Memory-Enhanced Neural Solvers for Efficient Adaptation in Combinatorial Optimization

0

Sign in to get full access
Overview
- This paper presents a novel approach to combinatorial optimization problems that uses memory-enhanced neural networks to efficiently adapt to new problem instances.
- The researchers develop a Memory-Enhanced Neural Solver that combines a neural network-based solver with a memory module to capture and reuse problem-solving strategies.
- The system is evaluated on several combinatorial optimization problems, including the Traveling Salesman Problem and Vehicle Routing Problem, and demonstrates improved performance and efficiency compared to previous neural-based approaches.
Plain English Explanation
Combinatorial optimization problems are a type of computational challenge that involve finding the best solution from a large set of possibilities. These problems are important in many real-world applications, such as logistics, scheduling, and resource allocation. However, solving these problems can be extremely difficult, especially when the problem instances change over time.
The researchers in this paper have developed a new approach that uses a special type of neural network, called a Memory-Enhanced Neural Solver, to tackle these challenges. This system combines a neural network-based solver with a memory module that can store and reuse successful problem-solving strategies.
When faced with a new problem instance, the Memory-Enhanced Neural Solver can quickly adapt and apply the relevant strategies from its memory, rather than having to learn everything from scratch. This allows the system to solve problems more efficiently and effectively than previous neural-based approaches, which often struggle to generalize to new problem instances.
The researchers tested their system on several well-known combinatorial optimization problems, such as the Traveling Salesman Problem and Vehicle Routing Problem. The results showed that the Memory-Enhanced Neural Solver outperformed other state-of-the-art methods, demonstrating its potential to revolutionize the way we approach these complex optimization challenges.
Technical Explanation
The core idea behind the Memory-Enhanced Neural Solver is to combine a neural network-based solver with a memory module that can store and retrieve successful problem-solving strategies. This allows the system to efficiently adapt to new problem instances by leveraging its accumulated experience.
The network architecture consists of an encoder module that encodes the problem instance into a latent representation, a memory module that stores and retrieves relevant strategies, and a decoder module that generates the final solution. During training, the system learns to effectively utilize the memory module to improve its performance on the target combinatorial optimization problems.
The researchers evaluate their approach on several well-known combinatorial optimization problems, including the Traveling Salesman Problem and Vehicle Routing Problem. The results show that the Memory-Enhanced Neural Solver outperforms other state-of-the-art neural-based methods, particularly in terms of adaptation efficiency when faced with new problem instances.
Critical Analysis
The paper presents a compelling approach to addressing the challenge of adapting neural-based solvers to new instances of combinatorial optimization problems. The Memory-Enhanced Neural Solver architecture is a novel and promising solution that effectively leverages memory to improve problem-solving capabilities.
However, the paper does not thoroughly explore the limitations of the proposed approach. For example, it is unclear how the system would perform on extremely large or complex problem instances, or how sensitive it is to the quality and diversity of the training data. Additionally, the paper does not provide a deep analysis of the types of problem-solving strategies stored in the memory module and how they are accessed and applied.
Further research is needed to better understand the strengths and weaknesses of the Memory-Enhanced Neural Solver, as well as its potential for self-improvement and continual learning capabilities. Investigating these aspects could lead to even more powerful and adaptable combinatorial optimization solvers.
Conclusion
The Memory-Enhanced Neural Solver presented in this paper represents a significant advancement in the field of neural-based combinatorial optimization. By incorporating a memory module that can store and reuse successful problem-solving strategies, the system demonstrates improved performance and efficiency when adapting to new problem instances.
This research has the potential to significantly impact a wide range of real-world applications that rely on solving complex combinatorial optimization problems, such as logistics, scheduling, and resource allocation. As the authors continue to refine and expand upon this approach, we may see even more powerful and versatile solvers that can tackle increasingly challenging optimization problems with greater speed and accuracy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Memory-Enhanced Neural Solvers for Efficient Adaptation in Combinatorial Optimization
Felix Chalumeau, Refiloe Shabe, Noah de Nicola, Arnu Pretorius, Thomas D. Barrett, Nathan Grinsztajn
Combinatorial Optimization is crucial to numerous real-world applications, yet still presents challenges due to its (NP-)hard nature. Amongst existing approaches, heuristics often offer the best trade-off between quality and scalability, making them suitable for industrial use. While Reinforcement Learning (RL) offers a flexible framework for designing heuristics, its adoption over handcrafted heuristics remains incomplete within industrial solvers. Existing learned methods still lack the ability to adapt to specific instances and fully leverage the available computational budget. The current best methods either rely on a collection of pre-trained policies, or on data-inefficient fine-tuning; hence failing to fully utilize newly available information within the constraints of the budget. In response, we present MEMENTO, an RL approach that leverages memory to improve the adaptation of neural solvers at inference time. MEMENTO enables updating the action distribution dynamically based on the outcome of previous decisions. We validate its effectiveness on benchmark problems, in particular Traveling Salesman and Capacitated Vehicle Routing, demonstrating it can successfully be combined with standard methods to boost their performance under a given budget, both in and out-of-distribution, improving their performance on all 12 evaluated tasks.
Read more6/26/2024
🛠️
0
Combinatorial Optimization with Policy Adaptation using Latent Space Search
Felix Chalumeau, Shikha Surana, Clement Bonnet, Nathan Grinsztajn, Arnu Pretorius, Alexandre Laterre, Thomas D. Barrett
Combinatorial Optimization underpins many real-world applications and yet, designing performant algorithms to solve these complex, typically NP-hard, problems remains a significant research challenge. Reinforcement Learning (RL) provides a versatile framework for designing heuristics across a broad spectrum of problem domains. However, despite notable progress, RL has not yet supplanted industrial solvers as the go-to solution. Current approaches emphasize pre-training heuristics that construct solutions but often rely on search procedures with limited variance, such as stochastically sampling numerous solutions from a single policy or employing computationally expensive fine-tuning of the policy on individual problem instances. Building on the intuition that performant search at inference time should be anticipated during pre-training, we propose COMPASS, a novel RL approach that parameterizes a distribution of diverse and specialized policies conditioned on a continuous latent space. We evaluate COMPASS across three canonical problems - Travelling Salesman, Capacitated Vehicle Routing, and Job-Shop Scheduling - and demonstrate that our search strategy (i) outperforms state-of-the-art approaches on 11 standard benchmarking tasks and (ii) generalizes better, surpassing all other approaches on a set of 18 procedurally transformed instance distributions.
Read more5/29/2024
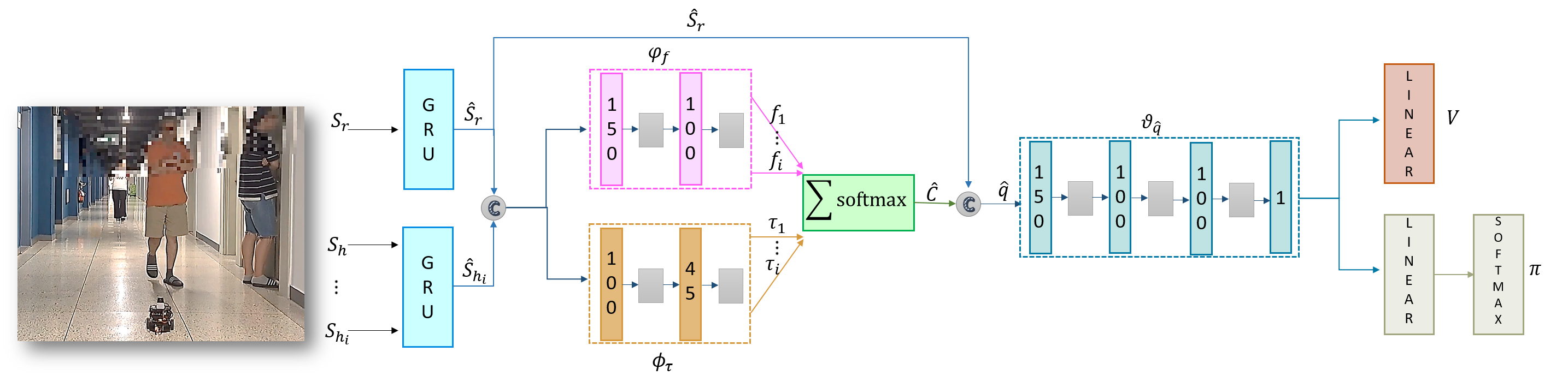
0
MeSA-DRL: Memory-Enhanced Deep Reinforcement Learning for Advanced Socially Aware Robot Navigation in Crowded Environments
Mannan Saeed Muhammad, Estrella Montero
Autonomous navigation capabilities play a critical role in service robots operating in environments where human interactions are pivotal, due to the dynamic and unpredictable nature of these environments. However, the variability in human behavior presents a substantial challenge for robots in predicting and anticipating movements, particularly in crowded scenarios. To address this issue, a memory-enabled deep reinforcement learning framework is proposed for autonomous robot navigation in diverse pedestrian scenarios. The proposed framework leverages long-term memory to retain essential information about the surroundings and model sequential dependencies effectively. The importance of human-robot interactions is also encoded to assign higher attention to these interactions. A global planning mechanism is incorporated into the memory-enabled architecture. Additionally, a multi-term reward system is designed to prioritize and encourage long-sighted robot behaviors by incorporating dynamic warning zones. Simultaneously, it promotes smooth trajectories and minimizes the time taken to reach the robot's desired goal. Extensive simulation experiments show that the suggested approach outperforms representative state-of-the-art methods, showcasing its ability to a navigation efficiency and safety in real-world scenarios.
Read more4/9/2024
🤿
0
Q-Pensieve: Boosting Sample Efficiency of Multi-Objective RL Through Memory Sharing of Q-Snapshots
Wei Hung, Bo-Kai Huang, Ping-Chun Hsieh, Xi Liu
Many real-world continuous control problems are in the dilemma of weighing the pros and cons, multi-objective reinforcement learning (MORL) serves as a generic framework of learning control policies for different preferences over objectives. However, the existing MORL methods either rely on multiple passes of explicit search for finding the Pareto front and therefore are not sample-efficient, or utilizes a shared policy network for coarse knowledge sharing among policies. To boost the sample efficiency of MORL, we propose Q-Pensieve, a policy improvement scheme that stores a collection of Q-snapshots to jointly determine the policy update direction and thereby enables data sharing at the policy level. We show that Q-Pensieve can be naturally integrated with soft policy iteration with convergence guarantee. To substantiate this concept, we propose the technique of Q replay buffer, which stores the learned Q-networks from the past iterations, and arrive at a practical actor-critic implementation. Through extensive experiments and an ablation study, we demonstrate that with much fewer samples, the proposed algorithm can outperform the benchmark MORL methods on a variety of MORL benchmark tasks.
Read more7/26/2024