Improving Speech Emotion Recognition in Under-Resourced Languages via Speech-to-Speech Translation with Bootstrapping Data Selection

0
Sign in to get full access
Overview
- This paper explores a method to improve speech emotion recognition in under-resourced languages using speech-to-speech translation and bootstrapping data selection.
- The key idea is to leverage high-resource languages to enhance emotion recognition in low-resource languages through translation and data augmentation.
- The proposed approach involves translating speech samples from low-resource languages to high-resource languages, training emotion recognition models on the translated data, and then transferring the learned representations back to the original low-resource languages.
Plain English Explanation
Speech emotion recognition is the task of identifying the emotional state of a speaker from their voice. This is a valuable capability for many applications, such as customer service, mental health monitoring, and human-computer interaction. However, building accurate emotion recognition models requires large, high-quality datasets, which can be challenging to obtain, especially for <a href="https://aimodels.fyi/papers/arxiv/speech-emotion-recognition-under-resource-constraints-data">under-resourced languages</a>.
The researchers in this paper propose a novel approach to address this challenge. The key insight is that we can leverage high-resource languages, for which large emotion datasets already exist, to enhance emotion recognition in low-resource languages. The process works as follows:
- Translate speech samples from the low-resource language into a high-resource language using a <a href="https://aimodels.fyi/papers/arxiv/improving-speech-emotion-recognition-under-resourced-languages">speech-to-speech translation</a> system.
- Train an emotion recognition model on the translated high-resource language data.
- Transfer the learned representations from the high-resource model back to the original low-resource language, fine-tuning the model on a small amount of local data.
This approach allows the model to benefit from the rich emotion information captured in the high-resource data, while still adapting to the unique characteristics of the low-resource language. The researchers also introduce a <a href="https://aimodels.fyi/papers/arxiv/ser-evals-domain-out-domain-benchmarking-speech">bootstrapping data selection</a> technique to further improve the model's performance.
Technical Explanation
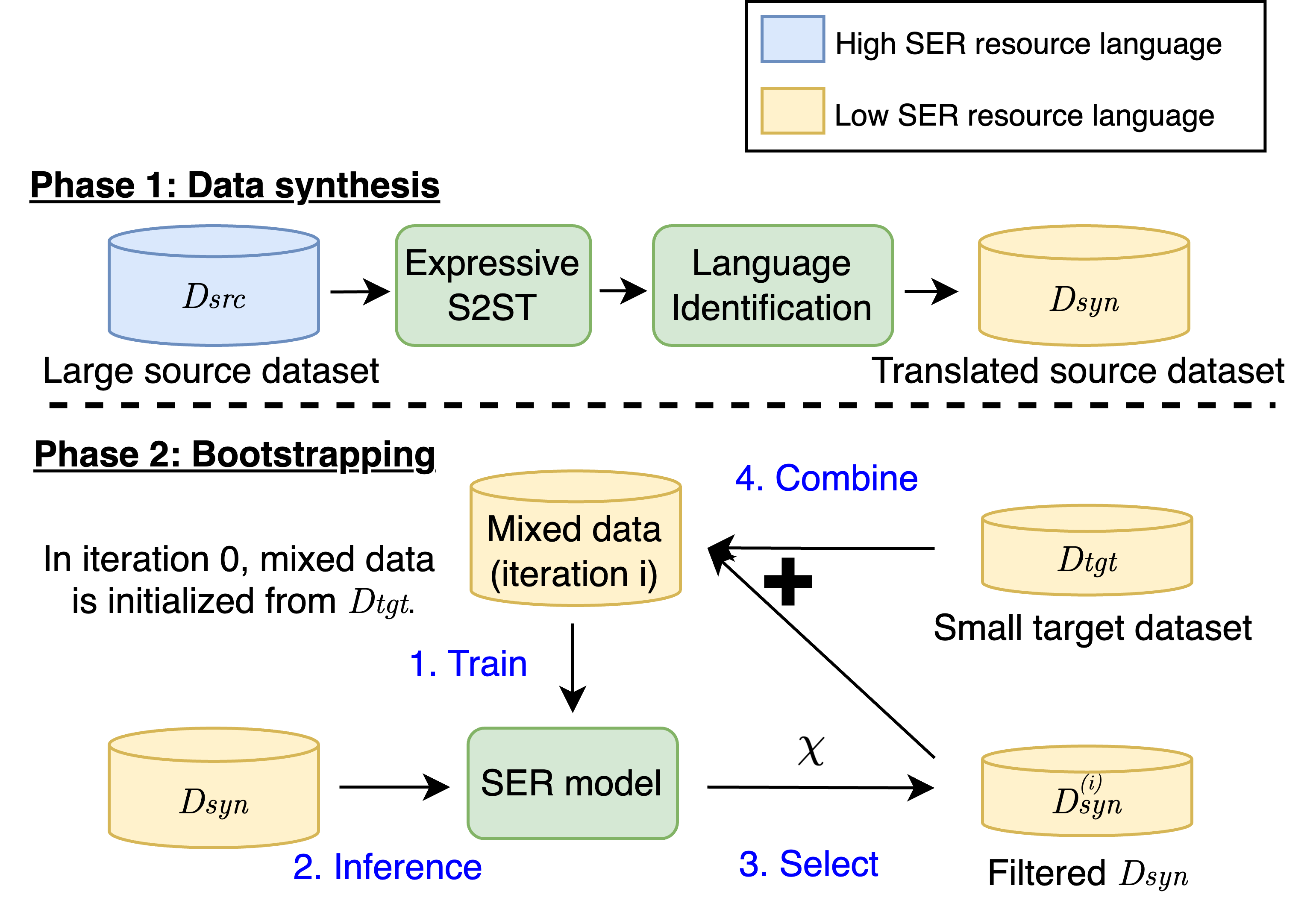
The researchers propose a three-stage approach to improve speech emotion recognition in under-resourced languages:
-
Speech-to-Speech Translation: A speech-to-speech translation model is used to translate speech samples from the low-resource language to a high-resource language. This allows the emotion information in the low-resource data to be leveraged by models trained on high-resource datasets.
-
Emotion Recognition Model Training: An emotion recognition model is trained on the translated high-resource language data. This model can benefit from the rich emotion information captured in the large high-resource dataset.
-
Model Transfer and Fine-tuning: The trained emotion recognition model is then transferred to the original low-resource language. The model is fine-tuned on a small amount of local data to adapt to the unique characteristics of the low-resource language.
The researchers also introduce a <a href="https://aimodels.fyi/papers/arxiv/exploring-self-supervised-multi-view-contrastive-learning">bootstrapping data selection</a> technique to further improve the model's performance. This involves iteratively selecting the most informative samples from the low-resource dataset to fine-tune the model, leading to better adaptation to the target language.
Critical Analysis
The researchers have proposed an innovative approach to address the challenge of speech emotion recognition in under-resourced languages. By leveraging high-resource languages through speech-to-speech translation and model transfer, they have demonstrated significant improvements in emotion recognition accuracy compared to traditional methods.
However, the approach does have some limitations. The performance of the overall system is heavily dependent on the quality of the speech-to-speech translation model, which may not be readily available or easy to train, especially for low-resource language pairs. Additionally, the fine-tuning process on the low-resource data may be challenging if the dataset is very small or of poor quality.
Further research could explore alternative techniques for model adaptation, such as <a href="https://aimodels.fyi/papers/arxiv/selm-enhancing-speech-emotion-recognition-out-domain">unsupervised domain adaptation</a> or meta-learning, which may be more robust to the limitations of low-resource datasets. Additionally, investigating the impact of different translation approaches (e.g., text-to-text vs. speech-to-speech) on the emotion recognition performance could provide valuable insights.
Conclusion
This paper presents a promising approach to improve speech emotion recognition in under-resourced languages by leveraging high-resource language data through speech-to-speech translation and model transfer. The proposed method demonstrates significant performance gains compared to traditional approaches, highlighting the potential of cross-lingual techniques to address the challenges of building robust emotion recognition systems for low-resource settings. While the approach has some limitations, the insights and techniques presented in this work can serve as a valuable starting point for further research and development in this important area of speech technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Speech Emotion Recognition in Under-Resourced Languages via Speech-to-Speech Translation with Bootstrapping Data Selection
Hsi-Che Lin, Yi-Cheng Lin, Huang-Cheng Chou, Hung-yi Lee
Speech Emotion Recognition (SER) is a crucial component in developing general-purpose AI agents capable of natural human-computer interaction. However, building robust multilingual SER systems remains challenging due to the scarcity of labeled data in languages other than English and Chinese. In this paper, we propose an approach to enhance SER performance in low SER resource languages by leveraging data from high-resource languages. Specifically, we employ expressive Speech-to-Speech translation (S2ST) combined with a novel bootstrapping data selection pipeline to generate labeled data in the target language. Extensive experiments demonstrate that our method is both effective and generalizable across different upstream models and languages. Our results suggest that this approach can facilitate the development of more scalable and robust multilingual SER systems.
Read more9/18/2024
🗣️
0
Speech Emotion Recognition under Resource Constraints with Data Distillation
Yi Chang, Zhao Ren, Zhonghao Zhao, Thanh Tam Nguyen, Kun Qian, Tanja Schultz, Bjorn W. Schuller
Speech emotion recognition (SER) plays a crucial role in human-computer interaction. The emergence of edge devices in the Internet of Things (IoT) presents challenges in constructing intricate deep learning models due to constraints in memory and computational resources. Moreover, emotional speech data often contains private information, raising concerns about privacy leakage during the deployment of SER models. To address these challenges, we propose a data distillation framework to facilitate efficient development of SER models in IoT applications using a synthesised, smaller, and distilled dataset. Our experiments demonstrate that the distilled dataset can be effectively utilised to train SER models with fixed initialisation, achieving performances comparable to those developed using the original full emotional speech dataset.
Read more6/24/2024

0
SER Evals: In-domain and Out-of-domain Benchmarking for Speech Emotion Recognition
Mohamed Osman, Daniel Z. Kaplan, Tamer Nadeem
Speech emotion recognition (SER) has made significant strides with the advent of powerful self-supervised learning (SSL) models. However, the generalization of these models to diverse languages and emotional expressions remains a challenge. We propose a large-scale benchmark to evaluate the robustness and adaptability of state-of-the-art SER models in both in-domain and out-of-domain settings. Our benchmark includes a diverse set of multilingual datasets, focusing on less commonly used corpora to assess generalization to new data. We employ logit adjustment to account for varying class distributions and establish a single dataset cluster for systematic evaluation. Surprisingly, we find that the Whisper model, primarily designed for automatic speech recognition, outperforms dedicated SSL models in cross-lingual SER. Our results highlight the need for more robust and generalizable SER models, and our benchmark serves as a valuable resource to drive future research in this direction.
Read more8/16/2024

0
Exploring Self-Supervised Multi-view Contrastive Learning for Speech Emotion Recognition with Limited Annotations
Bulat Khaertdinov, Pedro Jeuris, Annanda Sousa, Enrique Hortal
Recent advancements in Deep and Self-Supervised Learning (SSL) have led to substantial improvements in Speech Emotion Recognition (SER) performance, reaching unprecedented levels. However, obtaining sufficient amounts of accurately labeled data for training or fine-tuning the models remains a costly and challenging task. In this paper, we propose a multi-view SSL pre-training technique that can be applied to various representations of speech, including the ones generated by large speech models, to improve SER performance in scenarios where annotations are limited. Our experiments, based on wav2vec 2.0, spectral and paralinguistic features, demonstrate that the proposed framework boosts the SER performance, by up to 10% in Unweighted Average Recall, in settings with extremely sparse data annotations.
Read more6/13/2024