MELoRA: Mini-Ensemble Low-Rank Adapters for Parameter-Efficient Fine-Tuning

0

Sign in to get full access
Overview
- Presents a new approach called "Mini-Ensemble Low-Rank Adapters" for parameter-efficient fine-tuning of large language models
- Introduces a method to generate a diverse ensemble of low-rank adapters using a novel optimization strategy
- Demonstrates strong performance on various downstream tasks while requiring significantly fewer trainable parameters compared to full fine-tuning
Plain English Explanation
The paper introduces a new technique called "Mini-Ensemble Low-Rank Adapters" that allows large language models to be fine-tuned for specific tasks in a more efficient way. Large language models, like BERT or GPT-3, are powerful but require a lot of computing power and memory to train. Fine-tuning these models for new tasks can be challenging and resource-intensive.
The key idea behind this new technique is to create a "mini-ensemble" of small, specialized adapters that can be added to the base language model. These adapters only require a fraction of the parameters needed for full fine-tuning, making the process much more efficient. The authors develop a novel optimization strategy to generate a diverse ensemble of these low-rank adapters, which helps the model perform well on a variety of tasks.
This approach builds on previous work on low-rank adaptation and expert-based fine-tuning, but introduces several important improvements. The authors demonstrate that their "Mini-Ensemble Low-Rank Adapters" achieve strong performance on benchmark tasks while using significantly fewer trainable parameters compared to full fine-tuning.
Technical Explanation
The paper presents a new method called "Mini-Ensemble Low-Rank Adapters" for parameter-efficient fine-tuning of large language models. The key innovation is a novel optimization strategy that generates a diverse ensemble of low-rank adapters, which can be efficiently added to the base language model.
The authors start by reviewing related work on adaptive ranking and parameter-efficient fine-tuning techniques, such as LORA and MLAE. They then introduce their "Mini-Ensemble Low-Rank Adapters" approach, which builds on these previous methods.
The core idea is to create a small ensemble of low-rank adapter modules that can be added to the base language model. These adapters only require a fraction of the parameters needed for full fine-tuning, making the process much more efficient. The authors develop a novel optimization strategy to generate a diverse ensemble of these low-rank adapters, which helps the model perform well on a variety of tasks.
The paper includes extensive experiments evaluating the performance of their "Mini-Ensemble Low-Rank Adapters" approach on various benchmark tasks, including text classification, question answering, and natural language inference. The results demonstrate that this method achieves strong performance while using significantly fewer trainable parameters compared to full fine-tuning, as well as improvements over previous parameter-efficient techniques.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the "Mini-Ensemble Low-Rank Adapters" approach, providing a strong technical contribution to the field of parameter-efficient fine-tuning of large language models.
One potential limitation of the work is that it focuses primarily on standard benchmark tasks, and it would be valuable to see how the method performs on more diverse or real-world applications. Additionally, the authors do not provide much insight into the inner workings of the ensemble generation process or the relative contributions of the individual adapters.
Further research could explore the scalability of this approach to larger language models, as well as investigate alternative ensemble generation strategies or the potential for combining "Mini-Ensemble Low-Rank Adapters" with other parameter-efficient techniques, such as prompt-based tuning.
Overall, the paper makes a compelling case for the effectiveness of the "Mini-Ensemble Low-Rank Adapters" approach and represents an important step forward in developing more efficient methods for fine-tuning large language models.
Conclusion
The "Mini-Ensemble Low-Rank Adapters" approach presented in this paper offers a promising solution for parameter-efficient fine-tuning of large language models. By creating a diverse ensemble of low-rank adapters, the authors demonstrate strong performance on a variety of tasks while using significantly fewer trainable parameters compared to full fine-tuning.
This work builds on and advances the state-of-the-art in parameter-efficient fine-tuning, with potential applications in a wide range of natural language processing tasks where computational resources are limited. As large language models become increasingly ubiquitous, techniques like "Mini-Ensemble Low-Rank Adapters" will be crucial for enabling their widespread deployment and adoption.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MELoRA: Mini-Ensemble Low-Rank Adapters for Parameter-Efficient Fine-Tuning
Pengjie Ren, Chengshun Shi, Shiguang Wu, Mengqi Zhang, Zhaochun Ren, Maarten de Rijke, Zhumin Chen, Jiahuan Pei
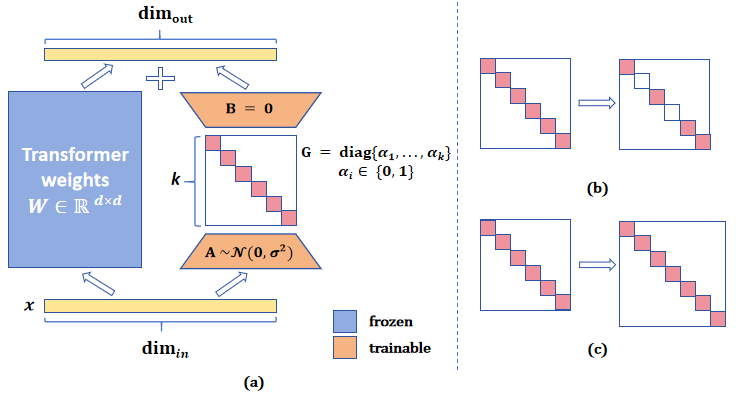
Parameter-efficient fine-tuning (PEFT) is a popular method for tailoring pre-trained large language models (LLMs), especially as the models' scale and the diversity of tasks increase. Low-rank adaptation (LoRA) is based on the idea that the adaptation process is intrinsically low-dimensional, i.e., significant model changes can be represented with relatively few parameters. However, decreasing the rank encounters challenges with generalization errors for specific tasks when compared to full-parameter fine-tuning. We present MELoRA, a mini-ensemble low-rank adapters that uses fewer trainable parameters while maintaining a higher rank, thereby offering improved performance potential. The core idea is to freeze original pretrained weights and train a group of mini LoRAs with only a small number of parameters. This can capture a significant degree of diversity among mini LoRAs, thus promoting better generalization ability. We conduct a theoretical analysis and empirical studies on various NLP tasks. Our experimental results show that, compared to LoRA, MELoRA achieves better performance with 8 times fewer trainable parameters on natural language understanding tasks and 36 times fewer trainable parameters on instruction following tasks, which demonstrates the effectiveness of MELoRA.
Read more6/26/2024
0
ALoRA: Allocating Low-Rank Adaptation for Fine-tuning Large Language Models
Zequan Liu, Jiawen Lyn, Wei Zhu, Xing Tian, Yvette Graham
Parameter-efficient fine-tuning (PEFT) is widely studied for its effectiveness and efficiency in the era of large language models. Low-rank adaptation (LoRA) has demonstrated commendable performance as a popular and representative method. However, it is implemented with a fixed intrinsic rank that might not be the ideal setting for the downstream tasks. Recognizing the need for more flexible downstream task adaptation, we extend the methodology of LoRA to an innovative approach we call allocating low-rank adaptation (ALoRA) that enables dynamic adjustments to the intrinsic rank during the adaptation process. First, we propose a novel method, AB-LoRA, that can effectively estimate the importance score of each LoRA rank. Second, guided by AB-LoRA, we gradually prune abundant and negatively impacting LoRA ranks and allocate the pruned LoRA budgets to important Transformer modules needing higher ranks. We have conducted experiments on various tasks, and the experimental results demonstrate that our ALoRA method can outperform the recent baselines with comparable tunable parameters.
Read more4/16/2024

0
Flat-LoRA: Low-Rank Adaption over a Flat Loss Landscape
Tao Li, Zhengbao He, Yujun Li, Yasheng Wang, Lifeng Shang, Xiaolin Huang
Fine-tuning large-scale pre-trained models is prohibitively expensive in terms of computational and memory costs. Low-Rank Adaptation (LoRA), a popular Parameter-Efficient Fine-Tuning (PEFT) method, provides an efficient way to fine-tune models by optimizing only a low-rank matrix. Despite recent progress made in improving LoRA's performance, the connection between the LoRA optimization space and the original full parameter space is often overlooked. A solution that appears flat in the LoRA space may exist sharp directions in the full parameter space, potentially harming generalization performance. In this paper, we propose Flat-LoRA, an efficient approach that seeks a low-rank adaptation located in a flat region of the full parameter space.Instead of relying on the well-established sharpness-aware minimization approach, which can incur significant computational and memory burdens, we utilize random weight perturbation with a Bayesian expectation loss objective to maintain training efficiency and design a refined perturbation generation strategy for improved performance. Experiments on natural language processing and image classification tasks with various architectures demonstrate the effectiveness of our approach.
Read more9/24/2024

0
ShareLoRA: Parameter Efficient and Robust Large Language Model Fine-tuning via Shared Low-Rank Adaptation
Yurun Song, Junchen Zhao, Ian G. Harris, Sangeetha Abdu Jyothi
This study introduces an approach to optimize Parameter Efficient Fine Tuning (PEFT) for Pretrained Language Models (PLMs) by implementing a Shared Low Rank Adaptation (ShareLoRA). By strategically deploying ShareLoRA across different layers and adapting it for the Query, Key, and Value components of self-attention layers, we achieve a substantial reduction in the number of training parameters and memory usage. Importantly, ShareLoRA not only maintains model performance but also exhibits robustness in both classification and generation tasks across a variety of models, including RoBERTa, GPT-2, LLaMA and LLaMA2. It demonstrates superior transfer learning capabilities compared to standard LoRA applications and mitigates overfitting by sharing weights across layers. Our findings affirm that ShareLoRA effectively boosts parameter efficiency while ensuring scalable and high-quality performance across different language model architectures.
Read more6/18/2024