Model-agnostic variable importance for predictive uncertainty: an entropy-based approach
2310.12842
0
0
🔍
Abstract
In order to trust the predictions of a machine learning algorithm, it is necessary to understand the factors that contribute to those predictions. In the case of probabilistic and uncertainty-aware models, it is necessary to understand not only the reasons for the predictions themselves, but also the reasons for the model's level of confidence in those predictions. In this paper, we show how existing methods in explainability can be extended to uncertainty-aware models and how such extensions can be used to understand the sources of uncertainty in a model's predictive distribution. In particular, by adapting permutation feature importance, partial dependence plots, and individual conditional expectation plots, we demonstrate that novel insights into model behaviour may be obtained and that these methods can be used to measure the impact of features on both the entropy of the predictive distribution and the log-likelihood of the ground truth labels under that distribution. With experiments using both synthetic and real-world data, we demonstrate the utility of these approaches to understand both the sources of uncertainty and their impact on model performance.
Create account to get full access
Overview
- This paper explores how existing methods in explainability can be extended to probabilistic, uncertainty-aware machine learning models.
- The authors demonstrate techniques like permutation feature importance, partial dependence plots, and individual conditional expectation plots can be used to understand the sources of uncertainty in a model's predictions.
- Experiments on both synthetic and real-world data show the utility of these approaches for analyzing model behavior and the impact of features on uncertainty.
Plain English Explanation
When using machine learning models, it's important to understand not just the predictions themselves, but also how confident the model is in those predictions. This is especially true for probabilistic models that output a distribution of possible outcomes rather than a single prediction.
The researchers in this paper looked at ways to "open the black box" of these uncertainty-aware models and see what factors are driving both the predictions and the model's confidence levels. They adapted existing explainability techniques like permutation feature importance and partial dependence plots to work with probabilistic models.
By applying these extended techniques, the researchers were able to gain novel insights into model behavior. They could see how different input features affected not just the predictions, but also the model's overall uncertainty about those predictions. This provides valuable information that can help build trust in the model's outputs.
The experiments covered a range of data, from synthetic tests to real-world applications. This demonstrated the broad applicability of the proposed methods for understanding uncertainty in machine learning models.
Technical Explanation
The core of this paper is about adapting existing explainability techniques to work with probabilistic, uncertainty-aware machine learning models. Traditionally, methods like permutation feature importance, partial dependence plots, and individual conditional expectation plots have been used to understand the factors driving a model's predictions.
However, these techniques have typically focused on point estimates rather than full predictive distributions. The researchers in this paper show how these methods can be extended to also capture the impact of features on the model's uncertainty, as measured by the entropy or log-likelihood of the predictive distribution.
Through experiments on both synthetic and real-world datasets, the authors demonstrate the utility of these extended explainability techniques. They are able to uncover novel insights into model behavior, revealing how different input features affect not just the predictions, but also the model's confidence levels.
For example, the partial dependence plots show how features impact both the mean prediction and the spread (uncertainty) of the predictive distribution. And the individual conditional expectation plots can illustrate how the relationship between a feature and the prediction changes depending on the level of uncertainty.
Overall, this work provides a important step forward in making uncertainty-aware models more interpretable and trustworthy. By shedding light on the sources of uncertainty, these explainability techniques can help build user confidence in probabilistic model outputs.
Critical Analysis
The researchers in this paper make a strong case for the need to understand sources of uncertainty in machine learning models, not just the predictions themselves. Their proposed extensions to existing explainability methods are a valuable contribution, as they provide a practical way to gain these insights.
That said, the paper does not address some potential limitations and areas for further research. For example, it's not clear how well these techniques would scale to high-dimensional or very complex models. The computational overhead of some of the methods, like individual conditional expectation plots, may become prohibitive in certain applications.
Additionally, the paper focuses mainly on demonstrating the technical feasibility of the approaches. More work may be needed to fully validate their usefulness in real-world settings, particularly when it comes to building end-user trust and confidence. Comparative studies of different uncertainty quantification methods could help provide that perspective.
Overall, this research represents an important step forward in making uncertainty-aware models more interpretable. By shedding light on the drivers of uncertainty, it lays the groundwork for more robust and trustworthy machine learning systems. Further exploration of the practical implications and limitations would be a valuable area for future work.
Conclusion
This paper introduces novel extensions to existing explainability techniques that enable better understanding of uncertainty-aware machine learning models. By adapting methods like permutation feature importance and partial dependence plots, the researchers demonstrate how to uncover insights into the sources of uncertainty in a model's predictive distribution.
The experiments show the broad applicability of these approaches, from synthetic benchmarks to real-world datasets. This provides a valuable toolkit for building trust and transparency in probabilistic machine learning systems, which is crucial as these models see increasing deployment in high-stakes applications.
Overall, this work represents an important advance in opening the black box of uncertainty-aware models. As machine learning becomes more ubiquitous, empowering users to understand both the predictions and the associated confidence levels will be essential for responsible and trustworthy deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
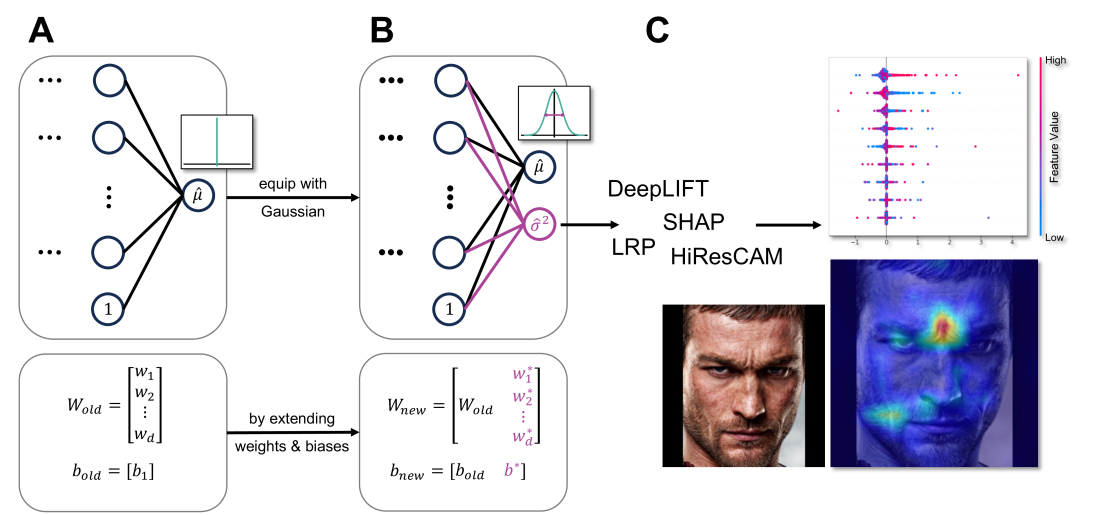
Identifying Drivers of Predictive Aleatoric Uncertainty
Pascal Iversen, Simon Witzke, Katharina Baum, Bernhard Y. Renard
0
0
Explainability and uncertainty quantification are two pillars of trustable artificial intelligence. However, the reasoning behind uncertainty estimates is generally left unexplained. Identifying the drivers of uncertainty complements explanations of point predictions in recognizing model limitations and enhances trust in decisions and their communication. So far, explanations of uncertainties have been rarely studied. The few exceptions rely on Bayesian neural networks or technically intricate approaches, such as auxiliary generative models, thereby hindering their broad adoption. We present a simple approach to explain predictive aleatoric uncertainties. We estimate uncertainty as predictive variance by adapting a neural network with a Gaussian output distribution. Subsequently, we apply out-of-the-box explainers to the model's variance output. This approach can explain uncertainty influences more reliably than literature baselines, which we evaluate in a synthetic setting with a known data-generating process. We further adapt multiple metrics from conventional XAI research to uncertainty explanations. We quantify our findings with a nuanced benchmark analysis that includes real-world datasets. Finally, we apply our approach to an age regression model and discover reasonable sources of uncertainty. Overall, we explain uncertainty estimates with little modifications to the model architecture and demonstrate that our approach competes effectively with more intricate methods.
5/31/2024

Predictability Analysis of Regression Problems via Conditional Entropy Estimations
Yu-Hsueh Fang, Chia-Yen Lee
0
0
In the field of machine learning, regression problems are pivotal due to their ability to predict continuous outcomes. Traditional error metrics like mean squared error, mean absolute error, and coefficient of determination measure model accuracy. The model accuracy is the consequence of the selected model and the features, which blurs the analysis of contribution. Predictability, in the other hand, focus on the predictable level of a target variable given a set of features. This study introduces conditional entropy estimators to assess predictability in regression problems, bridging this gap. We enhance and develop reliable conditional entropy estimators, particularly the KNIFE-P estimator and LMC-P estimator, which offer under- and over-estimation, providing a practical framework for predictability analysis. Extensive experiments on synthesized and real-world datasets demonstrate the robustness and utility of these estimators. Additionally, we extend the analysis to the coefficient of determination (R^2 ), enhancing the interpretability of predictability. The results highlight the effectiveness of KNIFE-P and LMC-P in capturing the achievable performance and limitations of feature sets, providing valuable tools in the development of regression models. These indicators offer a robust framework for assessing the predictability for regression problems.
6/7/2024
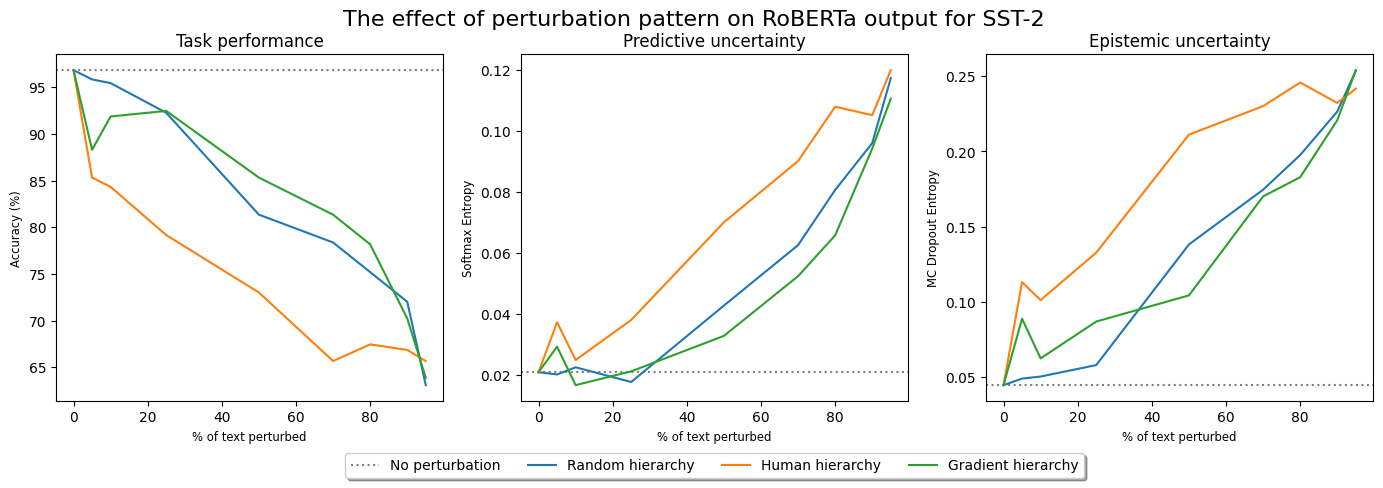
Investigating the Impact of Model Instability on Explanations and Uncertainty
Sara Vera Marjanovi'c, Isabelle Augenstein, Christina Lioma
0
0
Explainable AI methods facilitate the understanding of model behaviour, yet, small, imperceptible perturbations to inputs can vastly distort explanations. As these explanations are typically evaluated holistically, before model deployment, it is difficult to assess when a particular explanation is trustworthy. Some studies have tried to create confidence estimators for explanations, but none have investigated an existing link between uncertainty and explanation quality. We artificially simulate epistemic uncertainty in text input by introducing noise at inference time. In this large-scale empirical study, we insert different levels of noise perturbations and measure the effect on the output of pre-trained language models and different uncertainty metrics. Realistic perturbations have minimal effect on performance and explanations, yet masking has a drastic effect. We find that high uncertainty doesn't necessarily imply low explanation plausibility; the correlation between the two metrics can be moderately positive when noise is exposed during the training process. This suggests that noise-augmented models may be better at identifying salient tokens when uncertain. Furthermore, when predictive and epistemic uncertainty measures are over-confident, the robustness of a saliency map to perturbation can indicate model stability issues. Integrated Gradients shows the overall greatest robustness to perturbation, while still showing model-specific patterns in performance; however, this phenomenon is limited to smaller Transformer-based language models.
6/5/2024

Unified Explanations in Machine Learning Models: A Perturbation Approach
Jacob Dineen, Don Kridel, Daniel Dolk, David Castillo
0
0
A high-velocity paradigm shift towards Explainable Artificial Intelligence (XAI) has emerged in recent years. Highly complex Machine Learning (ML) models have flourished in many tasks of intelligence, and the questions have started to shift away from traditional metrics of validity towards something deeper: What is this model telling me about my data, and how is it arriving at these conclusions? Inconsistencies between XAI and modeling techniques can have the undesirable effect of casting doubt upon the efficacy of these explainability approaches. To address these problems, we propose a systematic, perturbation-based analysis against a popular, model-agnostic method in XAI, SHapley Additive exPlanations (Shap). We devise algorithms to generate relative feature importance in settings of dynamic inference amongst a suite of popular machine learning and deep learning methods, and metrics that allow us to quantify how well explanations generated under the static case hold. We propose a taxonomy for feature importance methodology, measure alignment, and observe quantifiable similarity amongst explanation models across several datasets.
5/31/2024