Q-Pensieve: Boosting Sample Efficiency of Multi-Objective RL Through Memory Sharing of Q-Snapshots

0
🤿
Sign in to get full access
Overview
- Real-world control problems often involve balancing multiple, sometimes conflicting objectives.
- Multi-Objective Reinforcement Learning (MORL) is a framework for learning control policies that optimize for different preferences over these objectives.
- Existing MORL methods either require multiple passes to find the optimal Pareto front, or use a shared policy network for coarse knowledge sharing, which is not sample-efficient.
Plain English Explanation
Many real-world control problems, such as controlling a self-driving car, involve balancing multiple, sometimes conflicting objectives. For example, the car needs to reach its destination quickly, but also safely and efficiently. Multi-Objective Reinforcement Learning (MORL) is a framework that can be used to learn control policies that optimize for different preferences over these objectives.
However, the existing MORL methods either rely on multiple passes of explicit search to find the optimal Pareto front, which is not very sample-efficient, or they use a shared policy network to allow for coarse knowledge sharing between policies, which is also not very efficient. To improve the sample efficiency of MORL, the researchers propose a new method called Q-Pensieve.
Technical Explanation
Q-Pensieve is a policy improvement scheme that stores a collection of Q-snapshots, which are the learned Q-networks from past iterations. This allows Q-Pensieve to jointly determine the policy update direction, enabling data sharing at the policy level. The researchers show that Q-Pensieve can be naturally integrated with soft policy iteration, which has a convergence guarantee.
To implement Q-Pensieve, the researchers propose the technique of a Q replay buffer, which stores the learned Q-networks from past iterations. This allows for a practical actor-critic implementation of the Q-Pensieve method.
Through extensive experiments and an ablation study, the researchers demonstrate that Q-Pensieve can outperform benchmark MORL methods on a variety of MORL benchmark tasks, while using much fewer samples.
Critical Analysis
The paper provides a novel and promising approach to improving the sample efficiency of MORL algorithms. The Q-Pensieve method, with its use of Q-snapshots and the Q replay buffer, is a clever way to enable data sharing at the policy level, which is a key challenge in MORL.
However, the paper does not discuss the potential limitations or caveats of the Q-Pensieve method. For example, it's unclear how the method would scale to problems with a large number of objectives, or how sensitive it is to the choice of hyperparameters. Additionally, the paper does not address potential issues with the stability or convergence of the method, especially when dealing with complex, high-dimensional environments.
Further research could explore the robustness and generalization of Q-Pensieve, as well as its performance on more realistic, real-world control problems. Comparisons to other sample-efficient MORL methods, such as those using multi-fidelity techniques, could also provide valuable insights.
Conclusion
The Q-Pensieve method proposed in this paper represents a promising step towards improving the sample efficiency of MORL algorithms. By leveraging a collection of Q-snapshots and a Q replay buffer, the method enables effective data sharing at the policy level, allowing it to outperform benchmark MORL methods on a variety of tasks. While the paper does not address all potential limitations, the core ideas behind Q-Pensieve are compelling and could have significant implications for real-world control problems that involve balancing multiple, conflicting objectives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Q-Pensieve: Boosting Sample Efficiency of Multi-Objective RL Through Memory Sharing of Q-Snapshots
Wei Hung, Bo-Kai Huang, Ping-Chun Hsieh, Xi Liu
Many real-world continuous control problems are in the dilemma of weighing the pros and cons, multi-objective reinforcement learning (MORL) serves as a generic framework of learning control policies for different preferences over objectives. However, the existing MORL methods either rely on multiple passes of explicit search for finding the Pareto front and therefore are not sample-efficient, or utilizes a shared policy network for coarse knowledge sharing among policies. To boost the sample efficiency of MORL, we propose Q-Pensieve, a policy improvement scheme that stores a collection of Q-snapshots to jointly determine the policy update direction and thereby enables data sharing at the policy level. We show that Q-Pensieve can be naturally integrated with soft policy iteration with convergence guarantee. To substantiate this concept, we propose the technique of Q replay buffer, which stores the learned Q-networks from the past iterations, and arrive at a practical actor-critic implementation. Through extensive experiments and an ablation study, we demonstrate that with much fewer samples, the proposed algorithm can outperform the benchmark MORL methods on a variety of MORL benchmark tasks.
Read more7/26/2024

0
New!C-MORL: Multi-Objective Reinforcement Learning through Efficient Discovery of Pareto Front
Ruohong Liu, Yuxin Pan, Linjie Xu, Lei Song, Pengcheng You, Yize Chen, Jiang Bian
Multi-objective reinforcement learning (MORL) excels at handling rapidly changing preferences in tasks that involve multiple criteria, even for unseen preferences. However, previous dominating MORL methods typically generate a fixed policy set or preference-conditioned policy through multiple training iterations exclusively for sampled preference vectors, and cannot ensure the efficient discovery of the Pareto front. Furthermore, integrating preferences into the input of policy or value functions presents scalability challenges, in particular as the dimension of the state and preference space grow, which can complicate the learning process and hinder the algorithm's performance on more complex tasks. To address these issues, we propose a two-stage Pareto front discovery algorithm called Constrained MORL (C-MORL), which serves as a seamless bridge between constrained policy optimization and MORL. Concretely, a set of policies is trained in parallel in the initialization stage, with each optimized towards its individual preference over the multiple objectives. Then, to fill the remaining vacancies in the Pareto front, the constrained optimization steps are employed to maximize one objective while constraining the other objectives to exceed a predefined threshold. Empirically, compared to recent advancements in MORL methods, our algorithm achieves more consistent and superior performances in terms of hypervolume, expected utility, and sparsity on both discrete and continuous control tasks, especially with numerous objectives (up to nine objectives in our experiments).
Read more10/4/2024

0
Memory-Enhanced Neural Solvers for Efficient Adaptation in Combinatorial Optimization
Felix Chalumeau, Refiloe Shabe, Noah de Nicola, Arnu Pretorius, Thomas D. Barrett, Nathan Grinsztajn
Combinatorial Optimization is crucial to numerous real-world applications, yet still presents challenges due to its (NP-)hard nature. Amongst existing approaches, heuristics often offer the best trade-off between quality and scalability, making them suitable for industrial use. While Reinforcement Learning (RL) offers a flexible framework for designing heuristics, its adoption over handcrafted heuristics remains incomplete within industrial solvers. Existing learned methods still lack the ability to adapt to specific instances and fully leverage the available computational budget. The current best methods either rely on a collection of pre-trained policies, or on data-inefficient fine-tuning; hence failing to fully utilize newly available information within the constraints of the budget. In response, we present MEMENTO, an RL approach that leverages memory to improve the adaptation of neural solvers at inference time. MEMENTO enables updating the action distribution dynamically based on the outcome of previous decisions. We validate its effectiveness on benchmark problems, in particular Traveling Salesman and Capacitated Vehicle Routing, demonstrating it can successfully be combined with standard methods to boost their performance under a given budget, both in and out-of-distribution, improving their performance on all 12 evaluated tasks.
Read more6/26/2024
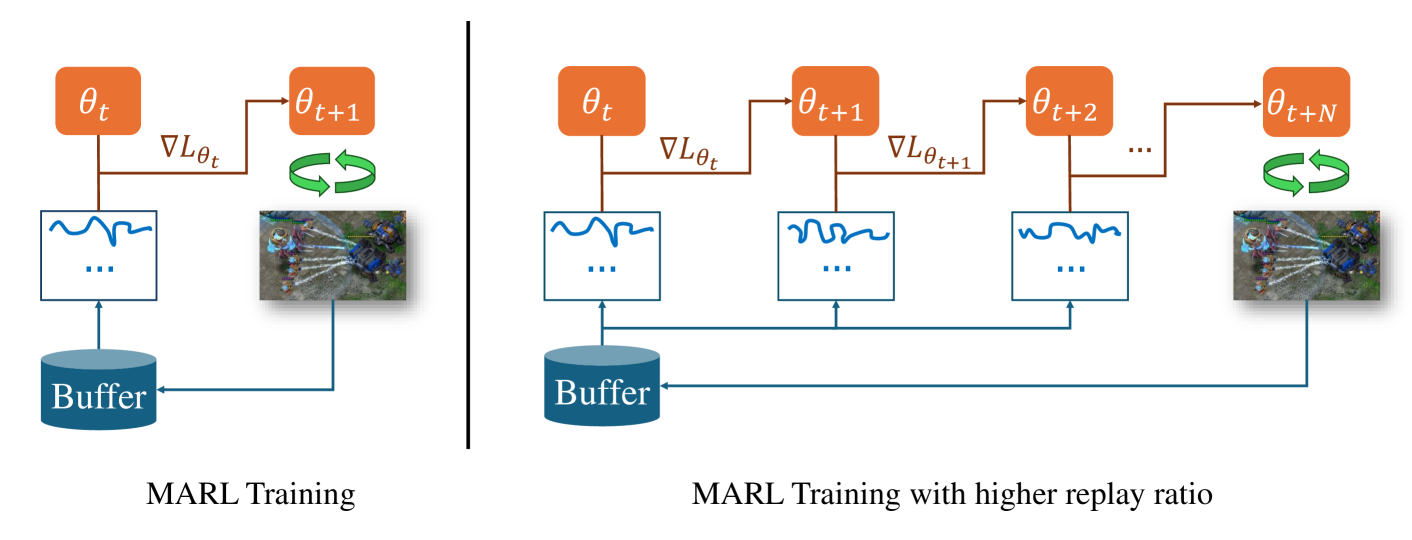
0
Higher Replay Ratio Empowers Sample-Efficient Multi-Agent Reinforcement Learning
Linjie Xu, Zichuan Liu, Alexander Dockhorn, Diego Perez-Liebana, Jinyu Wang, Lei Song, Jiang Bian
One of the notorious issues for Reinforcement Learning (RL) is poor sample efficiency. Compared to single agent RL, the sample efficiency for Multi-Agent Reinforcement Learning (MARL) is more challenging because of its inherent partial observability, non-stationary training, and enormous strategy space. Although much effort has been devoted to developing new methods and enhancing sample efficiency, we look at the widely used episodic training mechanism. In each training step, tens of frames are collected, but only one gradient step is made. We argue that this episodic training could be a source of poor sample efficiency. To better exploit the data already collected, we propose to increase the frequency of the gradient updates per environment interaction (a.k.a. Replay Ratio or Update-To-Data ratio). To show its generality, we evaluate $3$ MARL methods on $6$ SMAC tasks. The empirical results validate that a higher replay ratio significantly improves the sample efficiency for MARL algorithms. The codes to reimplement the results presented in this paper are open-sourced at https://anonymous.4open.science/r/rr_for_MARL-0D83/.
Read more4/16/2024