MEMO: Dataset and Methods for Robust Multimodal Retinal Image Registration with Large or Small Vessel Density Differences

0

Sign in to get full access
1 Introduction
This research paper presents a dataset and methods for robust multimodal retinal image registration, which is the process of aligning images of the retina taken using different imaging modalities. The key challenge addressed is handling large or small differences in the density of blood vessels visible in the images, which can make registration difficult.
2 Related Works
2.1 Retinal Image Datasets with Image Pairs
The paper notes that previous retinal image datasets, such as those featured in studies on blood vessel segmentation models and new datasets for measuring blood vessel segmentation performance, have not provided diverse multimodal image pairs for registration tasks. This motivated the creation of a new dataset.
2.2 Retinal Image Registration Techniques
The paper discusses prior work on retinal image registration, including label-free and data-free training strategies for vasculature and automated vessel segmentation techniques for heart and brain imaging. However, it notes that these techniques have not been extensively evaluated for robustness to large or small vessel density differences between modalities.
Technical Explanation
The key technical contributions of this work include:
- A new dataset of multimodal retinal image pairs with varying vessel densities, designed to evaluate registration robustness.
- A registration method that uses image-level regression and uncertainty-aware retinal image features to handle differences in vessel density.
The dataset contains retinal image pairs from different modalities (e.g., color fundus, fluorescein angiography, optical coherence tomography) with annotations for vascular structures. The researchers systematically varied the vessel density between the image pairs to create challenging registration scenarios.
The proposed registration method learns a mapping between the multimodal images that is robust to vessel density differences. It uses an uncertainty-aware regression approach to handle ambiguous or low-contrast regions in the images.
Critical Analysis
The paper provides a thorough evaluation of the new dataset and registration method, demonstrating improved performance compared to baseline techniques. However, the authors acknowledge that the dataset is limited to a specific population and that further testing on more diverse data would be needed to fully validate the generalizability of the approach.
Additionally, the paper does not delve into the potential clinical implications or real-world applications of this work, which would be valuable to explore further. Assessing the impact on downstream tasks like disease diagnosis or treatment monitoring could provide important context.
Conclusion
This research presents a novel dataset and registration method to address the challenge of aligning multimodal retinal images with varying blood vessel densities. The technical contributions have the potential to improve the robustness and reliability of retinal image analysis tools, which could ultimately benefit clinical practice and patient care. However, further research is needed to fully explore the practical applications and limitations of this work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MEMO: Dataset and Methods for Robust Multimodal Retinal Image Registration with Large or Small Vessel Density Differences
Chiao-Yi Wang, Faranguisse Kakhi Sadrieh, Yi-Ting Shen, Shih-En Chen, Sarah Kim, Victoria Chen, Achyut Raghavendra, Dongyi Wang, Osamah Saeedi, Yang Tao
The measurement of retinal blood flow (RBF) in capillaries can provide a powerful biomarker for the early diagnosis and treatment of ocular diseases. However, no single modality can determine capillary flowrates with high precision. Combining erythrocyte-mediated angiography (EMA) with optical coherence tomography angiography (OCTA) has the potential to achieve this goal, as EMA can measure the absolute 2D RBF of retinal microvasculature and OCTA can provide the 3D structural images of capillaries. However, multimodal retinal image registration between these two modalities remains largely unexplored. To fill this gap, we establish MEMO, the first public multimodal EMA and OCTA retinal image dataset. A unique challenge in multimodal retinal image registration between these modalities is the relatively large difference in vessel density (VD). To address this challenge, we propose a segmentation-based deep-learning framework (VDD-Reg) and a new evaluation metric (MSD), which provide robust results despite differences in vessel density. VDD-Reg consists of a vessel segmentation module and a registration module. To train the vessel segmentation module, we further designed a two-stage semi-supervised learning framework (LVD-Seg) combining supervised and unsupervised losses. We demonstrate that VDD-Reg outperforms baseline methods quantitatively and qualitatively for cases of both small VD differences (using the CF-FA dataset) and large VD differences (using our MEMO dataset). Moreover, VDD-Reg requires as few as three annotated vessel segmentation masks to maintain its accuracy, demonstrating its feasibility.
Read more7/16/2024
0
Benchmarking Retinal Blood Vessel Segmentation Models for Cross-Dataset and Cross-Disease Generalization
Jeremiah Fadugba, Patrick Kohler, Lisa Koch, Petru Manescu, Philipp Berens
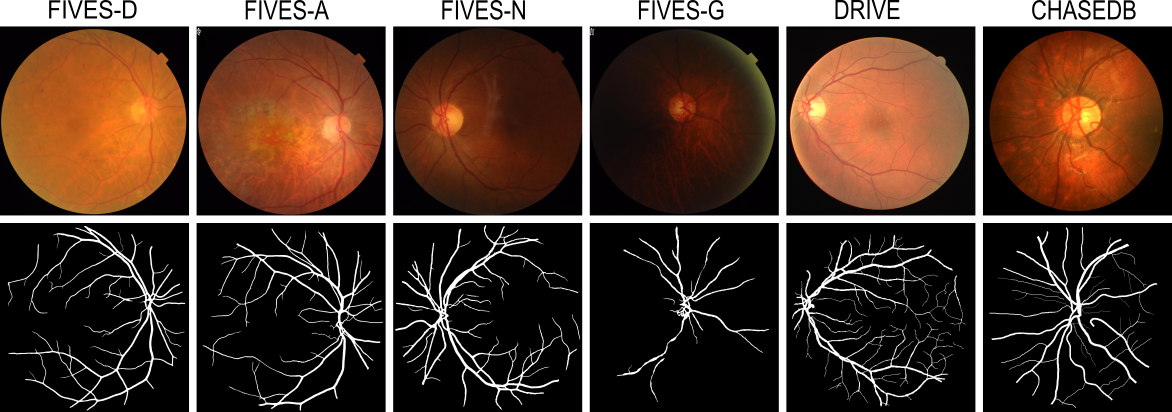
Retinal blood vessel segmentation can extract clinically relevant information from fundus images. As manual tracing is cumbersome, algorithms based on Convolution Neural Networks have been developed. Such studies have used small publicly available datasets for training and measuring performance, running the risk of overfitting. Here, we provide a rigorous benchmark for various architectural and training choices commonly used in the literature on the largest dataset published to date. We train and evaluate five published models on the publicly available FIVES fundus image dataset, which exceeds previous ones in size and quality and which contains also images from common ophthalmological conditions (diabetic retinopathy, age-related macular degeneration, glaucoma). We compare the performance of different model architectures across different loss functions, levels of image qualitiy and ophthalmological conditions and assess their ability to perform well in the face of disease-induced domain shifts. Given sufficient training data, basic architectures such as U-Net perform just as well as more advanced ones, and transfer across disease-induced domain shifts typically works well for most architectures. However, we find that image quality is a key factor determining segmentation outcomes. When optimizing for segmentation performance, investing into a well curated dataset to train a standard architecture yields better results than tuning a sophisticated architecture on a smaller dataset or one with lower image quality. We distilled the utility of architectural advances in terms of their clinical relevance therefore providing practical guidance for model choices depending on the circumstances of the clinical setting
Read more6/24/2024
🚀
0
A new dataset for measuring the performance of blood vessel segmentation methods under distribution shifts
Matheus Viana da Silva, Nat'alia de Carvalho Santos, Julie Ouellette, Baptiste Lacoste, Cesar Henrique Comin
Creating a dataset for training supervised machine learning algorithms can be a demanding task. This is especially true for medical image segmentation since one or more specialists are usually required for image annotation, and creating ground truth labels for just a single image can take up to several hours. In addition, it is paramount that the annotated samples represent well the different conditions that might affect the imaged tissues as well as possible changes in the image acquisition process. This can only be achieved by considering samples that are typical in the dataset as well as atypical, or even outlier, samples. We introduce VessMAP, a heterogeneous blood vessel segmentation dataset acquired by carefully sampling relevant images from a larger non-annotated dataset. A methodology was developed to select both prototypical and atypical samples from the base dataset, thus defining an assorted set of images that can be used for measuring the performance of segmentation algorithms on samples that are highly distinct from each other. To demonstrate the potential of the new dataset, we show that the validation performance of a neural network changes significantly depending on the splits used for training the network.
Read more4/19/2024

0
Region Guided Attention Network for Retinal Vessel Segmentation
Syed Javed, Tariq M. Khan, Abdul Qayyum, Arcot Sowmya, Imran Razzak
Retinal imaging has emerged as a promising method of addressing this challenge, taking advantage of the unique structure of the retina. The retina is an embryonic extension of the central nervous system, providing a direct in vivo window into neurological health. Recent studies have shown that specific structural changes in retinal vessels can not only serve as early indicators of various diseases but also help to understand disease progression. In this work, we present a lightweight retinal vessel segmentation network based on the encoder-decoder mechanism with region-guided attention. We introduce inverse addition attention blocks with region guided attention to focus on the foreground regions and improve the segmentation of regions of interest. To further boost the model's performance on retinal vessel segmentation, we employ a weighted dice loss. This choice is particularly effective in addressing the class imbalance issues frequently encountered in retinal vessel segmentation tasks. Dice loss penalises false positives and false negatives equally, encouraging the model to generate more accurate segmentation with improved object boundary delineation and reduced fragmentation. Extensive experiments on a benchmark dataset show better performance (0.8285, 0.8098, 0.9677, and 0.8166 recall, precision, accuracy and F1 score respectively) compared to state-of-the-art methods.
Read more9/24/2024