ProbMCL: Simple Probabilistic Contrastive Learning for Multi-label Visual Classification
2401.01448
0
1

Abstract
Multi-label image classification presents a challenging task in many domains, including computer vision and medical imaging. Recent advancements have introduced graph-based and transformer-based methods to improve performance and capture label dependencies. However, these methods often include complex modules that entail heavy computation and lack interpretability. In this paper, we propose Probabilistic Multi-label Contrastive Learning (ProbMCL), a novel framework to address these challenges in multi-label image classification tasks. Our simple yet effective approach employs supervised contrastive learning, in which samples that share enough labels with an anchor image based on a decision threshold are introduced as a positive set. This structure captures label dependencies by pulling positive pair embeddings together and pushing away negative samples that fall below the threshold. We enhance representation learning by incorporating a mixture density network into contrastive learning and generating Gaussian mixture distributions to explore the epistemic uncertainty of the feature encoder. We validate the effectiveness of our framework through experimentation with datasets from the computer vision and medical imaging domains. Our method outperforms the existing state-of-the-art methods while achieving a low computational footprint on both datasets. Visualization analyses also demonstrate that ProbMCL-learned classifiers maintain a meaningful semantic topology.
Create account to get full access
Overview
- This paper proposes a simple probabilistic contrastive learning (ProbMCL) framework for multi-label visual classification.
- ProbMCL aims to learn effective visual representations by contrasting images with similar and dissimilar label sets.
- The method is designed to be straightforward to implement and computationally efficient.
Plain English Explanation
ProbMCL is a new approach for training machine learning models to classify images with multiple labels, such as identifying multiple objects or attributes in a single image.
The key idea behind ProbMCL is to compare similar images (those with overlapping labels) and dissimilar images (those with different labels) during the training process. By emphasizing the differences between these two groups of images, the model can learn visual features that are predictive of the full set of labels for each image.
This "contrastive learning" technique is designed to be simple to implement and computationally efficient, making it practical for real-world applications. The authors show that ProbMCL can achieve strong performance on standard multi-label classification benchmarks, rivaling more complex state-of-the-art methods.
Technical Explanation
The ProbMCL framework consists of three key components:
-
Probabilistic Label Sampling: Instead of using the ground truth labels directly, ProbMCL samples probable label sets for each image based on the current model predictions. This introduces an element of uncertainty that the model must learn to resolve.
-
Contrastive Loss: The contrastive loss function encourages the model to push apart the representations of images with dissimilar label sets, while pulling together the representations of images with similar label sets. This helps the model learn visual features that are predictive of the full label set.
-
Regularized Optimization: ProbMCL employs a regularized optimization strategy that balances the contrastive loss with a standard multi-label cross-entropy loss. This ensures the model learns to accurately predict the individual labels while also capturing the relationships between them.
The authors evaluate ProbMCL on several multi-label image classification benchmarks, including MS-COCO, ADE20K, and Visual Genome. They show that ProbMCL outperforms or matches the performance of more complex state-of-the-art methods, while being simpler to implement and more computationally efficient.
Critical Analysis
The authors acknowledge several limitations of the ProbMCL approach. First, the probabilistic label sampling strategy may introduce noise and inconsistencies during training, which could negatively impact performance. Additionally, the method relies on a delicate balance between the contrastive loss and the standard multi-label loss, which may be challenging to tune in practice.
Another potential concern is that the ProbMCL framework, like other contrastive learning methods, may be susceptible to various biases present in the training data. This could lead to learned representations that perpetuate or amplify societal biases, which is an important area for further research in the field of positive-unlabeled contrastive learning.
Despite these limitations, the authors demonstrate that ProbMCL can achieve strong results on multi-label classification benchmarks, suggesting that the core ideas behind the method are promising. Further research may explore ways to improve the robustness and fairness of the approach, as well as investigate its applicability to other multi-modal or structured prediction tasks.
Conclusion
The ProbMCL framework offers a simple and efficient approach to multi-label visual classification, a task with important real-world applications. By leveraging probabilistic label sampling and contrastive learning, the method is able to capture the relationships between multiple labels in an image, outperforming or matching more complex state-of-the-art techniques.
While the approach has some limitations, the authors have demonstrated the potential of ProbMCL to serve as a practical and effective solution for multi-label image classification tasks. Further research in this direction may lead to even more robust and fair models, with broader implications for various visual understanding and reasoning applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Positive Label Is All You Need for Multi-Label Classification
Zhixiang Yuan, Kaixin Zhang, Tao Huang
0
0
Multi-label classification (MLC) faces challenges from label noise in training data due to annotating diverse semantic labels for each image. Current methods mainly target identifying and correcting label mistakes using trained MLC models, but still struggle with persistent noisy labels during training, resulting in imprecise recognition and reduced performance. Our paper addresses label noise in MLC by introducing a positive and unlabeled multi-label classification (PU-MLC) method. To counteract noisy labels, we directly discard negative labels, focusing on the abundance of negative labels and the origin of most noisy labels. PU-MLC employs positive-unlabeled learning, training the model with only positive labels and unlabeled data. The method incorporates adaptive re-balance factors and temperature coefficients in the loss function to address label distribution imbalance and prevent over-smoothing of probabilities during training. Additionally, we introduce a local-global convolution module to capture both local and global dependencies in the image without requiring backbone retraining. PU-MLC proves effective on MLC and MLC with partial labels (MLC-PL) tasks, demonstrating significant improvements on MS-COCO and PASCAL VOC datasets with fewer annotations. Code is available at: https://github.com/TAKELAMAG/PU-MLC.
4/17/2024
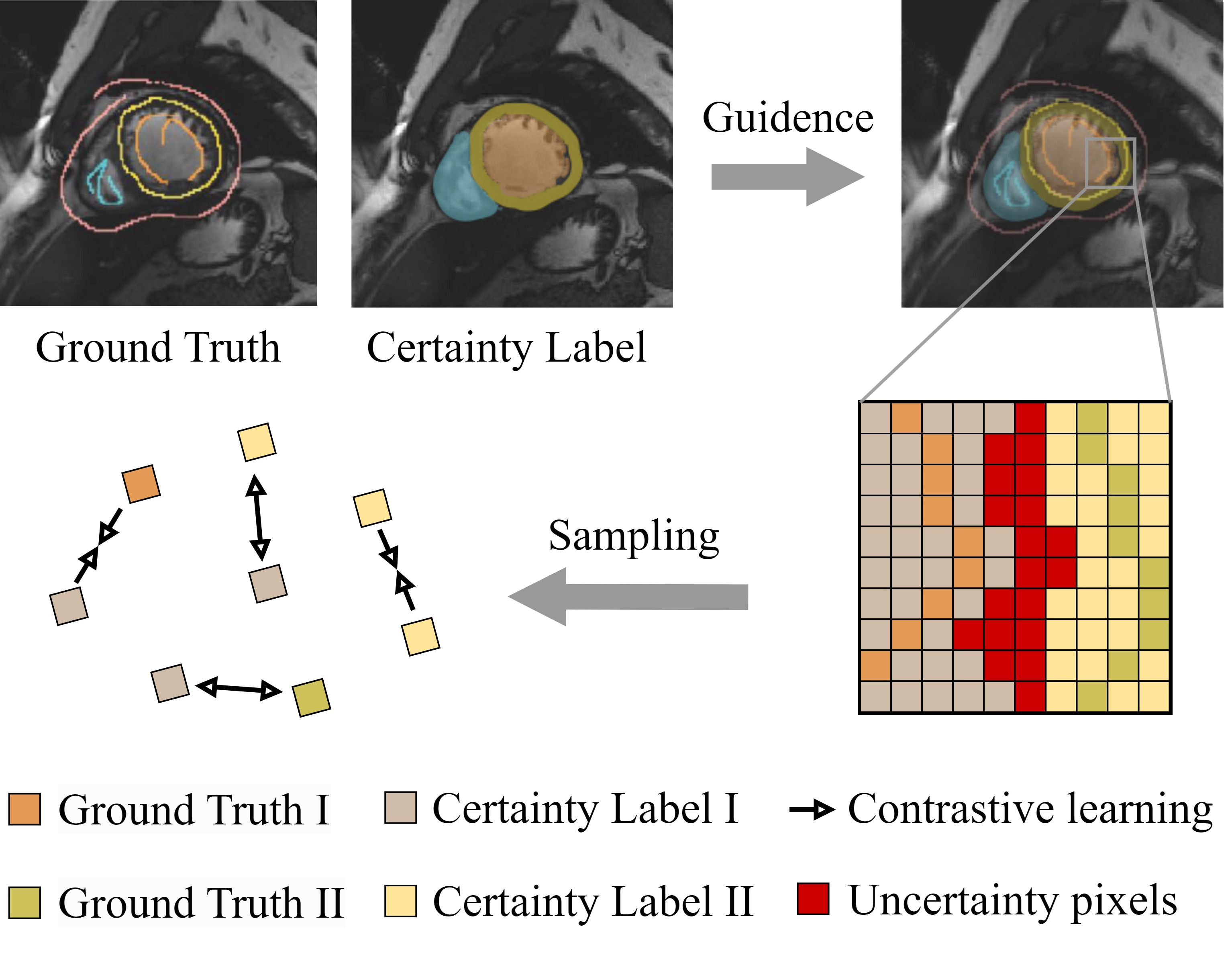
PCLMix: Weakly Supervised Medical Image Segmentation via Pixel-Level Contrastive Learning and Dynamic Mix Augmentation
Yu Lei, Haolun Luo, Lituan Wang, Zhenwei Zhang, Lei Zhang
0
0
In weakly supervised medical image segmentation, the absence of structural priors and the discreteness of class feature distribution present a challenge, i.e., how to accurately propagate supervision signals from local to global regions without excessively spreading them to other irrelevant regions? To address this, we propose a novel weakly supervised medical image segmentation framework named PCLMix, comprising dynamic mix augmentation, pixel-level contrastive learning, and consistency regularization strategies. Specifically, PCLMix is built upon a heterogeneous dual-decoder backbone, addressing the absence of structural priors through a strategy of dynamic mix augmentation during training. To handle the discrete distribution of class features, PCLMix incorporates pixel-level contrastive learning based on prediction uncertainty, effectively enhancing the model's ability to differentiate inter-class pixel differences and intra-class consistency. Furthermore, to reinforce segmentation consistency and robustness, PCLMix employs an auxiliary decoder for dual consistency regularization. In the inference phase, the auxiliary decoder will be dropped and no computation complexity is increased. Extensive experiments on the ACDC dataset demonstrate that PCLMix appropriately propagates local supervision signals to the global scale, further narrowing the gap between weakly supervised and fully supervised segmentation methods. Our code is available at https://github.com/Torpedo2648/PCLMix.
5/21/2024

MMCL: Boosting Deformable DETR-Based Detectors with Multi-Class Min-Margin Contrastive Learning for Superior Prohibited Item Detection
Mingyuan Li, Tong Jia, Hui Lu, Bowen Ma, Hao Wang, Dongyue Chen
0
0
Prohibited Item detection in X-ray images is one of the most effective security inspection methods.However, differing from natural light images, the unique overlapping phenomena in X-ray images lead to the coupling of foreground and background features, thereby lowering the accuracy of general object detectors.Therefore, we propose a Multi-Class Min-Margin Contrastive Learning (MMCL) method that, by clarifying the category semantic information of content queries under the deformable DETR architecture, aids the model in extracting specific category foreground information from coupled features.Specifically, after grouping content queries by the number of categories, we employ the Multi-Class Inter-Class Exclusion (MIE) loss to push apart content queries from different groups. Concurrently, the Intra-Class Min-Margin Clustering (IMC) loss is utilized to attract content queries within the same group, while ensuring the preservation of necessary disparity. As training, the inherent Hungarian matching of the model progressively strengthens the alignment between each group of queries and the semantic features of their corresponding category of objects. This evolving coherence ensures a deep-seated grasp of category characteristics, consequently bolstering the anti-overlapping detection capabilities of models.MMCL is versatile and can be easily plugged into any deformable DETR-based model with dozens of lines of code. Extensive experiments on the PIXray and OPIXray datasets demonstrate that MMCL significantly enhances the performance of various state-of-the-art models without increasing complexity. The code has been released at https://github.com/anonymity0403/MMCL.
6/6/2024
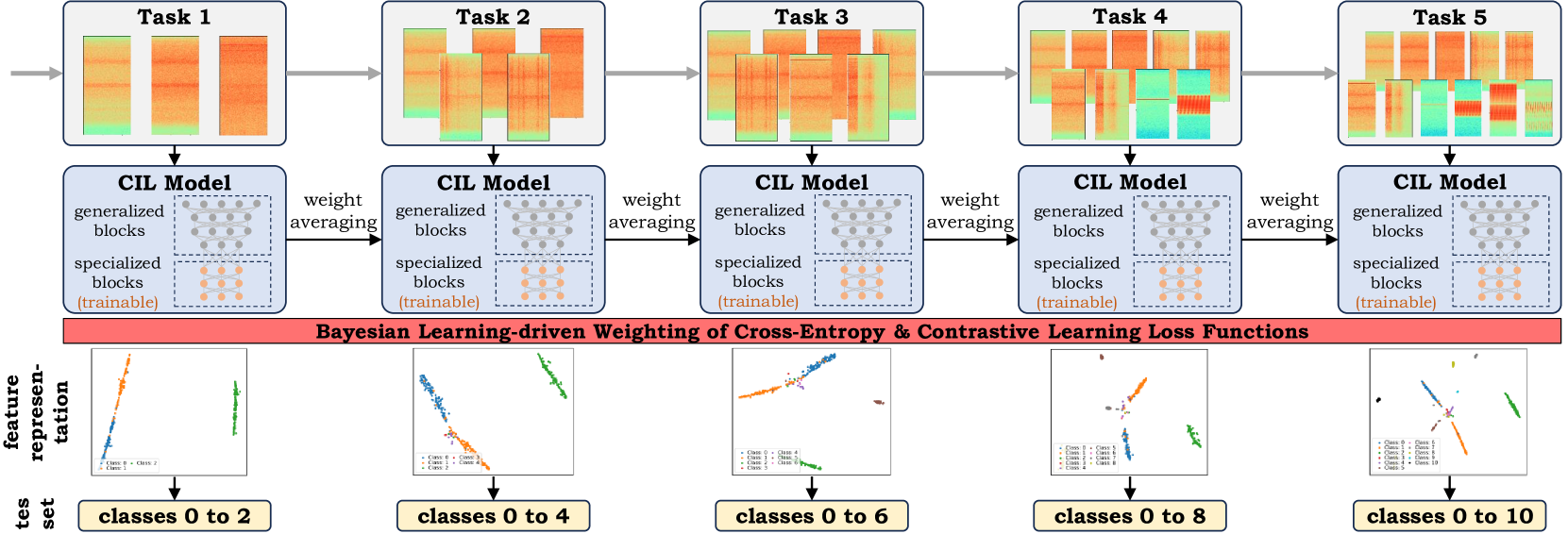
Bayesian Learning-driven Prototypical Contrastive Loss for Class-Incremental Learning
Nisha L. Raichur, Lucas Heublein, Tobias Feigl, Alexander Rugamer, Christopher Mutschler, Felix Ott
0
0
The primary objective of methods in continual learning is to learn tasks in a sequential manner over time from a stream of data, while mitigating the detrimental phenomenon of catastrophic forgetting. In this paper, we focus on learning an optimal representation between previous class prototypes and newly encountered ones. We propose a prototypical network with a Bayesian learning-driven contrastive loss (BLCL) tailored specifically for class-incremental learning scenarios. Therefore, we introduce a contrastive loss that incorporates new classes into the latent representation by reducing the intra-class distance and increasing the inter-class distance. Our approach dynamically adapts the balance between the cross-entropy and contrastive loss functions with a Bayesian learning technique. Empirical evaluations conducted on both the CIFAR-10 dataset for image classification and images of a GNSS-based dataset for interference classification validate the efficacy of our method, showcasing its superiority over existing state-of-the-art approaches.
5/21/2024