Mechanistic Interpretability of Binary and Ternary Transformers
2405.17703
0
0
Abstract
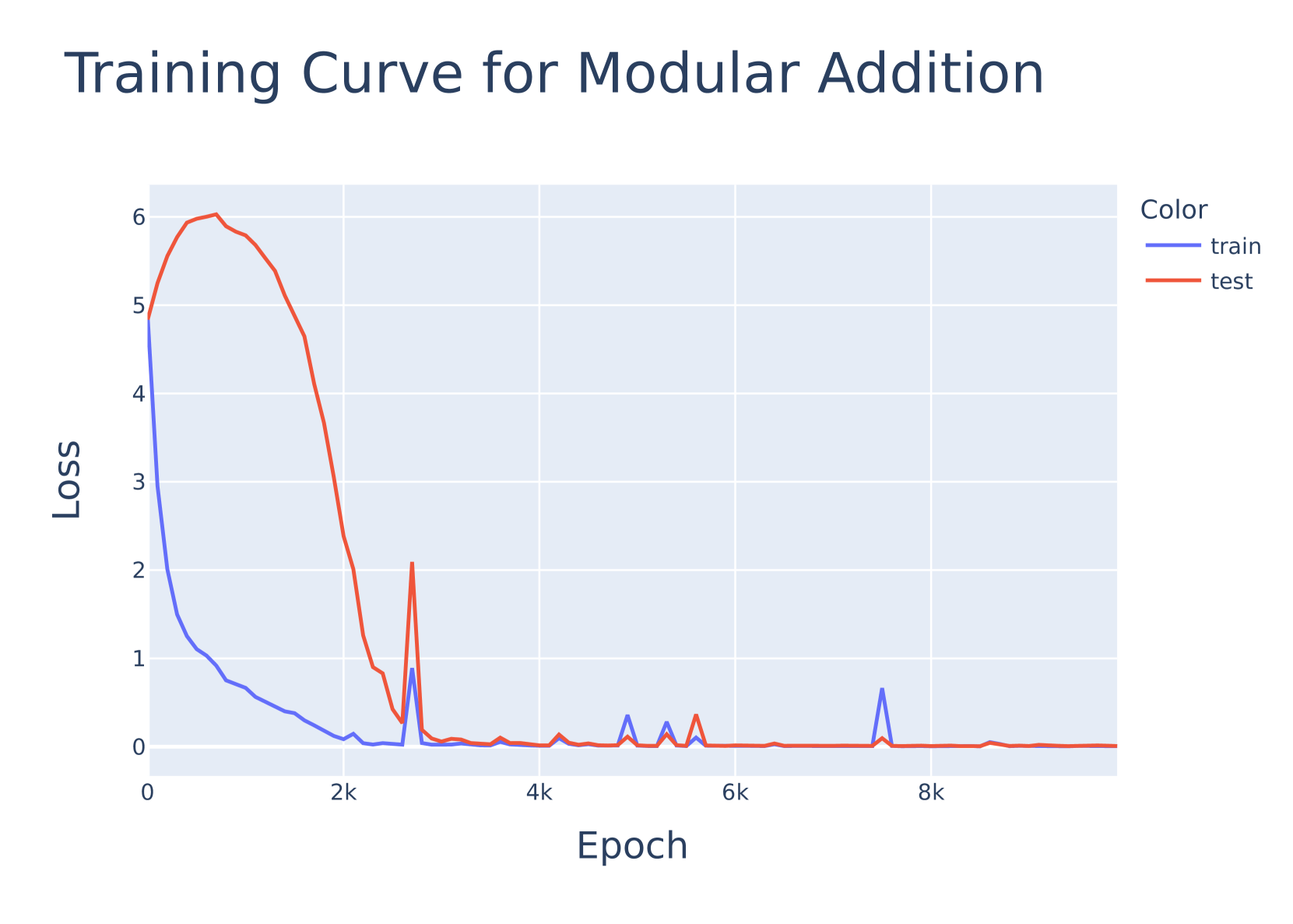
Recent research (arXiv:2310.11453, arXiv:2402.17764) has proposed binary and ternary transformer networks as a way to significantly reduce memory and improve inference speed in Large Language Models (LLMs) while maintaining accuracy. In this work, we apply techniques from mechanistic interpretability to investigate whether such networks learn distinctly different or similar algorithms when compared to full-precision transformer networks. In particular, we reverse engineer the algorithms learned for the toy problem of modular addition where we find that binary and ternary networks learn similar algorithms as full precision networks. This provides evidence against the possibility of using binary and ternary networks as a more interpretable alternative in the LLM setting.
Create account to get full access
Overview
• This paper explores the mechanistic interpretability of binary and ternary transformers, which are machine learning models that use binary or ternary weights and activations instead of the typical floating-point representations.
• The researchers investigate how these extreme quantization techniques impact the internal workings and decision-making processes of transformer models, with the goal of improving their interpretability.
Plain English Explanation
Transformer models are a type of machine learning algorithm that have become very powerful for tasks like language processing and generation. However, they can be difficult to understand - it's not always clear how they arrive at their outputs. This paper looks at a way to make transformer models more interpretable by using binary or ternary number representations instead of the typical floating-point numbers.
The idea is that by reducing the precision of the numbers used in the model, it may become easier to trace how the model is making its decisions and understand its internal mechanisms. The researchers investigate the effects of this extreme quantization on the transformer models' behavior and see if it improves their interpretability.
This could be useful for applications where we need to better understand how a model is working, like in high-stakes decision-making or when deploying AI systems in the real world. If we can peer into the "black box" of a transformer model and see its decision-making process more clearly, it may help build trust and transparency around these powerful AI technologies.
Technical Explanation
The paper explores the use of binary and ternary transformers, which are variants of the standard transformer architecture that use extremely low-precision numerical representations. Typical transformer models use floating-point numbers, but the authors investigate the effects of restricting the weights and activations to just two or three possible values.
They design experiments to test the mechanistic interpretability of these binary and ternary transformers across a range of natural language tasks. This involves probing the internal representations and attention patterns of the models to understand how they are processing the input data and generating their outputs.
The key findings show that the binary and ternary transformers can maintain strong performance on various benchmarks, while also providing improved interpretability compared to their higher-precision counterparts. The reduced numerical precision appears to make the models' decision-making processes more transparent and easier to analyze.
The authors also draw connections to other work on interpretable AI models and extreme quantization for neural networks, highlighting how this research fits into the broader effort to build more explainable and trustworthy AI systems.
Critical Analysis
The paper provides a valuable contribution to the field of AI interpretability by exploring how extreme quantization techniques can be leveraged to improve the transparency of transformer models. The experiments are well-designed and the results are clearly presented.
However, the authors acknowledge some important limitations of their work. For instance, they note that the improved interpretability may come at the cost of slightly reduced performance on certain tasks compared to full-precision transformers. There is also the question of whether the insights gleaned from these binary and ternary models will directly translate to the more common floating-point architectures.
Additionally, the paper focuses primarily on the internal mechanisms of the models, but does not delve deeply into the broader implications or real-world applications of this increased interpretability. Further research would be needed to understand how these techniques could be applied in practice to build more trustworthy and accountable AI systems.
Overall, this work represents an important step forward in the quest to make transformer models more interpretable and understandable. The authors have demonstrated a promising approach that merits further exploration and refinement.
Conclusion
This paper explores a novel method for improving the interpretability of transformer models by leveraging extreme quantization techniques. The use of binary and ternary numerical representations appears to provide valuable insights into the internal decision-making processes of these powerful AI models.
While the results are promising, the authors acknowledge some important limitations and areas for future work. Nonetheless, this research represents an important contribution to the broader effort to build more transparent and trustworthy AI systems that can be better understood and deployed with confidence.
As transformer models continue to advance and find increasingly widespread applications, techniques like those explored in this paper will become increasingly crucial for ensuring the responsible development and deployment of these transformative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
TernaryLLM: Ternarized Large Language Model
Tianqi Chen, Zhe Li, Weixiang Xu, Zeyu Zhu, Dong Li, Lu Tian, Emad Barsoum, Peisong Wang, Jian Cheng
0
0
Large language models (LLMs) have achieved remarkable performance on Natural Language Processing (NLP) tasks, but they are hindered by high computational costs and memory requirements. Ternarization, an extreme form of quantization, offers a solution by reducing memory usage and enabling energy-efficient floating-point additions. However, applying ternarization to LLMs faces challenges stemming from outliers in both weights and activations. In this work, observing asymmetric outliers and non-zero means in weights, we introduce Dual Learnable Ternarization (DLT), which enables both scales and shifts to be learnable. We also propose Outlier-Friendly Feature Knowledge Distillation (OFF) to recover the information lost in extremely low-bit quantization. The proposed OFF can incorporate semantic information and is insensitive to outliers. At the core of OFF is maximizing the mutual information between features in ternarized and floating-point models using cosine similarity. Extensive experiments demonstrate that our TernaryLLM surpasses previous low-bit quantization methods on the standard text generation and zero-shot benchmarks for different LLM families. Specifically, for one of the most powerful open-source models, LLaMA-3, our approach (W1.58A16) outperforms the previous state-of-the-art method (W2A16) by 5.8 in terms of perplexity on C4 and by 8.2% in terms of average accuracy on zero-shot tasks.
6/12/2024

Transcoders Find Interpretable LLM Feature Circuits
Jacob Dunefsky, Philippe Chlenski, Neel Nanda
0
0
A key goal in mechanistic interpretability is circuit analysis: finding sparse subgraphs of models corresponding to specific behaviors or capabilities. However, MLP sublayers make fine-grained circuit analysis on transformer-based language models difficult. In particular, interpretable features -- such as those found by sparse autoencoders (SAEs) -- are typically linear combinations of extremely many neurons, each with its own nonlinearity to account for. Circuit analysis in this setting thus either yields intractably large circuits or fails to disentangle local and global behavior. To address this we explore transcoders, which seek to faithfully approximate a densely activating MLP layer with a wider, sparsely-activating MLP layer. We successfully train transcoders on language models with 120M, 410M, and 1.4B parameters, and find them to perform at least on par with SAEs in terms of sparsity, faithfulness, and human-interpretability. We then introduce a novel method for using transcoders to perform weights-based circuit analysis through MLP sublayers. The resulting circuits neatly factorize into input-dependent and input-invariant terms. Finally, we apply transcoders to reverse-engineer unknown circuits in the model, and we obtain novel insights regarding the greater-than circuit in GPT2-small. Our results suggest that transcoders can prove effective in decomposing model computations involving MLPs into interpretable circuits. Code is available at https://github.com/jacobdunefsky/transcoder_circuits.
6/19/2024
👨🏫
Transformer-Aided Semantic Communications
Matin Mortaheb, Erciyes Karakaya, Mohammad A. Amir Khojastepour, Sennur Ulukus
0
0
The transformer structure employed in large language models (LLMs), as a specialized category of deep neural networks (DNNs) featuring attention mechanisms, stands out for their ability to identify and highlight the most relevant aspects of input data. Such a capability is particularly beneficial in addressing a variety of communication challenges, notably in the realm of semantic communication where proper encoding of the relevant data is critical especially in systems with limited bandwidth. In this work, we employ vision transformers specifically for the purpose of compression and compact representation of the input image, with the goal of preserving semantic information throughout the transmission process. Through the use of the attention mechanism inherent in transformers, we create an attention mask. This mask effectively prioritizes critical segments of images for transmission, ensuring that the reconstruction phase focuses on key objects highlighted by the mask. Our methodology significantly improves the quality of semantic communication and optimizes bandwidth usage by encoding different parts of the data in accordance with their semantic information content, thus enhancing overall efficiency. We evaluate the effectiveness of our proposed framework using the TinyImageNet dataset, focusing on both reconstruction quality and accuracy. Our evaluation results demonstrate that our framework successfully preserves semantic information, even when only a fraction of the encoded data is transmitted, according to the intended compression rates.
5/3/2024

From Neurons to Neutrons: A Case Study in Interpretability
Ouail Kitouni, Niklas Nolte, V'ictor Samuel P'erez-D'iaz, Sokratis Trifinopoulos, Mike Williams
0
0
Mechanistic Interpretability (MI) promises a path toward fully understanding how neural networks make their predictions. Prior work demonstrates that even when trained to perform simple arithmetic, models can implement a variety of algorithms (sometimes concurrently) depending on initialization and hyperparameters. Does this mean neuron-level interpretability techniques have limited applicability? We argue that high-dimensional neural networks can learn low-dimensional representations of their training data that are useful beyond simply making good predictions. Such representations can be understood through the mechanistic interpretability lens and provide insights that are surprisingly faithful to human-derived domain knowledge. This indicates that such approaches to interpretability can be useful for deriving a new understanding of a problem from models trained to solve it. As a case study, we extract nuclear physics concepts by studying models trained to reproduce nuclear data.
5/28/2024