HuatuoGPT-Vision, Towards Injecting Medical Visual Knowledge into Multimodal LLMs at Scale
2406.19280
0
0

Abstract
The rapid development of multimodal large language models (MLLMs), such as GPT-4V, has led to significant advancements. However, these models still face challenges in medical multimodal capabilities due to limitations in the quantity and quality of medical vision-text data, stemming from data privacy concerns and high annotation costs. While pioneering approaches utilize PubMed's large-scale, de-identified medical image-text pairs to address these limitations, they still fall short due to inherent data noise. To tackle this, we refined medical image-text pairs from PubMed and employed MLLMs (GPT-4V) in an 'unblinded' capacity to denoise and reformat the data, resulting in the creation of the PubMedVision dataset with 1.3 million medical VQA samples. Our validation demonstrates that: (1) PubMedVision can significantly enhance the medical multimodal capabilities of current MLLMs, showing significant improvement in benchmarks including the MMMU Health & Medicine track; (2) manual checks by medical experts and empirical results validate the superior data quality of our dataset compared to other data construction methods. Using PubMedVision, we train a 34B medical MLLM HuatuoGPT-Vision, which shows superior performance in medical multimodal scenarios among open-source MLLMs.
Create account to get full access
Overview
- The paper describes HuatuoGPT-Vision, a system that aims to inject medical visual knowledge into multimodal large language models (MLLMs) at scale.
- The key goal is to improve the performance of MLLMs on medical-related tasks by leveraging visual information from medical images.
- The paper explores methods for aligning visual and textual knowledge in MLLMs to enhance their understanding and reasoning capabilities in the medical domain.
Plain English Explanation
The researchers developed a system called HuatuoGPT-Vision to help large language models (LLMs) that can work with both text and images, known as multimodal LLMs (MLLMs), become better at medical-related tasks.
LLMs are powerful AI models that can understand and generate human-like text, but they often lack specific knowledge about the medical field. The researchers wanted to find a way to give these models more medical expertise, especially when it comes to understanding medical images like X-rays or CT scans.
Their approach was to try to "align" the visual and textual knowledge inside the MLLMs. This means they wanted to help the models better connect the information they get from medical images with the information they get from medical text. By doing this, the researchers hoped the MLLMs would be able to reason about medical topics more accurately and provide better outputs for tasks like medical report generation or question answering.
The paper explores different techniques for achieving this visual-textual alignment in MLLMs, with the goal of improving the models' performance on a wide range of medical-related applications.
Technical Explanation
The paper introduces HuatuoGPT-Vision, a system that aims to enhance multimodal large language models (MLLMs) by injecting medical visual knowledge at scale.
The key idea is to improve the performance of MLLMs on medical-related tasks by aligning the visual and textual knowledge within the models. This is achieved through a set of techniques, including:
- Multimodal Pretraining: The researchers propose pretraining MLLMs on large-scale medical image-text datasets to establish stronger connections between visual and textual information.
- Multimodal Finetuning: They explore methods for finetuning MLLMs on specialized medical datasets, further reinforcing the alignment between the visual and textual modalities.
- Multimodal Prompting: The paper investigates the use of prompted multimodal inputs to help MLLMs leverage both visual and textual cues for improved medical reasoning and task performance.
The proposed approaches are evaluated on a range of medical-focused benchmarks, demonstrating the effectiveness of HuatuoGPT-Vision in enhancing the medical capabilities of MLLMs. The methods show promise for advancing the state-of-the-art in areas like medical report generation and high-resolution vision-language models for biomedicine.
Critical Analysis
The paper presents a well-designed study that tackles an important challenge in the field of medical AI – improving the medical domain knowledge of large language models. The proposed techniques for visual-textual alignment in MLLMs seem promising, and the evaluation on medical-focused benchmarks provides a solid foundation for the claims made.
However, the paper also acknowledges some limitations and areas for further research. For instance, the presented methods may be computationally expensive and require large-scale medical image-text datasets, which can be challenging to obtain. Additionally, the paper does not address potential biases or errors that could be introduced by relying on medical visual data, which is an important consideration for real-world deployment of such systems.
Further research could explore more efficient pretraining and finetuning strategies, as well as techniques for mitigating potential biases in the underlying data and models. Investigating the generalizability of the proposed approaches to different medical domains and tasks would also be valuable.
Overall, the HuatuoGPT-Vision system represents a promising step towards injecting medical visual knowledge into multimodal LLMs at scale, with the potential to significantly advance the state-of-the-art in medical AI applications.
Conclusion
The HuatuoGPT-Vision paper presents a novel approach for enhancing multimodal large language models with medical visual knowledge. By aligning the visual and textual information within these models, the researchers aim to improve their performance on a variety of medical-related tasks, such as medical report generation and question answering.
The proposed techniques, including multimodal pretraining, finetuning, and prompted inputs, show promising results on medical benchmarks. While the approach has some limitations in terms of computational costs and potential biases, the work represents an important step forward in the quest to build more capable and knowledgeable AI systems for the medical domain.
As the field of medical AI continues to evolve, the insights and methods introduced in the HuatuoGPT-Vision paper can serve as a foundation for further advancements, potentially leading to more accurate, reliable, and accessible healthcare technologies in the years to come.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

An Early Investigation into the Utility of Multimodal Large Language Models in Medical Imaging
Sulaiman Khan, Md. Rafiul Biswas, Alina Murad, Hazrat Ali, Zubair Shah
0
0
Recent developments in multimodal large language models (MLLMs) have spurred significant interest in their potential applications across various medical imaging domains. On the one hand, there is a temptation to use these generative models to synthesize realistic-looking medical image data, while on the other hand, the ability to identify synthetic image data in a pool of data is also significantly important. In this study, we explore the potential of the Gemini (textit{gemini-1.0-pro-vision-latest}) and GPT-4V (gpt-4-vision-preview) models for medical image analysis using two modalities of medical image data. Utilizing synthetic and real imaging data, both Gemini AI and GPT-4V are first used to classify real versus synthetic images, followed by an interpretation and analysis of the input images. Experimental results demonstrate that both Gemini and GPT-4 could perform some interpretation of the input images. In this specific experiment, Gemini was able to perform slightly better than the GPT-4V on the classification task. In contrast, responses associated with GPT-4V were mostly generic in nature. Our early investigation presented in this work provides insights into the potential of MLLMs to assist with the classification and interpretation of retinal fundoscopy and lung X-ray images. We also identify key limitations associated with the early investigation study on MLLMs for specialized tasks in medical image analysis.
6/4/2024
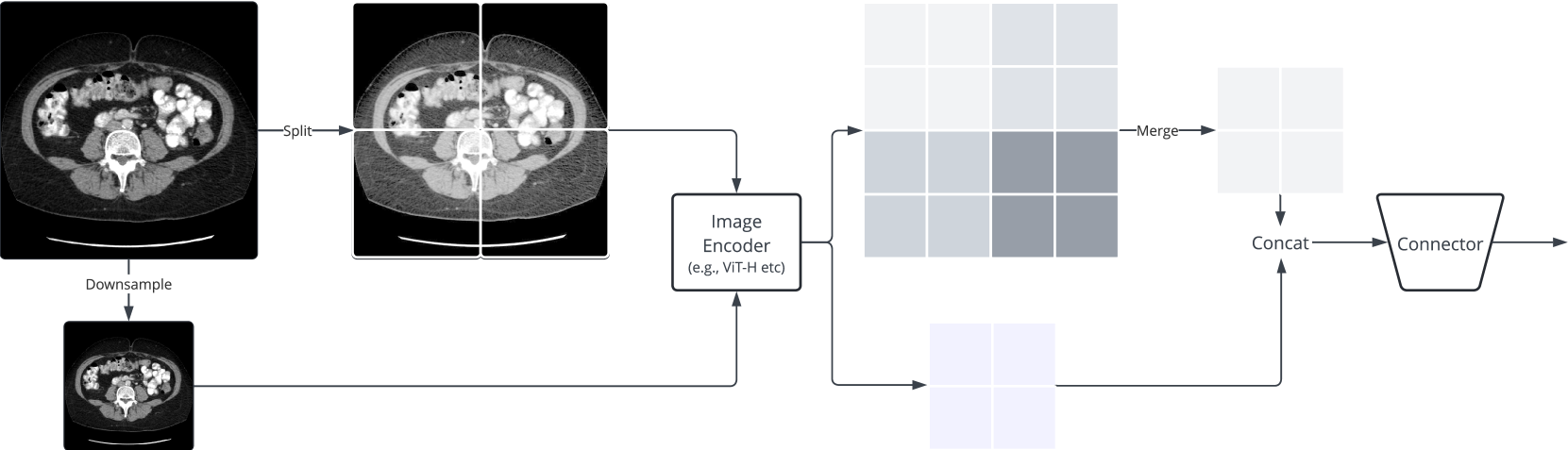
Advancing High Resolution Vision-Language Models in Biomedicine
Zekai Chen, Arda Pekis, Kevin Brown
0
0
Multi-modal learning has significantly advanced generative AI, especially in vision-language modeling. Innovations like GPT-4V and open-source projects such as LLaVA have enabled robust conversational agents capable of zero-shot task completions. However, applying these technologies in the biomedical field presents unique challenges. Recent initiatives like LLaVA-Med have started to adapt instruction-tuning for biomedical contexts using large datasets such as PMC-15M. Our research offers three key contributions: (i) we present a new instruct dataset enriched with medical image-text pairs from Claude3-Opus and LLaMA3 70B, (ii) we propose a novel image encoding strategy using hierarchical representations to improve fine-grained biomedical visual comprehension, and (iii) we develop the Llama3-Med model, which achieves state-of-the-art zero-shot performance on biomedical visual question answering benchmarks, with an average performance improvement of over 10% compared to previous methods. These advancements provide more accurate and reliable tools for medical professionals, bridging gaps in current multi-modal conversational assistants and promoting further innovations in medical AI.
6/17/2024
PeFoMed: Parameter Efficient Fine-tuning of Multimodal Large Language Models for Medical Imaging
Gang Liu, Jinlong He, Pengfei Li, Genrong He, Zhaolin Chen, Shenjun Zhong
0
0
Multimodal large language models (MLLMs) represent an evolutionary expansion in the capabilities of traditional large language models, enabling them to tackle challenges that surpass the scope of purely text-based applications. It leverages the knowledge previously encoded within these language models, thereby enhancing their applicability and functionality in the reign of multimodal contexts. Recent works investigate the adaptation of MLLMs as a universal solution to address medical multi-modal problems as a generative task. In this paper, we propose a parameter efficient framework for fine-tuning MLLMs, specifically validated on medical visual question answering (Med-VQA) and medical report generation (MRG) tasks, using public benchmark datasets. We also introduce an evaluation metric using the 5-point Likert scale and its weighted average value to measure the quality of the generated reports for MRG tasks, where the scale ratings are labelled by both humans manually and the GPT-4 model. We further assess the consistency of performance metrics across traditional measures, GPT-4, and human ratings for both VQA and MRG tasks. The results indicate that semantic similarity assessments using GPT-4 align closely with human annotators and provide greater stability, yet they reveal a discrepancy when compared to conventional lexical similarity measurements. This questions the reliability of lexical similarity metrics for evaluating the performance of generative models in Med-VQA and report generation tasks. Besides, our fine-tuned model significantly outperforms GPT-4v. This indicates that without additional fine-tuning, multi-modal models like GPT-4v do not perform effectively on medical imaging tasks. The code will be available here: https://github.com/jinlHe/PeFoMed.
4/17/2024
🎯
Hidden Flaws Behind Expert-Level Accuracy of GPT-4 Vision in Medicine
Qiao Jin, Fangyuan Chen, Yiliang Zhou, Ziyang Xu, Justin M. Cheung, Robert Chen, Ronald M. Summers, Justin F. Rousseau, Peiyun Ni, Marc J Landsman, Sally L. Baxter, Subhi J. Al'Aref, Yijia Li, Alex Chen, Josef A. Brejt, Michael F. Chiang, Yifan Peng, Zhiyong Lu
0
0
Recent studies indicate that Generative Pre-trained Transformer 4 with Vision (GPT-4V) outperforms human physicians in medical challenge tasks. However, these evaluations primarily focused on the accuracy of multi-choice questions alone. Our study extends the current scope by conducting a comprehensive analysis of GPT-4V's rationales of image comprehension, recall of medical knowledge, and step-by-step multimodal reasoning when solving New England Journal of Medicine (NEJM) Image Challenges - an imaging quiz designed to test the knowledge and diagnostic capabilities of medical professionals. Evaluation results confirmed that GPT-4V performs comparatively to human physicians regarding multi-choice accuracy (81.6% vs. 77.8%). GPT-4V also performs well in cases where physicians incorrectly answer, with over 78% accuracy. However, we discovered that GPT-4V frequently presents flawed rationales in cases where it makes the correct final choices (35.5%), most prominent in image comprehension (27.2%). Regardless of GPT-4V's high accuracy in multi-choice questions, our findings emphasize the necessity for further in-depth evaluations of its rationales before integrating such multimodal AI models into clinical workflows.
4/24/2024