scores. Extensive experiments demonstrate that our approach effectively alleviates the unfaithful CoT problem.
5/30/2024

mCoT: Multilingual Instruction Tuning for Reasoning Consistency in Language Models
Huiyuan Lai, Malvina Nissim
0
0
Large language models (LLMs) with Chain-of-thought (CoT) have recently emerged as a powerful technique for eliciting reasoning to improve various downstream tasks. As most research mainly focuses on English, with few explorations in a multilingual context, the question of how reliable this reasoning capability is in different languages is still open. To address it directly, we study multilingual reasoning consistency across multiple languages, using popular open-source LLMs. First, we compile the first large-scale multilingual math reasoning dataset, mCoT-MATH, covering eleven diverse languages. Then, we introduce multilingual CoT instruction tuning to boost reasoning capability across languages, thereby improving model consistency. While existing LLMs show substantial variation across the languages we consider, and especially low performance for lesser resourced languages, our 7B parameter model mCoT achieves impressive consistency across languages, and superior or comparable performance to close- and open-source models even of much larger sizes.
6/5/2024
Towards Logically Consistent Language Models via Probabilistic Reasoning
Diego Calanzone, Stefano Teso, Antonio Vergari
0
0
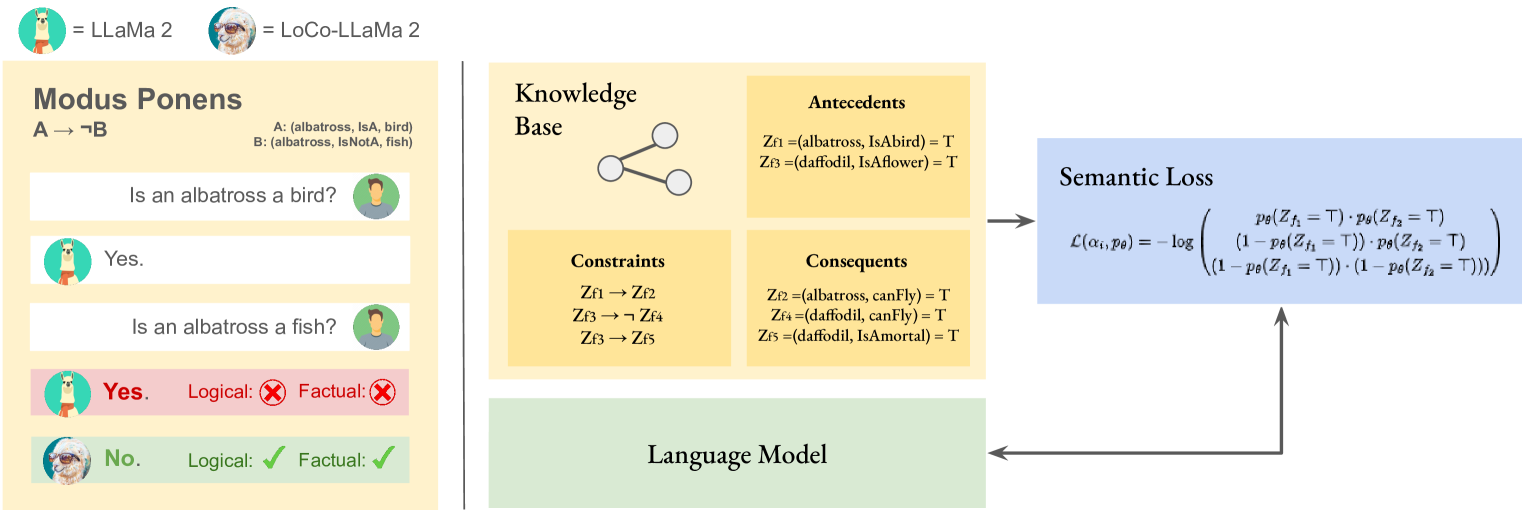
Large language models (LLMs) are a promising venue for natural language understanding and generation tasks. However, current LLMs are far from reliable: they are prone to generate non-factual information and, more crucially, to contradict themselves when prompted to reason about beliefs of the world. These problems are currently addressed with large scale fine-tuning or by delegating consistent reasoning to external tools. In this work, we strive for a middle ground and introduce a training objective based on principled probabilistic reasoning that teaches a LLM to be consistent with external knowledge in the form of a set of facts and rules. Fine-tuning with our loss on a limited set of facts enables our LLMs to be more logically consistent than previous baselines and allows them to extrapolate to unseen but semantically similar factual knowledge more systematically.
4/22/2024