Measuring Variable Importance in Individual Treatment Effect Estimation with High Dimensional Data

0

Sign in to get full access
Overview
- The paper focuses on measuring the importance of variables in estimating individual treatment effects with high-dimensional data.
- It proposes a method for quantifying variable importance in this context and evaluates its performance on both simulated and real-world data.
- The method aims to provide insights into which variables are most influential in determining individual treatment effects.
Plain English Explanation
When researchers want to understand how a certain treatment or intervention affects individuals, they need to estimate the individual treatment effect (ITE) - the unique impact of the treatment on each person. This is especially challenging when there are many potential factors (variables) that could influence the treatment's effect, such as a person's age, gender, income, and so on.
The research paper introduces a new way to measure the importance of these variables in estimating ITEs. The key idea is to quantify how much each variable contributes to the estimated treatment effect for each individual. This can help researchers understand which factors are most influential in determining how the treatment works for different people.
The method works by analyzing the model used to estimate ITEs and extracting information about the relative importance of each variable. The authors test this approach on both simulated data and real-world datasets, showing that it can provide valuable insights into the drivers of individual treatment effects.
Overall, this research aims to give researchers and policymakers a better understanding of which factors matter most when estimating how treatments or interventions affect people as individuals, rather than just looking at average effects across a population.
Technical Explanation
The paper proposes a method for measuring variable importance in individual treatment effect (ITE) estimation with high-dimensional data. The key steps are:
- Estimating ITEs: The authors use a machine learning model to estimate the ITE for each individual in the dataset, based on their observed characteristics (variables).
- Quantifying Variable Importance: They then develop a technique to quantify how much each variable contributes to the estimated ITE for each individual. This involves analyzing the model's sensitivity to changes in each variable.
- Aggregating Variable Importance: The individual-level variable importance measures are then aggregated to provide an overall importance score for each variable across the entire dataset.
The authors evaluate their method on both simulated data and real-world datasets, showing that it can effectively identify the most important variables for ITE estimation, even in high-dimensional settings.
Critical Analysis
The paper makes a valuable contribution by providing a systematic way to understand which variables drive individual treatment effects. This can be particularly useful when dealing with complex, high-dimensional datasets where the determinants of treatment heterogeneity are not immediately clear.
However, the method does rely on the accuracy of the underlying ITE estimation model. If this model is misspecified or fails to capture important interactions between variables, the variable importance measures may not be fully reliable. The authors acknowledge this limitation and suggest further research to address it.
Additionally, the paper does not explore the potential for variable importance measures to vary across different subgroups within the dataset. In practice, the most important variables for ITE estimation may differ depending on the context or population of interest.
Overall, this research represents a promising step towards better understanding the drivers of individual treatment effects, but more work is needed to fully address the complexities and potential pitfalls of this challenging problem.
Conclusion
This paper introduces a novel method for measuring the importance of variables in individual treatment effect estimation with high-dimensional data. By quantifying the contribution of each variable to the estimated treatment effect for each individual, the approach can provide valuable insights into the key factors determining how a treatment or intervention affects people differently.
The authors demonstrate the effectiveness of their method on both simulated and real-world datasets, showing its potential to aid researchers and policymakers in understanding treatment heterogeneity. While the approach has some limitations, it represents an important advancement in the field of causal inference and personalized medicine.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Measuring Variable Importance in Individual Treatment Effect Estimation with High Dimensional Data
Joseph Paillard, Vitaliy Kolodyazhniy, Bertrand Thirion, Denis A. Engemann
Causal machine learning (ML) promises to provide powerful tools for estimating individual treatment effects. Although causal ML methods are now well established, they still face the significant challenge of interpretability, which is crucial for medical applications. In this work, we propose a new algorithm based on the Conditional Permutation Importance (CPI) method for statistically rigorous variable importance assessment in the context of Conditional Average Treatment Effect (CATE) estimation. Our method termed PermuCATE is agnostic to both the meta-learner and the ML model used. Through theoretical analysis and empirical studies, we show that this approach provides a reliable measure of variable importance and exhibits lower variance compared to the standard Leave-One-Covariate-Out (LOCO) method. We illustrate how this property leads to increased statistical power, which is crucial for the application of explainable ML in small sample sizes or high-dimensional settings. We empirically demonstrate the benefits of our approach in various simulation scenarios, including previously proposed benchmarks as well as more complex settings with high-dimensional and correlated variables that require advanced CATE estimators.
Read more8/26/2024
0
Multi-CATE: Multi-Accurate Conditional Average Treatment Effect Estimation Robust to Unknown Covariate Shifts
Christoph Kern, Michael Kim, Angela Zhou
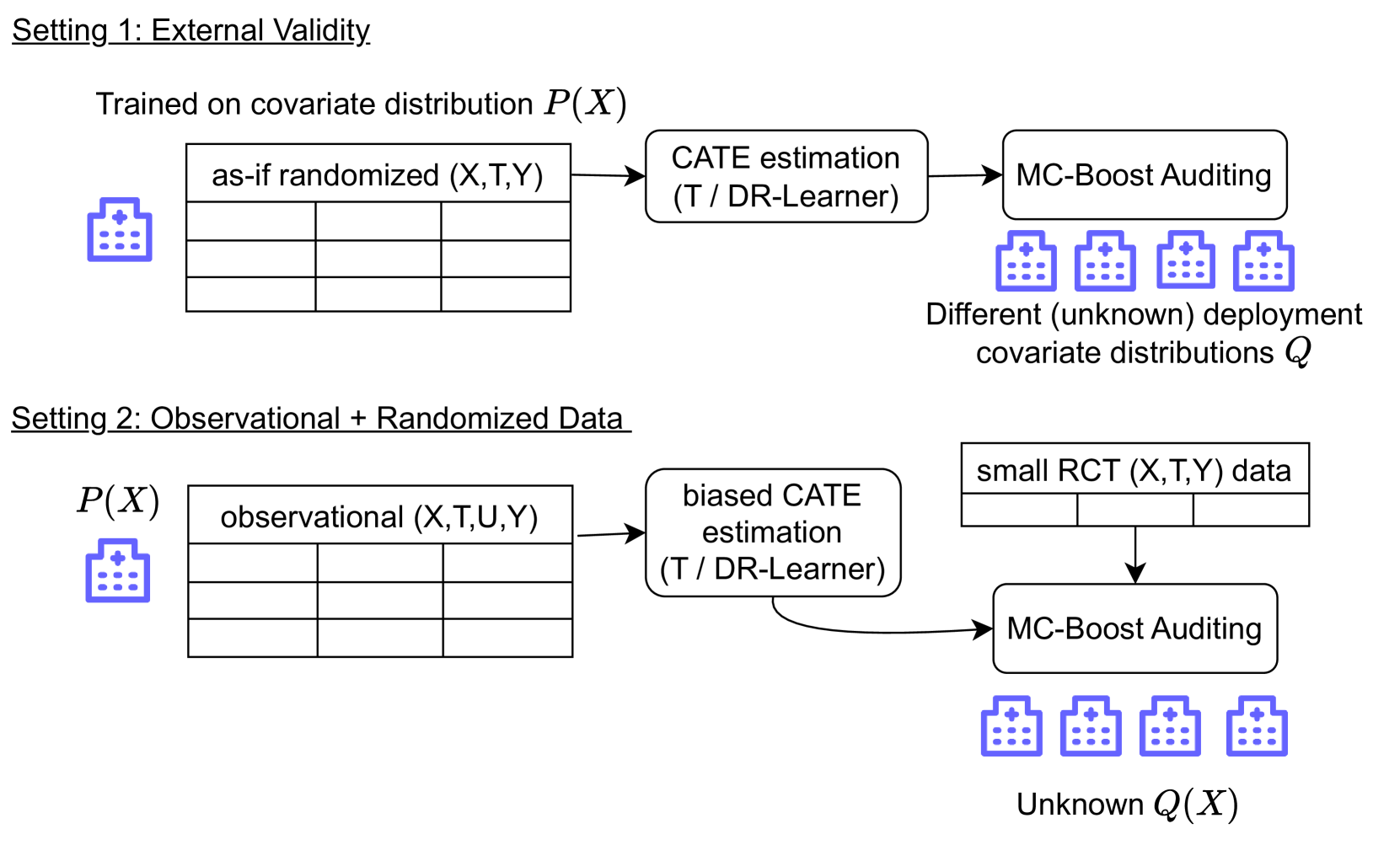
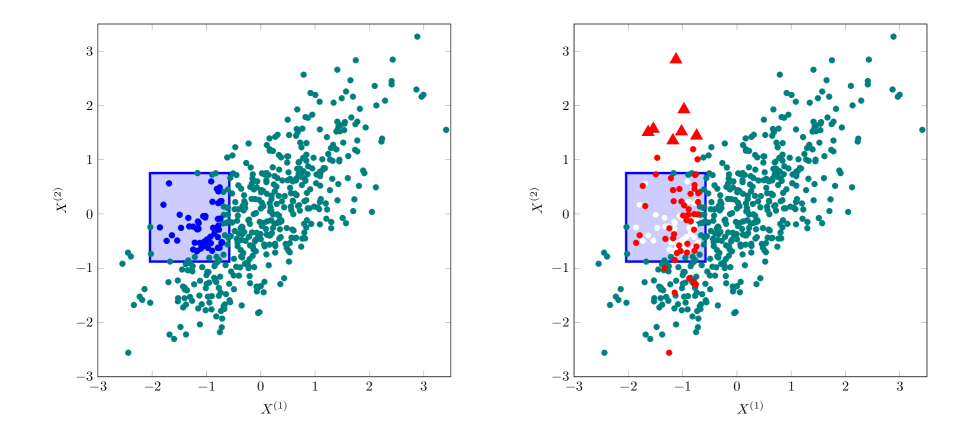
Estimating heterogeneous treatment effects is important to tailor treatments to those individuals who would most likely benefit. However, conditional average treatment effect predictors may often be trained on one population but possibly deployed on different, possibly unknown populations. We use methodology for learning multi-accurate predictors to post-process CATE T-learners (differenced regressions) to become robust to unknown covariate shifts at the time of deployment. The method works in general for pseudo-outcome regression, such as the DR-learner. We show how this approach can combine (large) confounded observational and (smaller) randomized datasets by learning a confounded predictor from the observational dataset, and auditing for multi-accuracy on the randomized controlled trial. We show improvements in bias and mean squared error in simulations with increasingly larger covariate shift, and on a semi-synthetic case study of a parallel large observational study and smaller randomized controlled experiment. Overall, we establish a connection between methods developed for multi-distribution learning and achieve appealing desiderata (e.g. external validity) in causal inference and machine learning.
Read more5/29/2024
📈
0
Empirical Analysis of Model Selection for Heterogeneous Causal Effect Estimation
Divyat Mahajan, Ioannis Mitliagkas, Brady Neal, Vasilis Syrgkanis
We study the problem of model selection in causal inference, specifically for conditional average treatment effect (CATE) estimation. Unlike machine learning, there is no perfect analogue of cross-validation for model selection as we do not observe the counterfactual potential outcomes. Towards this, a variety of surrogate metrics have been proposed for CATE model selection that use only observed data. However, we do not have a good understanding regarding their effectiveness due to limited comparisons in prior studies. We conduct an extensive empirical analysis to benchmark the surrogate model selection metrics introduced in the literature, as well as the novel ones introduced in this work. We ensure a fair comparison by tuning the hyperparameters associated with these metrics via AutoML, and provide more detailed trends by incorporating realistic datasets via generative modeling. Our analysis suggests novel model selection strategies based on careful hyperparameter selection of CATE estimators and causal ensembling.
Read more4/30/2024
0
Model-independent variable selection via the rule-based variable priorit
Min Lu, Hemant Ishwaran
While achieving high prediction accuracy is a fundamental goal in machine learning, an equally important task is finding a small number of features with high explanatory power. One popular selection technique is permutation importance, which assesses a variable's impact by measuring the change in prediction error after permuting the variable. However, this can be problematic due to the need to create artificial data, a problem shared by other methods as well. Another problem is that variable selection methods can be limited by being model-specific. We introduce a new model-independent approach, Variable Priority (VarPro), which works by utilizing rules without the need to generate artificial data or evaluate prediction error. The method is relatively easy to use, requiring only the calculation of sample averages of simple statistics, and can be applied to many data settings, including regression, classification, and survival. We investigate the asymptotic properties of VarPro and show, among other things, that VarPro has a consistent filtering property for noise variables. Empirical studies using synthetic and real-world data show the method achieves a balanced performance and compares favorably to many state-of-the-art procedures currently used for variable selection.
Read more9/17/2024