MDT-A2G: Exploring Masked Diffusion Transformers for Co-Speech Gesture Generation

0
Sign in to get full access
Overview
- Explores the use of Masked Diffusion Transformers (MDTs) for co-speech gesture generation
- Proposes an architecture called MDT-A2G that generates realistic co-speech gestures from audio input
- Demonstrates state-of-the-art performance on benchmark datasets for gesture generation
Plain English Explanation
The paper investigates the use of a machine learning technique called Masked Diffusion Transformers (MDTs) for the task of generating co-speech gestures. Co-speech gestures are the hand and body movements that people make when they are speaking.
The researchers developed a model called MDT-A2G that takes audio input (the speech) and generates corresponding co-speech gestures. This is a challenging problem because gestures need to be well-synchronized with the speech and look natural.
The key idea behind MDT-A2G is to use a diffusion model, which is a type of generative AI model that can create realistic-looking outputs. The diffusion model is combined with a transformer neural network, which is good at capturing the temporal and semantic relationships in the speech and gesture data.
The paper shows that MDT-A2G outperforms previous state-of-the-art methods for co-speech gesture generation on standard benchmark datasets. This suggests that the MDT approach is a promising direction for creating more natural and expressive co-speech gestures in applications like virtual assistants, animated characters, and video conferencing.
Technical Explanation
The paper proposes a new architecture called MDT-A2G that leverages Masked Diffusion Transformers (MDTs) for the task of co-speech gesture generation.
The key components of MDT-A2G are:
-
Diffusion Model: The backbone of the architecture is a diffusion model, which is a type of generative AI model that creates realistic-looking outputs by iteratively adding and removing noise from data.
-
Transformer: MDT-A2G also incorporates a transformer neural network, which is well-suited for capturing the temporal and semantic relationships in speech and gesture data.
-
Masking: The model uses a masking technique during training, where some of the gesture information is randomly masked, forcing the model to learn how to predict the missing parts.
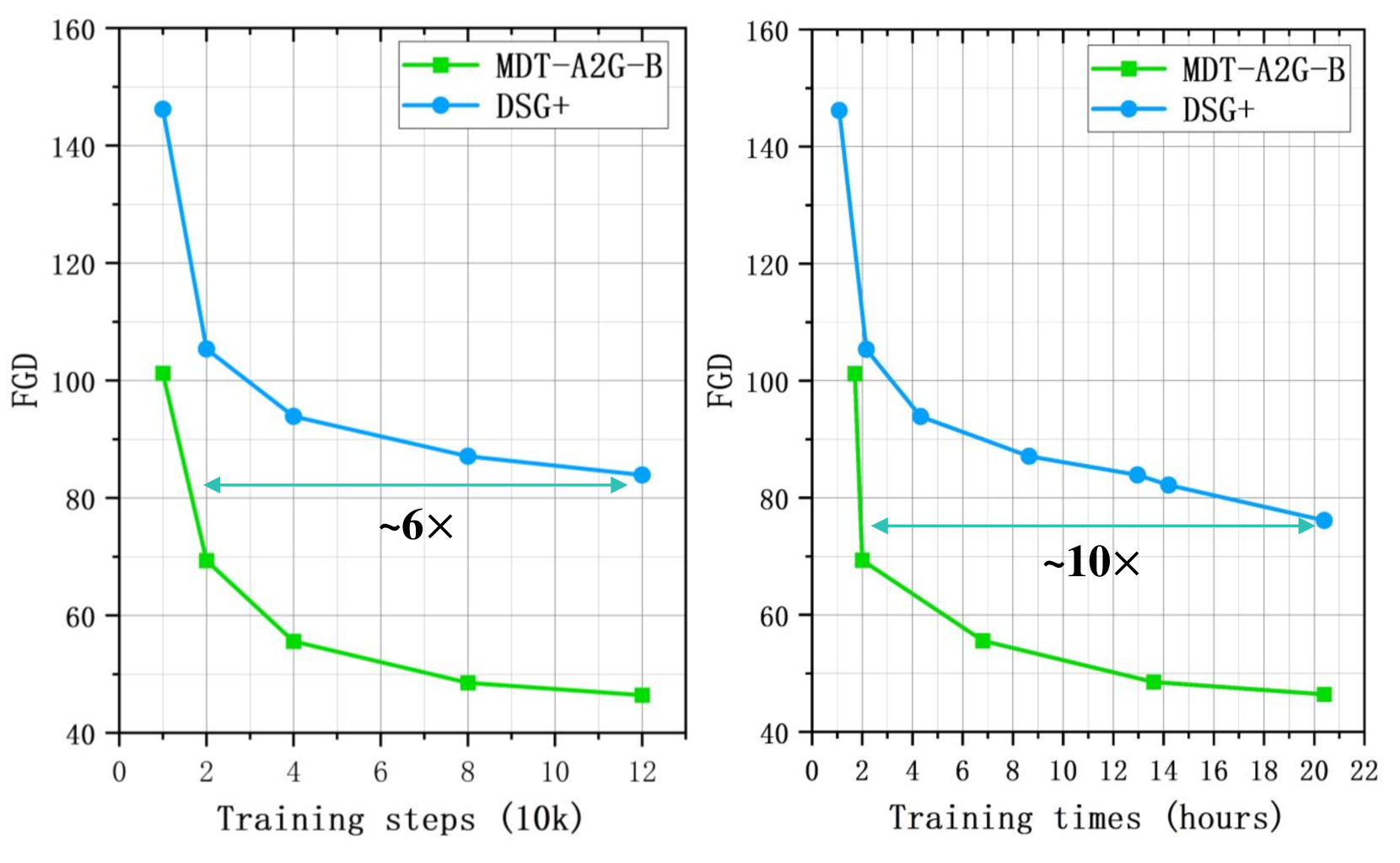
The researchers evaluate MDT-A2G on standard co-speech gesture generation datasets and show that it outperforms previous state-of-the-art methods. This suggests that the combination of diffusion models and transformers is a promising approach for creating more natural and expressive co-speech gestures.
Critical Analysis
The paper provides a thorough evaluation of the MDT-A2G model and its performance on benchmark datasets. However, it does not fully address some potential limitations and areas for further research:
-
Generalization: The paper focuses on the performance of MDT-A2G on the specific datasets used in the experiments. It would be valuable to assess how well the model generalizes to new speakers, accents, or conversational contexts.
-
Real-time Implementation: The paper does not discuss the computational efficiency of the MDT-A2G model, which would be an important consideration for real-time applications like virtual assistants or video conferencing.
-
Interpretability: As with many deep learning models, the internal workings of MDT-A2G may be difficult to interpret. Investigating ways to make the model's decision-making process more transparent could be a valuable area of future research.
-
Multimodal Integration: The paper focuses on generating co-speech gestures from audio input. Exploring how MDT-A2G could be extended to integrate additional modalities, such as visual cues, may lead to further improvements in gesture generation.
Overall, the paper presents a novel and promising approach to co-speech gesture generation, but there is still room for further research to address potential limitations and expand the capabilities of the MDT-A2G model.
Conclusion
The paper introduces a new architecture called MDT-A2G that uses Masked Diffusion Transformers to generate realistic co-speech gestures from audio input. The key innovation is the combination of diffusion models and transformer networks, which allows the model to capture the temporal and semantic relationships in speech and gesture data.
The empirical results demonstrate that MDT-A2G outperforms previous state-of-the-art methods on benchmark co-speech gesture generation datasets. This suggests that the MDT approach is a promising direction for creating more natural and expressive gestures in applications like virtual assistants, animated characters, and video conferencing.
While the paper provides a thorough evaluation, there are still opportunities for further research to address potential limitations and expand the capabilities of the model. Exploring generalization, real-time performance, interpretability, and multimodal integration could lead to even more advanced co-speech gesture generation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!