InterpretCC: Intrinsic User-Centric Interpretability through Global Mixture of Experts

0

Sign in to get full access
Overview
- This paper introduces InterpretCC, a novel approach for developing inherently interpretable neural networks.
- InterpretCC leverages conditional computation to create interpretable models by selectively activating different parts of the network based on the input.
- The authors demonstrate that InterpretCC can achieve competitive performance on benchmark tasks while providing inherent interpretability.
Plain English Explanation
InterpretCC: Conditional Computation for Inherently Interpretable Neural Networks is a research paper that introduces a new way to build neural networks that are easier for humans to understand.
Traditional neural networks can be very powerful, but they often behave like "black boxes" - it's difficult to know exactly how they make their decisions. This can be a problem, especially in sensitive applications like healthcare or finance.
The key idea behind InterpretCC is to create neural networks that only activate certain "parts" of themselves based on the specific input they receive. This allows the network to be more modular and transparent, making it easier to understand how it is arriving at its outputs.
The authors show that InterpretCC can achieve performance on par with standard neural networks, while also providing built-in interpretability. This could be very useful in applications where it's important to be able to explain and justify the decisions made by an AI system.
Technical Explanation
InterpretCC: Conditional Computation for Inherently Interpretable Neural Networks presents a novel approach for developing neural networks with inherent interpretability.
The key innovation is the use of conditional computation, where different parts of the network are selectively activated based on the input. This allows the network to be more modular, as different "sub-networks" can be responsible for different aspects of the task.
The authors formulate the problem as a constrained optimization, where the goal is to learn a network that is both performant and interpretable. They introduce a novel regularization term to encourage the selective activation of sub-networks.
Experiments on benchmark datasets demonstrate that InterpretCC can achieve competitive performance compared to standard neural networks, while also providing inherent interpretability through the selective activation of sub-networks.
Critical Analysis
The InterpretCC approach is an interesting step towards developing more interpretable neural networks. By leveraging conditional computation, the authors are able to create models that are both performant and provide built-in explanations for their decisions.
However, the paper does not address several important considerations. First, the authors only evaluate InterpretCC on relatively simple benchmark tasks, and it's unclear how well the approach would scale to more complex, real-world problems. Additionally, the paper does not explore the interpretability of the sub-networks in depth, or provide user studies to assess the human interpretability of the models.
Further research would be needed to better understand the practical limitations and tradeoffs of the InterpretCC approach. For example, it would be valuable to see how the interpretability and performance of InterpretCC compares to other interpretable AI techniques, such as concept-based models or probabilistic model inversion.
Conclusion
InterpretCC: Conditional Computation for Inherently Interpretable Neural Networks presents a promising approach for developing neural networks with built-in interpretability. By selectively activating different sub-networks based on the input, the authors are able to create models that are both performant and provide explanations for their decisions.
This work represents an important step towards the goal of more interpretable and transparent AI systems. As AI becomes increasingly prevalent in sensitive domains, the ability to understand and justify the decisions made by these systems will be crucial. Further research and real-world deployment of techniques like InterpretCC could help make AI more accessible and trustworthy for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
InterpretCC: Intrinsic User-Centric Interpretability through Global Mixture of Experts
Vinitra Swamy, Syrielle Montariol, Julian Blackwell, Jibril Frej, Martin Jaggi, Tanja Kaser
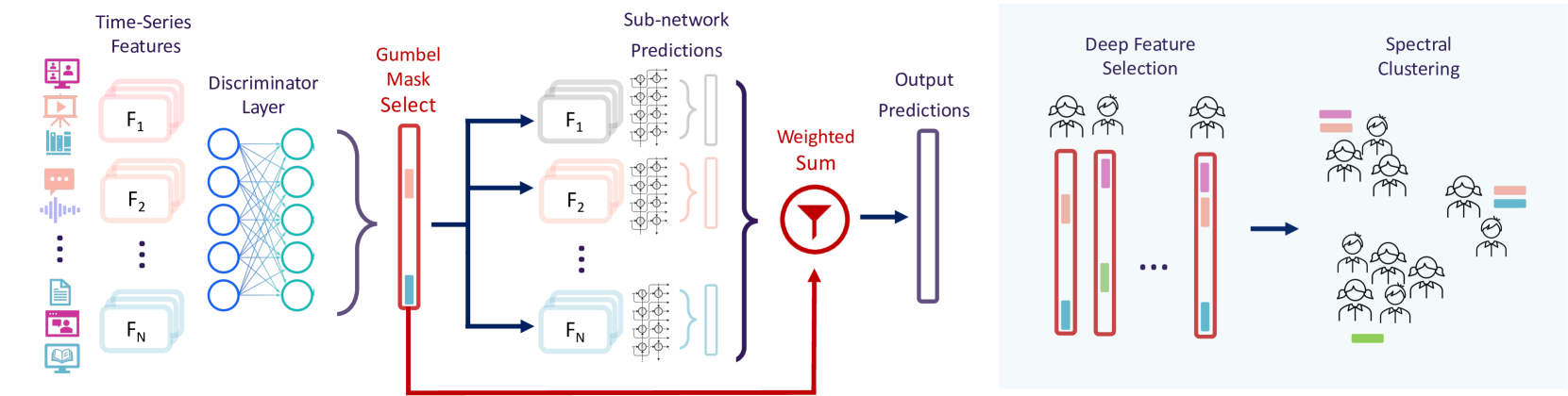
Interpretability for neural networks is a trade-off between three key requirements: 1) faithfulness of the explanation (i.e., how perfectly it explains the prediction), 2) understandability of the explanation by humans, and 3) model performance. Most existing methods compromise one or more of these requirements; e.g., post-hoc approaches provide limited faithfulness, automatically identified feature masks compromise understandability, and intrinsically interpretable methods such as decision trees limit model performance. These shortcomings are unacceptable for sensitive applications such as education and healthcare, which require trustworthy explanations, actionable interpretations, and accurate predictions. In this work, we present InterpretCC (interpretable conditional computation), a family of interpretable-by-design neural networks that guarantee human-centric interpretability, while maintaining comparable performance to state-of-the-art models by adaptively and sparsely activating features before prediction. We extend this idea into an interpretable, global mixture-of-experts (MoE) model that allows humans to specify topics of interest, discretely separates the feature space for each data point into topical subnetworks, and adaptively and sparsely activates these topical subnetworks for prediction. We apply variations of the InterpretCC architecture for text, time series and tabular data across several real-world benchmarks, demonstrating comparable performance with non-interpretable baselines, outperforming interpretable-by-design baselines, and showing higher actionability and usefulness according to a user study.
Read more5/30/2024
0
Interpret3C: Interpretable Student Clustering Through Individualized Feature Selection
Isadora Salles, Paola Mejia-Domenzain, Vinitra Swamy, Julian Blackwell, Tanja Kaser
Clustering in education, particularly in large-scale online environments like MOOCs, is essential for understanding and adapting to diverse student needs. However, the effectiveness of clustering depends on its interpretability, which becomes challenging with high-dimensional data. Existing clustering approaches often neglect individual differences in feature importance and rely on a homogenized feature set. Addressing this gap, we introduce Interpret3C (Interpretable Conditional Computation Clustering), a novel clustering pipeline that incorporates interpretable neural networks (NNs) in an unsupervised learning context. This method leverages adaptive gating in NNs to select features for each student. Then, clustering is performed using the most relevant features per student, enhancing clusters' relevance and interpretability. We use Interpret3C to analyze the behavioral clusters considering individual feature importances in a MOOC with over 5,000 students. This research contributes to the field by offering a scalable, robust clustering methodology and an educational case study that respects individual student differences and improves interpretability for high-dimensional data.
Read more7/18/2024

0
A Critical Assessment of Interpretable and Explainable Machine Learning for Intrusion Detection
Omer Subasi, Johnathan Cree, Joseph Manzano, Elena Peterson
There has been a large number of studies in interpretable and explainable ML for cybersecurity, in particular, for intrusion detection. Many of these studies have significant amount of overlapping and repeated evaluations and analysis. At the same time, these studies overlook crucial model, data, learning process, and utility related issues and many times completely disregard them. These issues include the use of overly complex and opaque ML models, unaccounted data imbalances and correlated features, inconsistent influential features across different explanation methods, the inconsistencies stemming from the constituents of a learning process, and the implausible utility of explanations. In this work, we empirically demonstrate these issues, analyze them and propose practical solutions in the context of feature-based model explanations. Specifically, we advise avoiding complex opaque models such as Deep Neural Networks and instead using interpretable ML models such as Decision Trees as the available intrusion datasets are not difficult for such interpretable models to classify successfully. Then, we bring attention to the binary classification metrics such as Matthews Correlation Coefficient (which are well-suited for imbalanced datasets. Moreover, we find that feature-based model explanations are most often inconsistent across different settings. In this respect, to further gauge the extent of inconsistencies, we introduce the notion of cross explanations which corroborates that the features that are determined to be impactful by one explanation method most often differ from those by another method. Furthermore, we show that strongly correlated data features and the constituents of a learning process, such as hyper-parameters and the optimization routine, become yet another source of inconsistent explanations. Finally, we discuss the utility of feature-based explanations.
Read more7/8/2024
🗣️
0
The Cognitive Revolution in Interpretability: From Explaining Behavior to Interpreting Representations and Algorithms
Adam Davies, Ashkan Khakzar
Artificial neural networks have long been understood as black boxes: though we know their computation graphs and learned parameters, the knowledge encoded by these weights and functions they perform are not inherently interpretable. As such, from the early days of deep learning, there have been efforts to explain these models' behavior and understand them internally; and recently, mechanistic interpretability (MI) has emerged as a distinct research area studying the features and implicit algorithms learned by foundation models such as large language models. In this work, we aim to ground MI in the context of cognitive science, which has long struggled with analogous questions in studying and explaining the behavior of black box intelligent systems like the human brain. We leverage several important ideas and developments in the history of cognitive science to disentangle divergent objectives in MI and indicate a clear path forward. First, we argue that current methods are ripe to facilitate a transition in deep learning interpretation echoing the cognitive revolution in 20th-century psychology that shifted the study of human psychology from pure behaviorism toward mental representations and processing. Second, we propose a taxonomy mirroring key parallels in computational neuroscience to describe two broad categories of MI research, semantic interpretation (what latent representations are learned and used) and algorithmic interpretation (what operations are performed over representations) to elucidate their divergent goals and objects of study. Finally, we elaborate the parallels and distinctions between various approaches in both categories, analyze the respective strengths and weaknesses of representative works, clarify underlying assumptions, outline key challenges, and discuss the possibility of unifying these modes of interpretation under a common framework.
Read more8/13/2024