Transformer-Aided Semantic Communications
2405.01521
0
0
👨🏫
Abstract
The transformer structure employed in large language models (LLMs), as a specialized category of deep neural networks (DNNs) featuring attention mechanisms, stands out for their ability to identify and highlight the most relevant aspects of input data. Such a capability is particularly beneficial in addressing a variety of communication challenges, notably in the realm of semantic communication where proper encoding of the relevant data is critical especially in systems with limited bandwidth. In this work, we employ vision transformers specifically for the purpose of compression and compact representation of the input image, with the goal of preserving semantic information throughout the transmission process. Through the use of the attention mechanism inherent in transformers, we create an attention mask. This mask effectively prioritizes critical segments of images for transmission, ensuring that the reconstruction phase focuses on key objects highlighted by the mask. Our methodology significantly improves the quality of semantic communication and optimizes bandwidth usage by encoding different parts of the data in accordance with their semantic information content, thus enhancing overall efficiency. We evaluate the effectiveness of our proposed framework using the TinyImageNet dataset, focusing on both reconstruction quality and accuracy. Our evaluation results demonstrate that our framework successfully preserves semantic information, even when only a fraction of the encoded data is transmitted, according to the intended compression rates.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper explores the use of transformer structures in large language models (LLMs) for semantic communication and image compression.
- It focuses on employing vision transformers to create an attention mask that prioritizes critical segments of images for transmission, preserving semantic information.
- The goal is to improve the quality of semantic communication and optimize bandwidth usage by encoding data based on its semantic importance.
Plain English Explanation
Transformers are a type of deep learning model that excel at identifying the most relevant parts of input data. This capability is particularly useful for semantic communication, where it's critical to properly encode the most important information, especially when dealing with limited bandwidth.
In this research, the authors use vision transformers specifically for image compression. By creating an attention mask, the transformer model can identify the key elements in an image that are most important for preserving the overall meaning or semantic information. This allows the system to focus on transmitting those critical parts of the image, while compressing the less important areas.
The end result is that the reconstructed image maintains high quality and accuracy, even when only a portion of the original data is transmitted. This improves the efficiency of the communication process by using the available bandwidth more effectively.
Technical Explanation
The researchers employed vision transformers to create an attention mask for images. This mask prioritizes the most semantically relevant segments of the image, ensuring that the reconstruction process focuses on preserving those critical elements.
By leveraging the attention mechanism inherent in transformers, the model can identify the key objects and features in the input image that are most important for maintaining the overall meaning and context. This attention-aware approach to encoding the image data allows the system to transmit only the most necessary information, optimizing bandwidth usage.
The authors evaluated their framework using the TinyImageNet dataset, assessing both the reconstruction quality and the accuracy of the system. Their results demonstrate that the proposed method successfully preserves the semantic information in the images, even when transmitting only a fraction of the original encoded data, according to the desired compression rates.
Critical Analysis
The paper presents a novel and promising approach to improving the efficiency of semantic communication through the use of transformers and attention-aware image compression. However, there are a few potential limitations and areas for further research:
-
The evaluation was limited to the TinyImageNet dataset, which may not fully capture the complexities and diversity of real-world image data. Expanding the testing to larger, more varied datasets could help validate the generalizability of the approach.
-
The paper does not address the computational complexity and inference time of the proposed framework, which could be an important consideration for real-time or resource-constrained applications. Exploring ways to further optimize the model's efficiency could be a valuable area of investigation.
-
The paper does not delve into the potential biases or limitations of the attention mechanism itself, which could impact the accuracy and fairness of the semantic preservation. Deeper analysis of these aspects could enhance the robustness and reliability of the system.
Conclusion
This research explores the use of transformer-based models for semantic image compression, showcasing their ability to prioritize the most relevant information and optimize bandwidth usage. By creating an attention mask that highlights the critical elements of an image, the proposed framework can preserve the overall semantic meaning and context, even when transmitting only a fraction of the original data.
The findings demonstrate the potential of transformers for enhancing the efficiency and effectiveness of semantic communication systems, which could have far-reaching implications for a variety of applications, from remote sensing and telemedicine to multimedia streaming and autonomous systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Survey on Transformer Compression
Yehui Tang, Yunhe Wang, Jianyuan Guo, Zhijun Tu, Kai Han, Hailin Hu, Dacheng Tao
0
0
Transformer plays a vital role in the realms of natural language processing (NLP) and computer vision (CV), specially for constructing large language models (LLM) and large vision models (LVM). Model compression methods reduce the memory and computational cost of Transformer, which is a necessary step to implement large language/vision models on practical devices. Given the unique architecture of Transformer, featuring alternative attention and feedforward neural network (FFN) modules, specific compression techniques are usually required. The efficiency of these compression methods is also paramount, as retraining large models on the entire training dataset is usually impractical. This survey provides a comprehensive review of recent compression methods, with a specific focus on their application to Transformer-based models. The compression methods are primarily categorized into pruning, quantization, knowledge distillation, and efficient architecture design (Mamba, RetNet, RWKV, etc.). In each category, we discuss compression methods for both language and vision tasks, highlighting common underlying principles. Finally, we delve into the relation between various compression methods, and discuss further directions in this domain.
4/9/2024
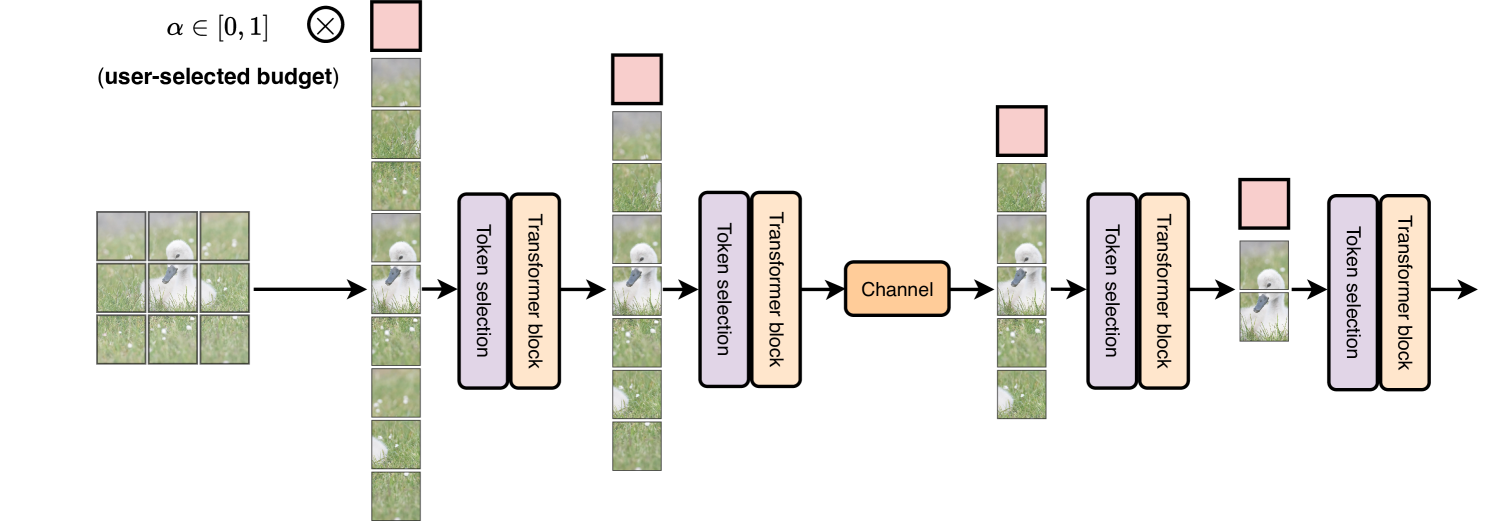
Adaptive Semantic Token Selection for AI-native Goal-oriented Communications
Alessio Devoto, Simone Petruzzi, Jary Pomponi, Paolo Di Lorenzo, Simone Scardapane
0
0
In this paper, we propose a novel design for AI-native goal-oriented communications, exploiting transformer neural networks under dynamic inference constraints on bandwidth and computation. Transformers have become the standard architecture for pretraining large-scale vision and text models, and preliminary results have shown promising performance also in deep joint source-channel coding (JSCC). Here, we consider a dynamic model where communication happens over a channel with variable latency and bandwidth constraints. Leveraging recent works on conditional computation, we exploit the structure of the transformer blocks and the multihead attention operator to design a trainable semantic token selection mechanism that learns to select relevant tokens (e.g., image patches) from the input signal. This is done dynamically, on a per-input basis, with a rate that can be chosen as an additional input by the user. We show that our model improves over state-of-the-art token selection mechanisms, exhibiting high accuracy for a wide range of latency and bandwidth constraints, without the need for deploying multiple architectures tailored to each constraint. Last, but not least, the proposed token selection mechanism helps extract powerful semantics that are easy to understand and explain, paving the way for interpretable-by-design models for the next generation of AI-native communication systems.
5/7/2024

Attention-aware Semantic Communications for Collaborative Inference
Jiwoong Im, Nayoung Kwon, Taewoo Park, Jiheon Woo, Jaeho Lee, Yongjune Kim
0
0
We propose a communication-efficient collaborative inference framework in the domain of edge inference, focusing on the efficient use of vision transformer (ViTs) models. The partitioning strategy of conventional collaborative inference fails to reduce communication cost because of the inherent architecture of ViTs maintaining consistent layer dimensions across the entire transformer encoder. Therefore, instead of employing the partitioning strategy, our framework utilizes a lightweight ViT model on the edge device, with the server deploying a complicated ViT model. To enhance communication efficiency and achieve the classification accuracy of the server model, we propose two strategies: 1) attention-aware patch selection and 2) entropy-aware image transmission. Attention-aware patch selection leverages the attention scores generated by the edge device's transformer encoder to identify and select the image patches critical for classification. This strategy enables the edge device to transmit only the essential patches to the server, significantly improving communication efficiency. Entropy-aware image transmission uses min-entropy as a metric to accurately determine whether to depend on the lightweight model on the edge device or to request the inference from the server model. In our framework, the lightweight ViT model on the edge device acts as a semantic encoder, efficiently identifying and selecting the crucial image information required for the classification task. Our experiments demonstrate that the proposed collaborative inference framework can reduce communication overhead by 68% with only a minimal loss in accuracy compared to the server model.
4/12/2024
New!Language-Oriented Semantic Latent Representation for Image Transmission
Giordano Cicchetti, Eleonora Grassucci, Jihong Park, Jinho Choi, Sergio Barbarossa, Danilo Comminiello
0
0
In the new paradigm of semantic communication (SC), the focus is on delivering meanings behind bits by extracting semantic information from raw data. Recent advances in data-to-text models facilitate language-oriented SC, particularly for text-transformed image communication via image-to-text (I2T) encoding and text-to-image (T2I) decoding. However, although semantically aligned, the text is too coarse to precisely capture sophisticated visual features such as spatial locations, color, and texture, incurring a significant perceptual difference between intended and reconstructed images. To address this limitation, in this paper, we propose a novel language-oriented SC framework that communicates both text and a compressed image embedding and combines them using a latent diffusion model to reconstruct the intended image. Experimental results validate the potential of our approach, which transmits only 2.09% of the original image size while achieving higher perceptual similarities in noisy communication channels compared to a baseline SC method that communicates only through text.The code is available at https://github.com/ispamm/Img2Img-SC/ .
5/17/2024