Mixed-precision Neural Networks on RISC-V Cores: ISA extensions for Multi-Pumped Soft SIMD Operations

0
Sign in to get full access
Overview
- Explores optimizing deep neural networks on RISC-V processors through mixed-precision techniques and ISA extensions
- Proposes a RISC-V ISA extension called "Multi-Pumped Soft SIMD Operations" to accelerate mixed-precision neural network inference
- Demonstrates significant improvements in energy efficiency and performance compared to baseline RISC-V cores
Plain English Explanation
This research paper explores ways to make deep learning models run more efficiently on RISC-V processors. The key idea is to use a technique called "mixed-precision," where different parts of the neural network use different levels of numerical precision to save computational resources.
To support these mixed-precision neural networks, the researchers propose a new set of RISC-V ISA instructions called "Multi-Pumped Soft SIMD Operations." These instructions allow the RISC-V processor to perform multiple calculations in parallel, boosting the performance of the mixed-precision models.
The results show that this approach leads to significant improvements in energy efficiency and overall performance compared to using a standard RISC-V processor. This is an important development for deploying powerful deep neural networks on embedded and edge devices, where power consumption and computational constraints are key concerns.
Technical Explanation
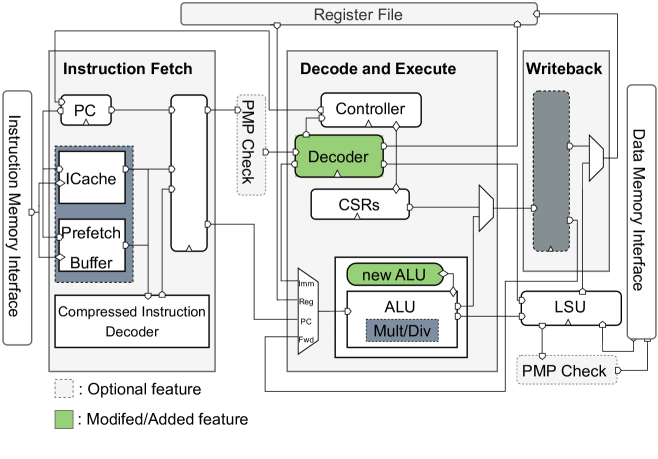
The paper proposes a hardware-software co-design approach to optimize the execution of mixed-precision neural networks on RISC-V cores. The core idea is to leverage mixed-precision techniques, where different parts of the neural network use different levels of numerical precision (e.g., 8-bit, 16-bit, 32-bit) to save computational resources.
To support these mixed-precision neural networks, the researchers introduce a RISC-V ISA extension called "Multi-Pumped Soft SIMD Operations." This extension adds new instructions that enable the RISC-V processor to perform multiple lower-precision calculations in parallel, effectively boosting the performance of mixed-precision inference.
The researchers evaluate their approach on a range of deep learning workloads, including image classification and language modeling tasks. They compare the performance and energy efficiency of their mixed-precision RISC-V core to a baseline RISC-V core without the proposed extensions. The results show significant improvements in both performance and energy efficiency, demonstrating the benefits of their hardware-software co-design approach.
Critical Analysis
The paper provides a comprehensive and well-designed study on optimizing the execution of mixed-precision neural networks on RISC-V cores. The proposed ISA extensions are a clever way to leverage the unique characteristics of mixed-precision models to improve efficiency on resource-constrained processors.
One potential limitation of the study is that it focuses on a specific set of deep learning workloads and may not generalize to a broader range of applications. Additionally, the paper does not extensively explore the tradeoffs between precision, accuracy, and performance, which could be an interesting area for further research.
It would also be valuable to see a more detailed analysis of the hardware implementation complexity and potential power/area overheads of the proposed ISA extensions. This would help assess the feasibility and practicality of deploying these extensions in real-world RISC-V systems.
Overall, this research represents an important contribution to the field of efficient neural network inference on embedded and edge devices. The insights and techniques presented in this paper could have significant implications for the co-design of ML algorithms and hardware in the future.
Conclusion
This paper presents a hardware-software co-design approach to optimizing the execution of mixed-precision neural networks on RISC-V processors. By introducing a novel RISC-V ISA extension called "Multi-Pumped Soft SIMD Operations," the researchers demonstrate significant improvements in both performance and energy efficiency compared to a baseline RISC-V core.
This research highlights the potential of leveraging mixed-precision techniques and specialized hardware extensions to enable the deployment of powerful deep learning models on resource-constrained edge devices. The insights and techniques presented in this paper could have far-reaching implications for the full-stack evaluation of machine learning inference workloads on diverse hardware platforms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mixed-precision Neural Networks on RISC-V Cores: ISA extensions for Multi-Pumped Soft SIMD Operations
Giorgos Armeniakos, Alexis Maras, Sotirios Xydis, Dimitrios Soudris
Recent advancements in quantization and mixed-precision approaches offers substantial opportunities to improve the speed and energy efficiency of Neural Networks (NN). Research has shown that individual parameters with varying low precision, can attain accuracies comparable to full-precision counterparts. However, modern embedded microprocessors provide very limited support for mixed-precision NNs regarding both Instruction Set Architecture (ISA) extensions and their hardware design for efficient execution of mixed-precision operations, i.e., introducing several performance bottlenecks due to numerous instructions for data packing and unpacking, arithmetic unit under-utilizations etc. In this work, we bring together, for the first time, ISA extensions tailored to mixed-precision hardware optimizations, targeting energy-efficient DNN inference on leading RISC-V CPU architectures. To this end, we introduce a hardware-software co-design framework that enables cooperative hardware design, mixed-precision quantization, ISA extensions and inference in cycle-accurate emulations. At hardware level, we firstly expand the ALU unit within our proof-of-concept micro-architecture to support configurable fine grained mixed-precision arithmetic operations. Subsequently, we implement multi-pumping to minimize execution latency, with an additional soft SIMD optimization applied for 2-bit operations. At the ISA level, three distinct MAC instructions are encoded extending the RISC-V ISA, and exposed up to the compiler level, each corresponding to a different mixed-precision operational mode. Our extensive experimental evaluation over widely used DNNs and datasets, such as CIFAR10 and ImageNet, demonstrates that our framework can achieve, on average, 15x energy reduction for less than 1% accuracy loss and outperforms the ISA-agnostic state-of-the-art RISC-V cores.
Read more8/14/2024

0
MCU-MixQ: A HW/SW Co-optimized Mixed-precision Neural Network Design Framework for MCUs
Junfeng Gong, Cheng Liu, Long Cheng, Huawei Li, Xiaowei Li
Mixed-precision neural network (MPNN) that utilizes just enough data width for the neural network processing is an effective approach to meet the stringent resources constraints including memory and computing of MCUs. Nevertheless, there is still a lack of sub-byte and mixed-precision SIMD operations in MCU-class ISA and the limited computing capability of MCUs remains underutilized, which further aggravates the computing bound encountered in neural network processing. As a result, the benefits of MPNNs cannot be fully unleashed. In this work, we propose to pack multiple low-bitwidth arithmetic operations within a single instruction multiple data (SIMD) instructions in typical MCUs, and then develop an efficient convolution operator by exploring both the data parallelism and computing parallelism in convolution along with the proposed SIMD packing. Finally, we further leverage Neural Architecture Search (NAS) to build a HW/SW co-designed MPNN design framework, namely MCU-MixQ. This framework can optimize both the MPNN quantization and MPNN implementation efficiency, striking an optimized balance between neural network performance and accuracy. According to our experiment results, MCU-MixQ achieves 2.1$times$ and 1.4$times$ speedup over CMix-NN and MCUNet respectively under the same resource constraints.
Read more7/29/2024

0
Optimizing Foundation Model Inference on a Many-tiny-core Open-source RISC-V Platform
Viviane Potocnik, Luca Colagrande, Tim Fischer, Luca Bertaccini, Daniele Jahier Pagliari, Alessio Burrello, Luca Benini
Transformer-based foundation models have become crucial for various domains, most notably natural language processing (NLP) or computer vision (CV). These models are predominantly deployed on high-performance GPUs or hardwired accelerators with highly customized, proprietary instruction sets. Until now, limited attention has been given to RISC-V-based general-purpose platforms. In our work, we present the first end-to-end inference results of transformer models on an open-source many-tiny-core RISC-V platform implementing distributed Softmax primitives and leveraging ISA extensions for SIMD floating-point operand streaming and instruction repetition, as well as specialized DMA engines to minimize costly main memory accesses and to tolerate their latency. We focus on two foundational transformer topologies, encoder-only and decoder-only models. For encoder-only models, we demonstrate a speedup of up to 12.8x between the most optimized implementation and the baseline version. We reach over 79% FPU utilization and 294 GFLOPS/W, outperforming State-of-the-Art (SoA) accelerators by more than 2x utilizing the HW platform while achieving comparable throughput per computational unit. For decoder-only topologies, we achieve 16.1x speedup in the Non-Autoregressive (NAR) mode and up to 35.6x speedup in the Autoregressive (AR) mode compared to the baseline implementation. Compared to the best SoA dedicated accelerator, we achieve 2.04x higher FPU utilization.
Read more5/30/2024

0
RISC-V R-Extension: Advancing Efficiency with Rented-Pipeline for Edge DNN Processing
Won Hyeok Kim, Hyeong Jin Kim, Tae Hee Han
The proliferation of edge devices necessitates efficient computational architectures for lightweight tasks, particularly deep neural network (DNN) inference. Traditional NPUs, though effective for such operations, face challenges in power, cost, and area when integrated into lightweight edge devices. The RISC-V architecture, known for its modularity and open-source nature, offers a viable alternative. This paper introduces the RISC-V R-extension, a novel approach to enhancing DNN process efficiency on edge devices. The extension features rented-pipeline stages and architectural pipeline registers (APR), which optimize critical operation execution, thereby reducing latency and memory access frequency. Furthermore, this extension includes new custom instructions to support these architectural improvements. Through comprehensive analysis, this study demonstrates the boost of R-extension in edge device processing, setting the stage for more responsive and intelligent edge applications.
Read more7/4/2024