TextCoT: Zoom In for Enhanced Multimodal Text-Rich Image Understanding
2404.09797
0
0

Abstract
The advent of Large Multimodal Models (LMMs) has sparked a surge in research aimed at harnessing their remarkable reasoning abilities. However, for understanding text-rich images, challenges persist in fully leveraging the potential of LMMs, and existing methods struggle with effectively processing high-resolution images. In this work, we propose TextCoT, a novel Chain-of-Thought framework for text-rich image understanding. TextCoT utilizes the captioning ability of LMMs to grasp the global context of the image and the grounding capability to examine local textual regions. This allows for the extraction of both global and local visual information, facilitating more accurate question-answering. Technically, TextCoT consists of three stages, including image overview, coarse localization, and fine-grained observation. The image overview stage provides a comprehensive understanding of the global scene information, and the coarse localization stage approximates the image area containing the answer based on the question asked. Then, integrating the obtained global image descriptions, the final stage further examines specific regions to provide accurate answers. Our method is free of extra training, offering immediate plug-and-play functionality. Extensive experiments are conducted on a series of text-rich image question-answering benchmark datasets based on several advanced LMMs, and the results demonstrate the effectiveness and strong generalization ability of our method. Code is available at https://github.com/bzluan/TextCoT.
Create account to get full access
Overview
- This paper proposes TextCoT, a novel multimodal model that leverages text-rich images to enhance understanding of the visual content.
- The key idea is to "zoom in" on the text regions of the image and use the extracted text information to better understand the overall visual context.
- The authors demonstrate the effectiveness of TextCoT on various multimodal benchmarks, including image-text retrieval and visual question answering tasks.
Plain English Explanation
The researchers developed a new AI system called TextCoT that can better understand images that contain a lot of text, such as diagrams, infographics, or documents. Many existing AI models struggle with these types of images because they focus only on the visual elements and don't take the text into account.
The key innovation in TextCoT is that it "zooms in" on the text parts of the image and uses the information from the text to help it understand the overall meaning and context of the visual content. For example, if the image shows a scientific diagram with lots of labels and annotations, TextCoT can read and process the text to figure out what the diagram is illustrating.
The researchers tested TextCoT on several benchmark tasks, such as finding relevant images based on a text description, and answering questions about the content of an image. They showed that TextCoT outperforms other state-of-the-art models, especially on images that contain a significant amount of text. This suggests that incorporating text information can be very useful for building AI systems that can truly understand complex, multimodal content.
Technical Explanation
The core of the TextCoT model is a transformer-based architecture that takes an image and its accompanying text as input. The model first encodes the visual and textual information separately using convolutional and transformer networks, respectively. It then learns to align the visual and textual features through a series of cross-attention layers.
Crucially, TextCoT includes a "zoom-in" mechanism that focuses on the text-rich regions of the image. This is achieved by using an attention-based text detection module that identifies the location of text in the image. The model then applies a higher resolution encoder to these text-rich regions to extract more detailed textual features.
The authors demonstrate the effectiveness of this approach on image-text retrieval and visual question answering tasks, where TextCoT outperforms previous state-of-the-art models, especially on images with significant textual content.
Critical Analysis
The researchers acknowledge that TextCoT is not the first model to leverage text information for multimodal understanding. However, they argue that their "zoom-in" mechanism is a novel and effective way to incorporate this text data.
One potential limitation is that the text detection module may not always be accurate, which could negatively impact the overall performance of the model. The authors suggest that more advanced text detection techniques could be explored in future work to address this issue.
Additionally, the paper does not provide a detailed analysis of the types of images and text-rich content where TextCoT excels the most. It would be helpful to understand the specific scenarios or use cases where this approach is most beneficial compared to other multimodal models.
Overall, the TextCoT model presents an interesting and promising direction for enhancing multimodal understanding, particularly for complex, text-rich visual content. The authors' work highlights the importance of integrating linguistic information to build more robust and capable multimodal systems.
Conclusion
The TextCoT model proposed in this paper demonstrates the value of incorporating text information to improve multimodal understanding of complex, text-rich images. By "zooming in" on the textual content, the model is able to better contextualize the visual elements and outperform state-of-the-art approaches on tasks such as image-text retrieval and visual question answering.
This research suggests that future advancements in multimodal AI should look beyond just the visual aspects and find ways to effectively leverage the rich linguistic information that often accompanies real-world, multimodal data. The authors' work provides a promising step in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
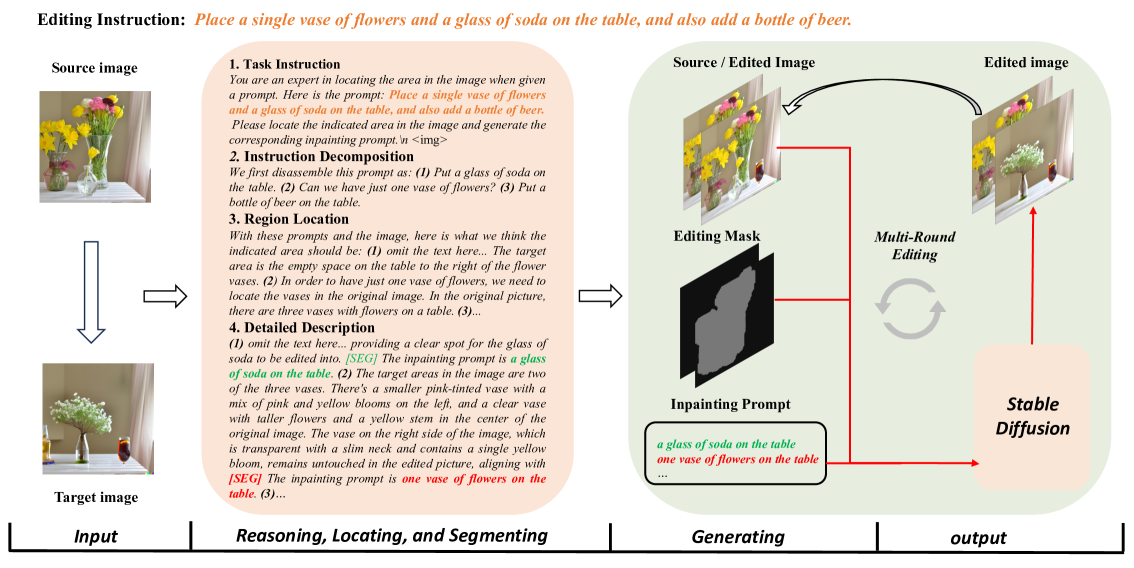
TIE: Revolutionizing Text-based Image Editing for Complex-Prompt Following and High-Fidelity Editing
Xinyu Zhang, Mengxue Kang, Fei Wei, Shuang Xu, Yuhe Liu, Lin Ma
0
0
As the field of image generation rapidly advances, traditional diffusion models and those integrated with multimodal large language models (LLMs) still encounter limitations in interpreting complex prompts and preserving image consistency pre and post-editing. To tackle these challenges, we present an innovative image editing framework that employs the robust Chain-of-Thought (CoT) reasoning and localizing capabilities of multimodal LLMs to aid diffusion models in generating more refined images. We first meticulously design a CoT process comprising instruction decomposition, region localization, and detailed description. Subsequently, we fine-tune the LISA model, a lightweight multimodal LLM, using the CoT process of Multimodal LLMs and the mask of the edited image. By providing the diffusion models with knowledge of the generated prompt and image mask, our models generate images with a superior understanding of instructions. Through extensive experiments, our model has demonstrated superior performance in image generation, surpassing existing state-of-the-art models. Notably, our model exhibits an enhanced ability to understand complex prompts and generate corresponding images, while maintaining high fidelity and consistency in images before and after generation.
5/28/2024
💬
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, Alex Smola
0
0
Large language models (LLMs) have shown impressive performance on complex reasoning by leveraging chain-of-thought (CoT) prompting to generate intermediate reasoning chains as the rationale to infer the answer. However, existing CoT studies have primarily focused on the language modality. We propose Multimodal-CoT that incorporates language (text) and vision (images) modalities into a two-stage framework that separates rationale generation and answer inference. In this way, answer inference can leverage better generated rationales that are based on multimodal information. Experimental results on ScienceQA and A-OKVQA benchmark datasets show the effectiveness of our proposed approach. With Multimodal-CoT, our model under 1 billion parameters achieves state-of-the-art performance on the ScienceQA benchmark. Our analysis indicates that Multimodal-CoT offers the advantages of mitigating hallucination and enhancing convergence speed. Code is publicly available at https://github.com/amazon-science/mm-cot.
5/21/2024
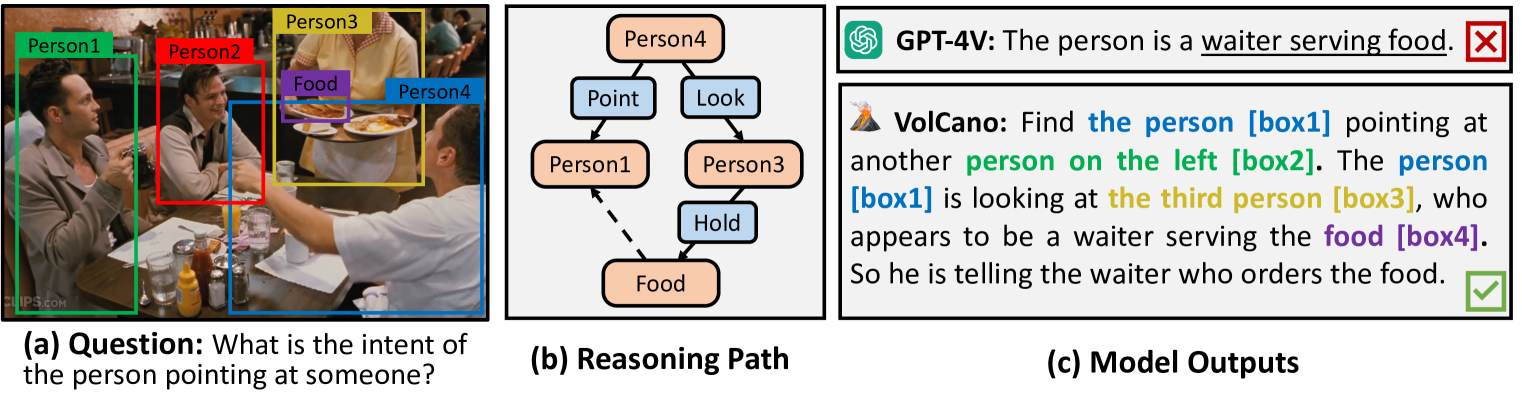
VoCoT: Unleashing Visually Grounded Multi-Step Reasoning in Large Multi-Modal Models
Zejun Li, Ruipu Luo, Jiwen Zhang, Minghui Qiu, Zhongyu Wei
0
0
While large multi-modal models (LMMs) have exhibited impressive capabilities across diverse tasks, their effectiveness in handling complex tasks has been limited by the prevailing single-step reasoning paradigm. To this end, this paper proposes VoCoT, a multi-step Visually grounded object-centric Chain-of-Thought reasoning framework tailored for inference with LMMs. VoCoT is characterized by two key features: (1) object-centric reasoning paths that revolve around cross-modal shared object-level information, and (2) visually grounded representation of object concepts in a multi-modal interleaved and aligned manner, which effectively bridges the modality gap within LMMs during long-term generation. Additionally, we construct an instruction dataset to facilitate LMMs in adapting to reasoning with VoCoT. By introducing VoCoT into the prevalent open-source LMM architecture, we introduce VolCano. With only 7B parameters and limited input resolution, VolCano demonstrates excellent performance across various scenarios, surpassing SOTA models, including GPT-4V, in tasks requiring complex reasoning. Our code, data and model will be available at https://github.com/RupertLuo/VoCoT.
5/29/2024

M$^3$CoT: A Novel Benchmark for Multi-Domain Multi-step Multi-modal Chain-of-Thought
Qiguang Chen, Libo Qin, Jin Zhang, Zhi Chen, Xiao Xu, Wanxiang Che
0
0
Multi-modal Chain-of-Thought (MCoT) requires models to leverage knowledge from both textual and visual modalities for step-by-step reasoning, which gains increasing attention. Nevertheless, the current MCoT benchmark still faces some challenges: (1) absence of visual modal reasoning, (2) single-step visual modal reasoning, and (3) Domain missing, thereby hindering the development of MCoT. Motivated by this, we introduce a novel benchmark (M$^3$CoT) to address the above challenges, advancing the multi-domain, multi-step, and multi-modal CoT. Additionally, we conduct a thorough evaluation involving abundant MCoT approaches on Vision Large Language Models (VLLMs). In addition, we highlight that the current VLLMs still struggle to correctly reason in M$^3$CoT and there remains a large gap between existing VLLMs and human performance in M$^3$CoT, despite their superior results on previous MCoT benchmarks. To our knowledge, we take the first meaningful step toward the multi-domain, multi-step, and multi-modal scenario in MCoT. We hope that M$^3$CoT can serve as a valuable resource, providing a pioneering foundation in multi-domain, multi-step, multi-modal chain-of-thought research.
5/28/2024