MELD-ST: An Emotion-aware Speech Translation Dataset

0
🗣️
Sign in to get full access
Overview
- This paper highlights the importance of incorporating emotion into speech translation systems.
- The researchers introduce the MELD-ST dataset, which includes English-to-Japanese and English-to-German language pairs with emotion annotations.
- Baseline experiments using the SeamlessM4T model suggest that incorporating emotion labels can improve translation performance in certain situations, underscoring the need for further research in this area.
Plain English Explanation
When people talk, the way they say things (their tone, pitch, and rhythm) can convey emotion, like happiness, sadness, or anger. This emotional information is important for understanding the full meaning of what someone is saying.
The researchers in this paper wanted to see if taking emotion into account could help improve the quality of machine translation, where a computer translates speech from one language to another. They created a dataset called MELD-ST, which has a collection of English conversations translated into Japanese and German, with each utterance labeled for the emotional state of the speaker.
By testing a translation model on this dataset, the researchers found that fine-tuning the model with the emotion labels could sometimes improve the quality of the translations. This suggests that emotion is an important factor to consider when building speech translation systems.
The researchers think more work is needed to better understand how to effectively incorporate emotion into these types of translation models, to make them more accurate and natural-sounding.
Technical Explanation
The paper presents the MELD-ST dataset, which consists of English-to-Japanese and English-to-German speech translation data, with each utterance annotated for the speaker's emotional state using labels from the MELD emotion dataset.
The researchers conduct baseline experiments using the SeamlessM4T speech translation model, testing its performance on the MELD-ST dataset with and without fine-tuning on the emotion labels. The results indicate that incorporating emotion can enhance translation quality in certain settings, highlighting the need for further advancements in emotion-aware speech translation systems.
Critical Analysis
The paper provides a valuable dataset and initial insights into the role of emotion in speech translation, but there are some limitations and areas for further exploration:
- The dataset is relatively small, with only around 10,000 utterances per language pair, which may limit the ability to robustly train and evaluate emotion-aware translation models.
- The paper only tests a single baseline model, the SeamlessM4T, and does not explore other architectural approaches that may be better suited for incorporating emotional information.
- The analysis of the impact of emotion on translation quality is high-level, and more in-depth investigation is needed to understand the specific types of utterances or emotional states where emotion-aware translation provides the greatest benefits.
Overall, this work sets the stage for further research into emotion-aware speech translation, but additional datasets, models, and analyses will be required to fully unlock the potential of this capability.
Conclusion
This paper underscores the importance of considering emotion in speech translation systems. By introducing the MELD-ST dataset and conducting baseline experiments, the researchers demonstrate that incorporating emotional information can enhance translation performance in certain scenarios. While more work is needed to fully realize the benefits of emotion-aware speech translation, this study highlights a promising direction for future research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
MELD-ST: An Emotion-aware Speech Translation Dataset
Sirou Chen, Sakiko Yahata, Shuichiro Shimizu, Zhengdong Yang, Yihang Li, Chenhui Chu, Sadao Kurohashi
Emotion plays a crucial role in human conversation. This paper underscores the significance of considering emotion in speech translation. We present the MELD-ST dataset for the emotion-aware speech translation task, comprising English-to-Japanese and English-to-German language pairs. Each language pair includes about 10,000 utterances annotated with emotion labels from the MELD dataset. Baseline experiments using the SeamlessM4T model on the dataset indicate that fine-tuning with emotion labels can enhance translation performance in some settings, highlighting the need for further research in emotion-aware speech translation systems.
Read more5/24/2024

0
Usefulness of Emotional Prosody in Neural Machine Translation
Charles Brazier, Jean-Luc Rouas
Neural Machine Translation (NMT) is the task of translating a text from one language to another with the use of a trained neural network. Several existing works aim at incorporating external information into NMT models to improve or control predicted translations (e.g. sentiment, politeness, gender). In this work, we propose to improve translation quality by adding another external source of information: the automatically recognized emotion in the voice. This work is motivated by the assumption that each emotion is associated with a specific lexicon that can overlap between emotions. Our proposed method follows a two-stage procedure. At first, we select a state-of-the-art Speech Emotion Recognition (SER) model to predict dimensional emotion values from all input audio in the dataset. Then, we use these predicted emotions as source tokens added at the beginning of input texts to train our NMT model. We show that integrating emotion information, especially arousal, into NMT systems leads to better translations.
Read more4/30/2024
🧠
0
Conditioning LLMs with Emotion in Neural Machine Translation
Charles Brazier, Jean-Luc Rouas
Large Language Models (LLMs) have shown remarkable performance in Natural Language Processing tasks, including Machine Translation (MT). In this work, we propose a novel MT pipeline that integrates emotion information extracted from a Speech Emotion Recognition (SER) model into LLMs to enhance translation quality. We first fine-tune five existing LLMs on the Libri-trans dataset and select the most performant model. Subsequently, we augment LLM prompts with different dimensional emotions and train the selected LLM under these different configurations. Our experiments reveal that integrating emotion information, especially arousal, into LLM prompts leads to notable improvements in translation quality.
Read more8/7/2024
0
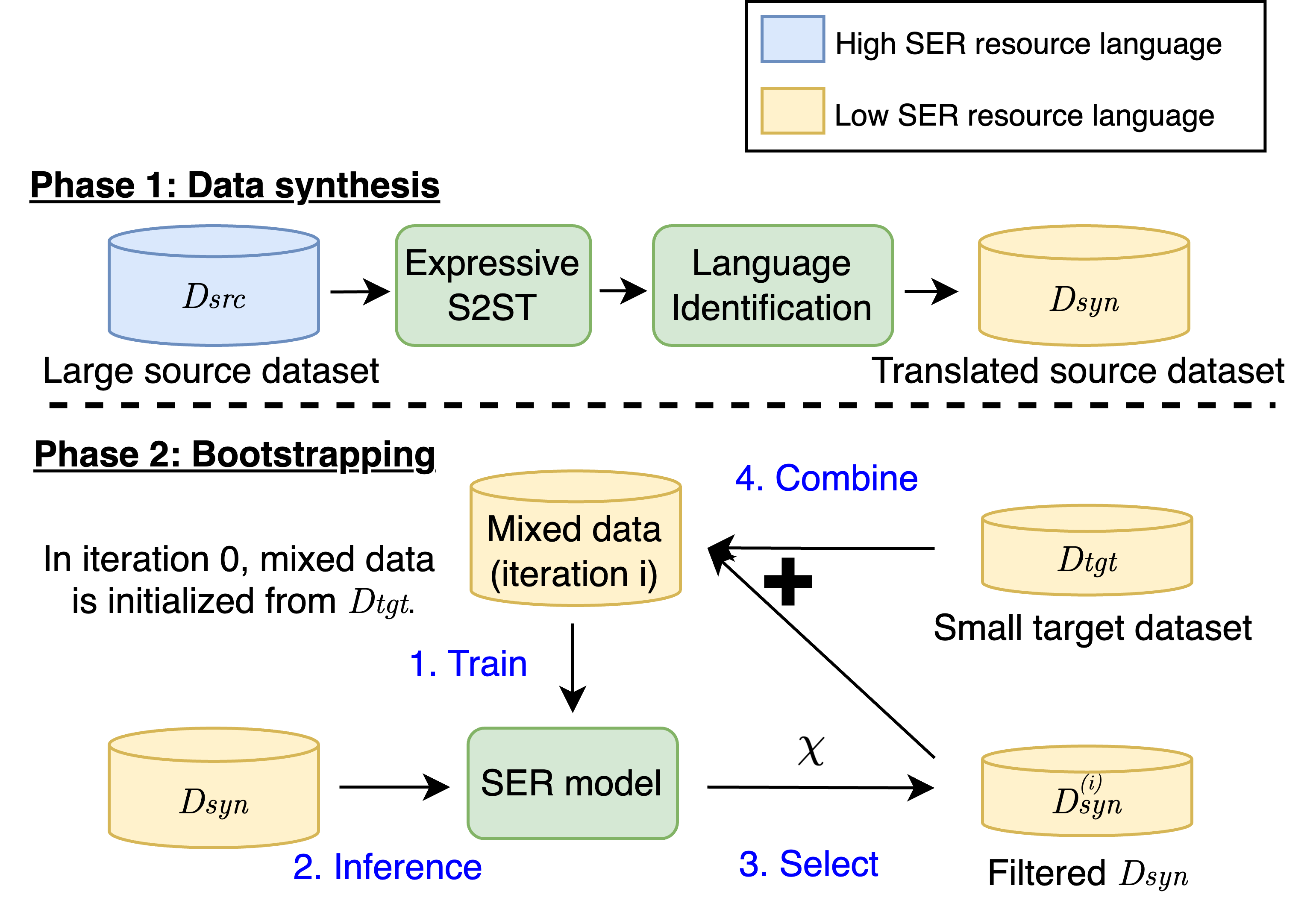
Improving Speech Emotion Recognition in Under-Resourced Languages via Speech-to-Speech Translation with Bootstrapping Data Selection
Hsi-Che Lin, Yi-Cheng Lin, Huang-Cheng Chou, Hung-yi Lee
Speech Emotion Recognition (SER) is a crucial component in developing general-purpose AI agents capable of natural human-computer interaction. However, building robust multilingual SER systems remains challenging due to the scarcity of labeled data in languages other than English and Chinese. In this paper, we propose an approach to enhance SER performance in low SER resource languages by leveraging data from high-resource languages. Specifically, we employ expressive Speech-to-Speech translation (S2ST) combined with a novel bootstrapping data selection pipeline to generate labeled data in the target language. Extensive experiments demonstrate that our method is both effective and generalizable across different upstream models and languages. Our results suggest that this approach can facilitate the development of more scalable and robust multilingual SER systems.
Read more9/18/2024