MCPNet: An Interpretable Classifier via Multi-Level Concept Prototypes
2404.08968
0
0

Abstract
Recent advancements in post-hoc and inherently interpretable methods have markedly enhanced the explanations of black box classifier models. These methods operate either through post-analysis or by integrating concept learning during model training. Although being effective in bridging the semantic gap between a model's latent space and human interpretation, these explanation methods only partially reveal the model's decision-making process. The outcome is typically limited to high-level semantics derived from the last feature map. We argue that the explanations lacking insights into the decision processes at low and mid-level features are neither fully faithful nor useful. Addressing this gap, we introduce the Multi-Level Concept Prototypes Classifier (MCPNet), an inherently interpretable model. MCPNet autonomously learns meaningful concept prototypes across multiple feature map levels using Centered Kernel Alignment (CKA) loss and an energy-based weighted PCA mechanism, and it does so without reliance on predefined concept labels. Further, we propose a novel classifier paradigm that learns and aligns multi-level concept prototype distributions for classification purposes via Class-aware Concept Distribution (CCD) loss. Our experiments reveal that our proposed MCPNet while being adaptable to various model architectures, offers comprehensive multi-level explanations while maintaining classification accuracy. Additionally, its concept distribution-based classification approach shows improved generalization capabilities in few-shot classification scenarios.
Create account to get full access
Overview
- This paper introduces MCPNet, a new interpretable machine learning classifier that uses multi-level concept prototypes.
- MCPNet aims to provide model transparency and explanations for its predictions, making it more understandable to users.
- The model learns a set of high-level and low-level concept prototypes that are used to classify input data.
- Experiments on several benchmark datasets show that MCPNet achieves competitive performance while providing meaningful explanations for its decisions.
Plain English Explanation
MCPNet is a new type of machine learning model that tries to be more transparent and understandable than typical "black box" models. Instead of just producing a classification output, MCPNet also provides an explanation for why it made that decision.
The key idea behind MCPNet is that it learns a set of "concept prototypes" - these are representative examples of different high-level and low-level concepts that the model has identified as being important for making predictions. When classifying a new input, MCPNet compares that input to its stored concept prototypes and uses the similarities to explain its reasoning.
For example, if MCPNet is classifying an image of a dog, it might explain its decision by saying "this image is similar to my prototypes for 'four-legged animal', 'furry texture', and 'pointy ears', which are all concepts strongly associated with dogs." This kind of explanation can help users understand and trust the model's decisions, rather than treating it as a mysterious black box.
The researchers tested MCPNet on several standard machine learning datasets and found that it performed competitively with other state-of-the-art models, while also providing these useful interpretations. This suggests that MCPNet could be a valuable tool for applications where model transparency and explainability are important, such as medical diagnosis or financial risk assessment.
Technical Explanation
The core of MCPNet is its use of a multi-level concept prototype learning approach. The model first learns a set of low-level concept prototypes that capture fine-grained visual or other features in the input data. It then learns a set of higher-level concept prototypes that aggregate and represent combinations of the low-level concepts.
During classification, MCPNet compares the input to both the low-level and high-level concept prototypes and uses the similarity scores to make its final prediction. Importantly, it also uses these similarity scores to generate natural language explanations for its decision-making process.
For example, if classifying an image of a dog, MCPNet might explain that the input is similar to prototypes for "four-legged animal", "furry texture", and "pointy ears", and that these low-level concept matches contribute to its final dog classification.
The researchers evaluate MCPNet on several standard image and text classification benchmarks, including CIFAR-10, CUB-200-2011, and AG's News. They show that MCPNet achieves comparable or even state-of-the-art performance compared to other interpretable models like MaproToNet and Understanding Multimodal Deep Neural Networks, while also providing meaningful natural language explanations for its predictions.
Critical Analysis
The paper provides a thorough evaluation of MCPNet and demonstrates its effectiveness as an interpretable classifier. However, a few potential limitations or areas for future work are worth considering:
-
The concept prototype learning process relies on manual annotations of the training data, which may limit the scalability of the approach. Exploring ways to learn meaningful concepts in an unsupervised or semi-supervised manner could make MCPNet more widely applicable.
-
While the natural language explanations provided by MCPNet are intuitive, it's unclear how well they align with human reasoning and whether users will find them truly satisfactory. Evaluating the quality and usefulness of these explanations from an end-user perspective would be an important next step.
-
The paper only considers single-label classification tasks. Extending MCPNet to handle more complex, multi-label problems, as explored in ProbMCL, could further demonstrate its versatility and real-world applicability.
Overall, MCPNet represents an interesting and potentially impactful approach to interpretable machine learning. While the current evaluation is promising, continued research and user studies will be important to fully understand the model's strengths, limitations, and practical implications.
Conclusion
The MCPNet model proposed in this paper introduces a novel approach to building interpretable machine learning classifiers. By learning multi-level concept prototypes and using them to generate natural language explanations, MCPNet aims to provide both high performance and meaningful transparency.
The experimental results demonstrate that MCPNet can achieve competitive accuracy on standard benchmarks while offering explainable predictions. This suggests that the model could be a valuable tool in applications where model interpretability is crucial, such as medical diagnosis, financial risk assessment, or safety-critical systems.
Further research is needed to address some of the potential limitations, such as scaling the concept learning process and fully evaluating the quality and usefulness of the provided explanations. However, the core ideas behind MCPNet represent an important step towards building more trustworthy and user-friendly AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
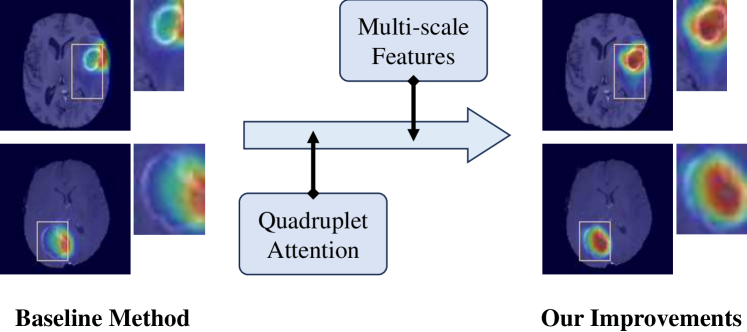
MAProtoNet: A Multi-scale Attentive Interpretable Prototypical Part Network for 3D Magnetic Resonance Imaging Brain Tumor Classification
Binghua Li, Jie Mao, Zhe Sun, Chao Li, Qibin Zhao, Toshihisa Tanaka
0
0
Automated diagnosis with artificial intelligence has emerged as a promising area in the realm of medical imaging, while the interpretability of the introduced deep neural networks still remains an urgent concern. Although contemporary works, such as XProtoNet and MProtoNet, has sought to design interpretable prediction models for the issue, the localization precision of their resulting attribution maps can be further improved. To this end, we propose a Multi-scale Attentive Prototypical part Network, termed MAProtoNet, to provide more precise maps for attribution. Specifically, we introduce a concise multi-scale module to merge attentive features from quadruplet attention layers, and produces attribution maps. The proposed quadruplet attention layers can enhance the existing online class activation mapping loss via capturing interactions between the spatial and channel dimension, while the multi-scale module then fuses both fine-grained and coarse-grained information for precise maps generation. We also apply a novel multi-scale mapping loss for supervision on the proposed multi-scale module. Compared to existing interpretable prototypical part networks in medical imaging, MAProtoNet can achieve state-of-the-art performance in localization on brain tumor segmentation (BraTS) datasets, resulting in approximately 4% overall improvement on activation precision score (with a best score of 85.8%), without using additional annotated labels of segmentation. Our code will be released in https://github.com/TUAT-Novice/maprotonet.
4/16/2024
👀
CoProNN: Concept-based Prototypical Nearest Neighbors for Explaining Vision Models
Teodor Chiaburu, Frank Hau{ss}er, Felix Bie{ss}mann
0
0
Mounting evidence in explainability for artificial intelligence (XAI) research suggests that good explanations should be tailored to individual tasks and should relate to concepts relevant to the task. However, building task specific explanations is time consuming and requires domain expertise which can be difficult to integrate into generic XAI methods. A promising approach towards designing useful task specific explanations with domain experts is based on compositionality of semantic concepts. Here, we present a novel approach that enables domain experts to quickly create concept-based explanations for computer vision tasks intuitively via natural language. Leveraging recent progress in deep generative methods we propose to generate visual concept-based prototypes via text-to-image methods. These prototypes are then used to explain predictions of computer vision models via a simple k-Nearest-Neighbors routine. The modular design of CoProNN is simple to implement, it is straightforward to adapt to novel tasks and allows for replacing the classification and text-to-image models as more powerful models are released. The approach can be evaluated offline against the ground-truth of predefined prototypes that can be easily communicated also to domain experts as they are based on visual concepts. We show that our strategy competes very well with other concept-based XAI approaches on coarse grained image classification tasks and may even outperform those methods on more demanding fine grained tasks. We demonstrate the effectiveness of our method for human-machine collaboration settings in qualitative and quantitative user studies. All code and experimental data can be found in our GitHub $href{https://github.com/TeodorChiaburu/beexplainable}{repository}$.
4/24/2024
Understanding Multimodal Deep Neural Networks: A Concept Selection View
Chenming Shang, Hengyuan Zhang, Hao Wen, Yujiu Yang
0
0
The multimodal deep neural networks, represented by CLIP, have generated rich downstream applications owing to their excellent performance, thus making understanding the decision-making process of CLIP an essential research topic. Due to the complex structure and the massive pre-training data, it is often regarded as a black-box model that is too difficult to understand and interpret. Concept-based models map the black-box visual representations extracted by deep neural networks onto a set of human-understandable concepts and use the concepts to make predictions, enhancing the transparency of the decision-making process. However, these methods involve the datasets labeled with fine-grained attributes by expert knowledge, which incur high costs and introduce excessive human prior knowledge and bias. In this paper, we observe the long-tail distribution of concepts, based on which we propose a two-stage Concept Selection Model (CSM) to mine core concepts without introducing any human priors. The concept greedy rough selection algorithm is applied to extract head concepts, and then the concept mask fine selection method performs the extraction of core concepts. Experiments show that our approach achieves comparable performance to end-to-end black-box models, and human evaluation demonstrates that the concepts discovered by our method are interpretable and comprehensible for humans.
4/16/2024

InterpretCC: Intrinsic User-Centric Interpretability through Global Mixture of Experts
Vinitra Swamy, Syrielle Montariol, Julian Blackwell, Jibril Frej, Martin Jaggi, Tanja Kaser
0
0
Interpretability for neural networks is a trade-off between three key requirements: 1) faithfulness of the explanation (i.e., how perfectly it explains the prediction), 2) understandability of the explanation by humans, and 3) model performance. Most existing methods compromise one or more of these requirements; e.g., post-hoc approaches provide limited faithfulness, automatically identified feature masks compromise understandability, and intrinsically interpretable methods such as decision trees limit model performance. These shortcomings are unacceptable for sensitive applications such as education and healthcare, which require trustworthy explanations, actionable interpretations, and accurate predictions. In this work, we present InterpretCC (interpretable conditional computation), a family of interpretable-by-design neural networks that guarantee human-centric interpretability, while maintaining comparable performance to state-of-the-art models by adaptively and sparsely activating features before prediction. We extend this idea into an interpretable, global mixture-of-experts (MoE) model that allows humans to specify topics of interest, discretely separates the feature space for each data point into topical subnetworks, and adaptively and sparsely activates these topical subnetworks for prediction. We apply variations of the InterpretCC architecture for text, time series and tabular data across several real-world benchmarks, demonstrating comparable performance with non-interpretable baselines, outperforming interpretable-by-design baselines, and showing higher actionability and usefulness according to a user study.
5/30/2024