Membership Inference on Text-to-Image Diffusion Models via Conditional Likelihood Discrepancy

0
🤯
Sign in to get full access
Overview
- Text-to-image diffusion models have achieved great success in generating controlled images, but come with concerns about privacy and copyright
- Membership inference has been proposed as a way to audit for unauthorized data usage, but previous methods are not applicable to text-to-image models
- This paper identifies a "conditional overfitting" issue in text-to-image models and derives a new metric, Conditional Likelihood Discrepancy (CLiD), to perform membership inference more effectively
Plain English Explanation
Text-to-image models are a type of AI system that can generate images based on textual descriptions. These models have become very good at creating detailed, customized images, but this success has raised some concerns. There are worries that these models could be used to access private data or infringe on copyrights.
Membership inference has been proposed as a way to address these issues by detecting whether the images being generated are based on the model "remembering" specific training data. However, previous techniques for doing this have not worked well for text-to-image models due to their advanced capabilities.
This paper makes an important observation - it finds that text-to-image models tend to "overfit" the relationship between the text and the image, rather than just memorizing the images themselves. Based on this, the researchers develop a new metric called Conditional Likelihood Discrepancy (CLiD) that is better able to identify whether a generated image is based on the model remembering specific training data.
Experimental results show that this CLiD approach significantly outperforms previous methods at membership inference, even when the model has been trained to be more robust (such as through early stopping or data augmentation). This is an important step forward in being able to audit these powerful text-to-image models and ensure they are being used responsibly.
Technical Explanation
The key insight behind this work is the identification of a "conditional overfitting" phenomenon in text-to-image diffusion models. The researchers observed that these models tend to focus more on learning the conditional distribution of images given the text, rather than the overall marginal distribution of images.
This is an important distinction, as it means the models may be memorizing the specific text-image pairings in the training data, rather than just learning a general mapping from text to images. The researchers hypothesize this is due to the enhanced generalization capabilities of text-to-image models compared to previous diffusion models.
Based on this observation, the researchers derive a new analytical indicator called Conditional Likelihood Discrepancy (CLiD). This metric aims to quantify the degree of conditional overfitting by comparing the model's estimated likelihood of a sample under the conditional distribution versus the marginal distribution.
Experiments on various datasets show that CLiD significantly outperforms prior membership inference techniques, even when the model has been trained with methods like early stopping or data augmentation to reduce overfitting.
The intuition is that by focusing on the conditional likelihood, CLiD is able to more directly detect the model's tendency to memorize specific text-image pairs, rather than just the overall image statistics. This makes it a more effective diagnostic tool for identifying potential unauthorized data usage in text-to-image diffusion models.
Critical Analysis
The paper makes a compelling case for the prevalence of conditional overfitting in text-to-image diffusion models, and demonstrates the effectiveness of the proposed CLiD metric for membership inference. However, a few potential limitations and areas for further research are worth noting:
-
The study is primarily focused on evaluating membership inference performance, but does not deeply investigate the underlying reasons for the observed conditional overfitting behavior. Further research could explore the architectural choices, training dynamics, or other factors that contribute to this phenomenon.
-
The experiments are conducted on a limited set of datasets and model configurations. It would be valuable to evaluate the approach on a broader range of text-to-image models and real-world datasets to assess its generalizability.
-
While CLiD shows strong performance, it still relies on sampling-based likelihood estimation, which can be computationally expensive. Exploring more efficient likelihood estimation techniques or alternative membership inference approaches could further improve the practicality of this framework.
Overall, this work represents an important step forward in understanding and auditing the behavior of text-to-image diffusion models. The identification of conditional overfitting and the development of the CLiD metric are valuable contributions that could help ensure the responsible deployment of these powerful generative models.
Conclusion
This paper tackles the critical challenge of detecting unauthorized data usage in text-to-image diffusion models, which have become increasingly capable at generating detailed, customized images. By identifying a "conditional overfitting" phenomenon in these models, the researchers develop a novel metric called Conditional Likelihood Discrepancy (CLiD) that can more effectively perform membership inference.
The experimental results demonstrate that CLiD significantly outperforms previous methods, even when the models have been trained with techniques to reduce overfitting. This is an important advancement that could help enable more transparent and accountable use of text-to-image generation systems, addressing concerns around privacy and copyright infringement.
As these models continue to advance, ongoing research into their inner workings and potential misuse will be crucial. The insights and techniques presented in this paper represent an important contribution towards developing robust auditing tools and ensuring the responsible development of powerful generative AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
0
Membership Inference on Text-to-Image Diffusion Models via Conditional Likelihood Discrepancy
Shengfang Zhai, Huanran Chen, Yinpeng Dong, Jiajun Li, Qingni Shen, Yansong Gao, Hang Su, Yang Liu
Text-to-image diffusion models have achieved tremendous success in the field of controllable image generation, while also coming along with issues of privacy leakage and data copyrights. Membership inference arises in these contexts as a potential auditing method for detecting unauthorized data usage. While some efforts have been made on diffusion models, they are not applicable to text-to-image diffusion models due to the high computation overhead and enhanced generalization capabilities. In this paper, we first identify a conditional overfitting phenomenon in text-to-image diffusion models, indicating that these models tend to overfit the conditional distribution of images given the text rather than the marginal distribution of images. Based on this observation, we derive an analytical indicator, namely Conditional Likelihood Discrepancy (CLiD), to perform membership inference, which reduces the stochasticity in estimating the memorization of individual samples. Experimental results demonstrate that our method significantly outperforms previous methods across various data distributions and scales. Additionally, our method shows superior resistance to overfitting mitigation strategies such as early stopping and data augmentation.
Read more5/30/2024
0
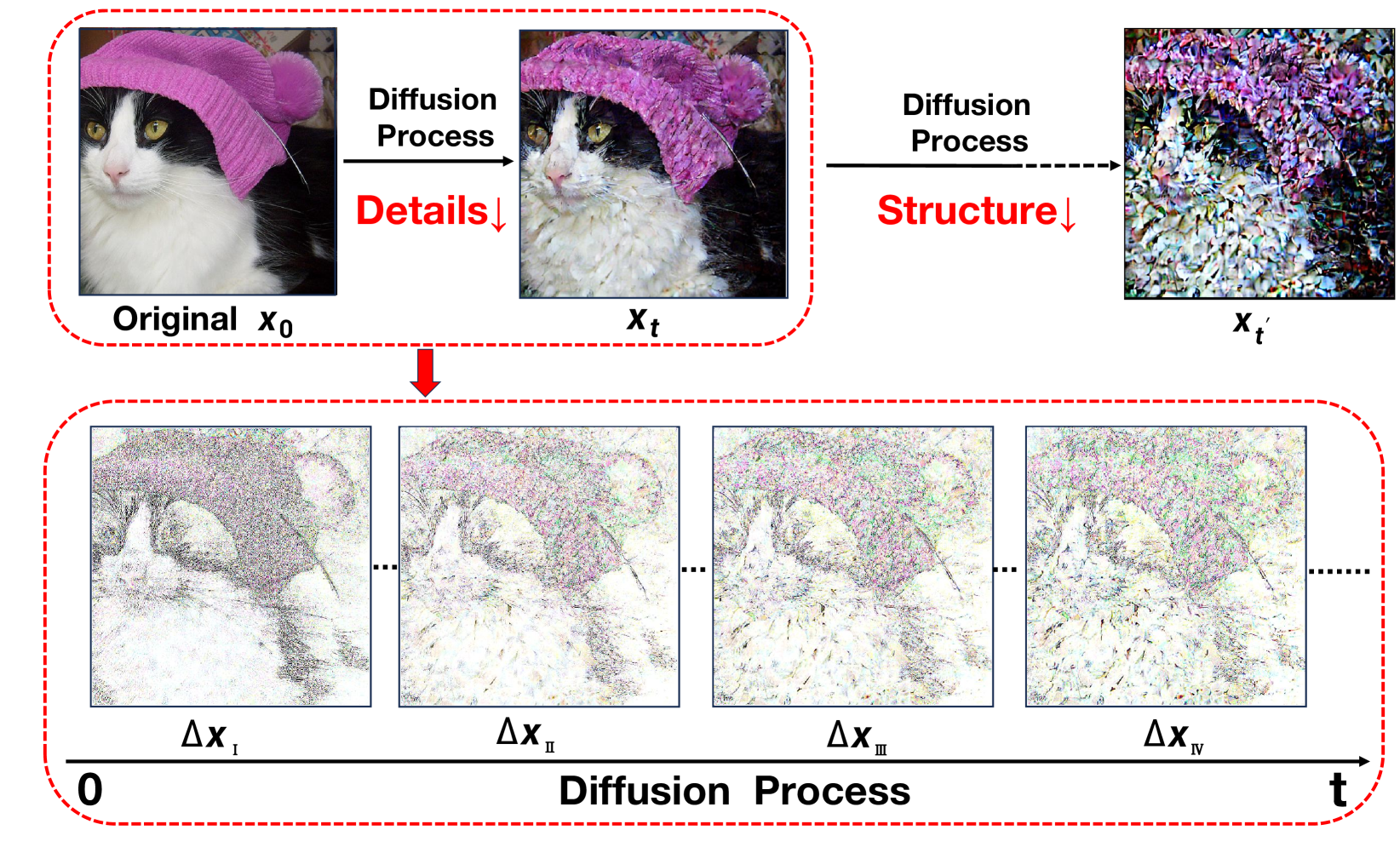
Unveiling Structural Memorization: Structural Membership Inference Attack for Text-to-Image Diffusion Models
Qiao Li, Xiaomeng Fu, Xi Wang, Jin Liu, Xingyu Gao, Jiao Dai, Jizhong Han
With the rapid advancements of large-scale text-to-image diffusion models, various practical applications have emerged, bringing significant convenience to society. However, model developers may misuse the unauthorized data to train diffusion models. These data are at risk of being memorized by the models, thus potentially violating citizens' privacy rights. Therefore, in order to judge whether a specific image is utilized as a member of a model's training set, Membership Inference Attack (MIA) is proposed to serve as a tool for privacy protection. Current MIA methods predominantly utilize pixel-wise comparisons as distinguishing clues, considering the pixel-level memorization characteristic of diffusion models. However, it is practically impossible for text-to-image models to memorize all the pixel-level information in massive training sets. Therefore, we move to the more advanced structure-level memorization. Observations on the diffusion process show that the structures of members are better preserved compared to those of nonmembers, indicating that diffusion models possess the capability to remember the structures of member images from training sets. Drawing on these insights, we propose a simple yet effective MIA method tailored for text-to-image diffusion models. Extensive experimental results validate the efficacy of our approach. Compared to current pixel-level baselines, our approach not only achieves state-of-the-art performance but also demonstrates remarkable robustness against various distortions.
Read more7/19/2024
0
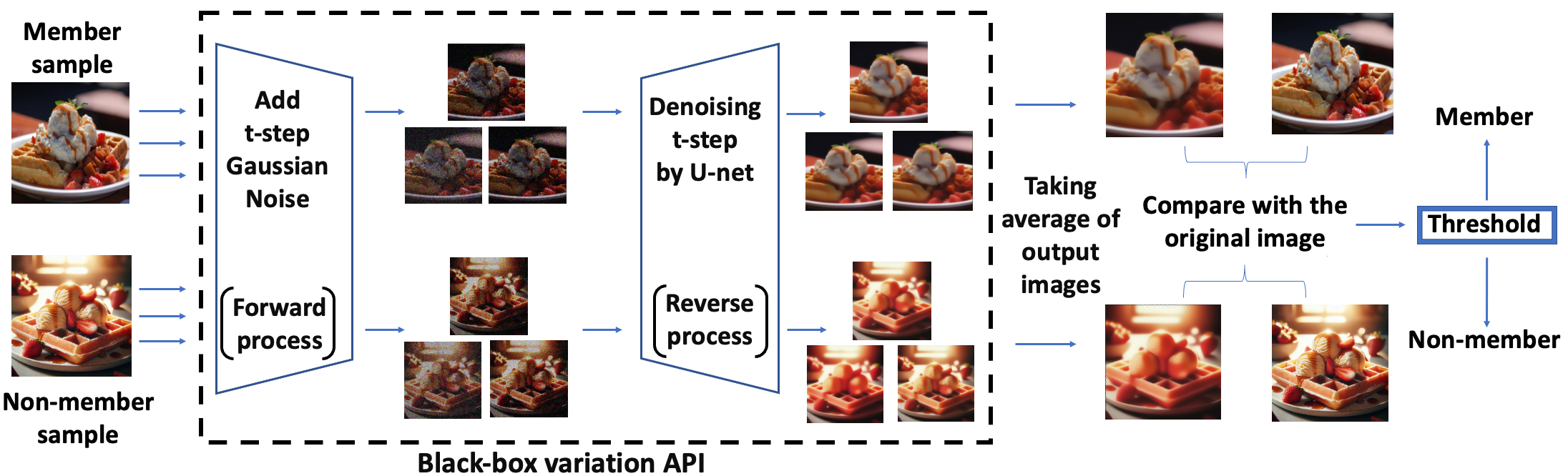
Towards Black-Box Membership Inference Attack for Diffusion Models
Jingwei Li, Jing Dong, Tianxing He, Jingzhao Zhang
Identifying whether an artwork was used to train a diffusion model is an important research topic, given the rising popularity of AI-generated art and the associated copyright concerns. The work approaches this problem from the membership inference attack (MIA) perspective. We first identify the limitations of applying existing MIA methods for copyright protection: the required access of internal U-nets and the choice of non-member datasets for evaluation. To address the above problems, we introduce a novel black-box membership inference attack method that operates without needing access to the model's internal U-net. We then construct a DALL-E generated dataset for a more comprehensive evaluation. We validate our method across various setups, and our experimental results outperform previous works.
Read more6/3/2024
0
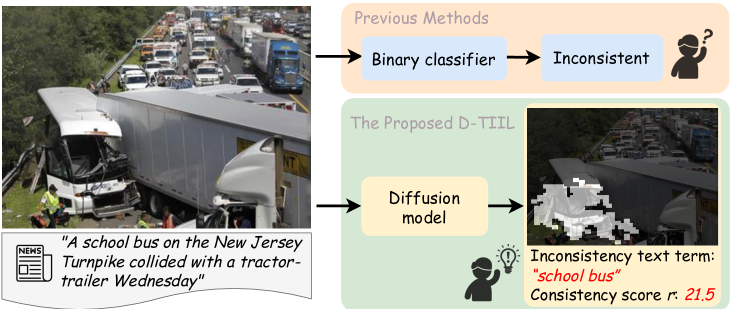
Exposing Text-Image Inconsistency Using Diffusion Models
Mingzhen Huang, Shan Jia, Zhou Zhou, Yan Ju, Jialing Cai, Siwei Lyu
In the battle against widespread online misinformation, a growing problem is text-image inconsistency, where images are misleadingly paired with texts with different intent or meaning. Existing classification-based methods for text-image inconsistency can identify contextual inconsistencies but fail to provide explainable justifications for their decisions that humans can understand. Although more nuanced, human evaluation is impractical at scale and susceptible to errors. To address these limitations, this study introduces D-TIIL (Diffusion-based Text-Image Inconsistency Localization), which employs text-to-image diffusion models to localize semantic inconsistencies in text and image pairs. These models, trained on large-scale datasets act as ``omniscient agents that filter out irrelevant information and incorporate background knowledge to identify inconsistencies. In addition, D-TIIL uses text embeddings and modified image regions to visualize these inconsistencies. To evaluate D-TIIL's efficacy, we introduce a new TIIL dataset containing 14K consistent and inconsistent text-image pairs. Unlike existing datasets, TIIL enables assessment at the level of individual words and image regions and is carefully designed to represent various inconsistencies. D-TIIL offers a scalable and evidence-based approach to identifying and localizing text-image inconsistency, providing a robust framework for future research combating misinformation.
Read more4/30/2024