MCU-MixQ: A HW/SW Co-optimized Mixed-precision Neural Network Design Framework for MCUs

0

Sign in to get full access
Overview
- Presents a framework called MCU-MixQ for designing mixed-precision neural networks optimized for microcontroller units (MCUs)
- Combines hardware and software co-optimization to achieve high performance and energy efficiency on MCUs
- Leverages SIMD instructions and other MCU-specific hardware features to accelerate mixed-precision neural networks
Plain English Explanation
The paper introduces a framework called MCU-MixQ that helps design mixed-precision neural networks for microcontroller units (MCUs). MCUs are small, low-power processors found in many everyday devices.
The key idea behind MCU-MixQ is to co-optimize the hardware and software components to get the best performance and energy efficiency on MCUs. It takes advantage of SIMD instructions and other specialized hardware features available in MCUs to speed up the execution of mixed-precision neural networks.
Mixed-precision neural networks use a combination of low-bitwidth and high-bitwidth data types to represent the network parameters and activations. This can significantly reduce the memory and computation requirements compared to using full-precision (32-bit) numbers everywhere.
By carefully designing the mixed-precision configuration and mapping it to the MCU hardware, MCU-MixQ is able to achieve high performance and energy efficiency, making it well-suited for deploying neural networks on resource-constrained devices.
Technical Explanation
The MCU-MixQ framework consists of two main components:
-
Hardware-software Co-optimization: MCU-MixQ analyzes the target MCU hardware to identify the most suitable SIMD instructions and other specialized features that can be leveraged to accelerate mixed-precision neural network computations. It then automatically generates an optimized software implementation that takes full advantage of these hardware capabilities.
-
Mixed-Precision Neural Network Design: MCU-MixQ explores the design space of mixed-precision neural networks, including the bitwidths of weights, activations, and other intermediate tensors. It uses a combination of analytical modeling and empirical evaluation to find the optimal mixed-precision configuration that balances accuracy, latency, and energy consumption on the target MCU.
The paper evaluates MCU-MixQ on several benchmark neural networks and MCU platforms, including ARM Cortex-M and RISC-V cores. The results show that MCU-MixQ can achieve significant performance and energy improvements compared to using full-precision networks or naive mixed-precision approaches.
Critical Analysis
The paper provides a comprehensive framework for deploying mixed-precision neural networks on MCUs, addressing both hardware and software aspects. However, some potential limitations and areas for further research include:
-
The evaluation is limited to a few specific neural network models and MCU platforms. More extensive testing across a wider range of applications and hardware would be beneficial to validate the generalizability of the approach.
-
The paper does not discuss the impact of quantization-aware training or other advanced techniques that can help maintain model accuracy with aggressive quantization. Incorporating such methods could further improve the efficiency of the mixed-precision models.
-
The co-optimization process relies on manual analysis of the target MCU hardware. Developing more automated techniques for hardware feature extraction and mapping to the mixed-precision design would make the framework more scalable and accessible.
Conclusion
The MCU-MixQ framework presents a promising approach for deploying efficient neural networks on resource-constrained microcontroller units. By co-optimizing the hardware and software components, it can leverage the unique capabilities of MCUs to accelerate mixed-precision neural network computations, offering significant improvements in performance and energy efficiency. This work highlights the importance of hardware-aware design for enabling the widespread adoption of machine learning on edge devices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MCU-MixQ: A HW/SW Co-optimized Mixed-precision Neural Network Design Framework for MCUs
Junfeng Gong, Cheng Liu, Long Cheng, Huawei Li, Xiaowei Li
Mixed-precision neural network (MPNN) that utilizes just enough data width for the neural network processing is an effective approach to meet the stringent resources constraints including memory and computing of MCUs. Nevertheless, there is still a lack of sub-byte and mixed-precision SIMD operations in MCU-class ISA and the limited computing capability of MCUs remains underutilized, which further aggravates the computing bound encountered in neural network processing. As a result, the benefits of MPNNs cannot be fully unleashed. In this work, we propose to pack multiple low-bitwidth arithmetic operations within a single instruction multiple data (SIMD) instructions in typical MCUs, and then develop an efficient convolution operator by exploring both the data parallelism and computing parallelism in convolution along with the proposed SIMD packing. Finally, we further leverage Neural Architecture Search (NAS) to build a HW/SW co-designed MPNN design framework, namely MCU-MixQ. This framework can optimize both the MPNN quantization and MPNN implementation efficiency, striking an optimized balance between neural network performance and accuracy. According to our experiment results, MCU-MixQ achieves 2.1$times$ and 1.4$times$ speedup over CMix-NN and MCUNet respectively under the same resource constraints.
Read more7/29/2024
0
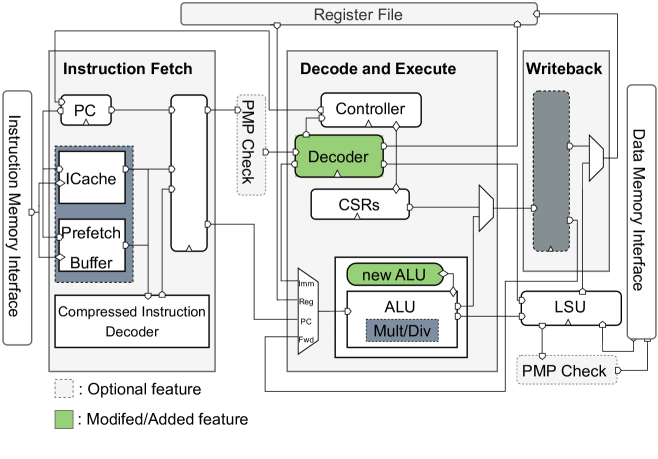
Mixed-precision Neural Networks on RISC-V Cores: ISA extensions for Multi-Pumped Soft SIMD Operations
Giorgos Armeniakos, Alexis Maras, Sotirios Xydis, Dimitrios Soudris
Recent advancements in quantization and mixed-precision approaches offers substantial opportunities to improve the speed and energy efficiency of Neural Networks (NN). Research has shown that individual parameters with varying low precision, can attain accuracies comparable to full-precision counterparts. However, modern embedded microprocessors provide very limited support for mixed-precision NNs regarding both Instruction Set Architecture (ISA) extensions and their hardware design for efficient execution of mixed-precision operations, i.e., introducing several performance bottlenecks due to numerous instructions for data packing and unpacking, arithmetic unit under-utilizations etc. In this work, we bring together, for the first time, ISA extensions tailored to mixed-precision hardware optimizations, targeting energy-efficient DNN inference on leading RISC-V CPU architectures. To this end, we introduce a hardware-software co-design framework that enables cooperative hardware design, mixed-precision quantization, ISA extensions and inference in cycle-accurate emulations. At hardware level, we firstly expand the ALU unit within our proof-of-concept micro-architecture to support configurable fine grained mixed-precision arithmetic operations. Subsequently, we implement multi-pumping to minimize execution latency, with an additional soft SIMD optimization applied for 2-bit operations. At the ISA level, three distinct MAC instructions are encoded extending the RISC-V ISA, and exposed up to the compiler level, each corresponding to a different mixed-precision operational mode. Our extensive experimental evaluation over widely used DNNs and datasets, such as CIFAR10 and ImageNet, demonstrates that our framework can achieve, on average, 15x energy reduction for less than 1% accuracy loss and outperforms the ISA-agnostic state-of-the-art RISC-V cores.
Read more8/14/2024
🧠
0
On-Chip Hardware-Aware Quantization for Mixed Precision Neural Networks
Wei Huang, Haotong Qin, Yangdong Liu, Jingzhuo Liang, Yulun Zhang, Ying Li, Xianglong Liu
Low-bit quantization emerges as one of the most promising compression approaches for deploying deep neural networks on edge devices. Mixed-precision quantization leverages a mixture of bit-widths to unleash the accuracy and efficiency potential of quantized models. However, existing mixed-precision quantization methods rely on simulations in high-performance devices to achieve accuracy and efficiency trade-offs in immense search spaces. This leads to a non-negligible gap between the estimated efficiency metrics and the actual hardware that makes quantized models far away from the optimal accuracy and efficiency, and also causes the quantization process to rely on additional high-performance devices. In this paper, we propose an On-Chip Hardware-Aware Quantization (OHQ) framework, performing hardware-aware mixed-precision quantization on deployed edge devices to achieve accurate and efficient computing. Specifically, for efficiency metrics, we built an On-Chip Quantization Aware pipeline, which allows the quantization process to perceive the actual hardware efficiency of the quantization operator and avoid optimization errors caused by inaccurate simulation. For accuracy metrics, we propose Mask-Guided Quantization Estimation technology to effectively estimate the accuracy impact of operators in the on-chip scenario, getting rid of the dependence of the quantization process on high computing power. By synthesizing insights from quantized models and hardware through linear optimization, we can obtain optimized bit-width configurations to achieve outstanding performance on accuracy and efficiency. We evaluate inference accuracy and acceleration with quantization for various architectures and compression ratios on hardware. OHQ achieves 70% and 73% accuracy for ResNet-18 and MobileNetV3, respectively, and can reduce latency by 15~30% compared to INT8 on real deployment.
Read more5/24/2024
0
SySMOL: Co-designing Algorithms and Hardware for Neural Networks with Heterogeneous Precisions
Cyrus Zhou, Pedro Savarese, Vaughn Richard, Zack Hassman, Xin Yuan, Michael Maire, Michael DiBrino, Yanjing Li
Recent quantization techniques have enabled heterogeneous precisions at very fine granularity, e.g., each parameter/activation can take on a different precision, resulting in compact neural networks without sacrificing accuracy. However, there is a lack of efficient architectural support for such networks, which require additional hardware to decode the precision settings for individual variables, align the variables, and provide fine-grained mixed-precision compute capabilities. The complexity of these operations introduces high overheads. Thus, the improvements in inference latency/energy of these networks are not commensurate with the compression ratio, and may be inferior to larger quantized networks with uniform precisions. We present an end-to-end co-design approach encompassing computer architecture, training algorithm, and inference optimization to efficiently execute networks with fine-grained heterogeneous precisions. The key to our approach is a novel training algorithm designed to accommodate hardware constraints and inference operation requirements, outputting networks with input-channel-wise heterogeneous precisions and at most three precision levels. Combined with inference optimization techniques, existing architectures with low-cost enhancements can support such networks efficiently, yielding optimized tradeoffs between accuracy, compression ratio and inference latency/energy. We demonstrate the efficacy of our approach across CPU and GPU architectures. For various representative neural networks, our approach achieves >10x improvements in both compression ratio and inference latency, with negligible degradation in accuracy compared to full-precision networks.
Read more5/8/2024