Meta-GPS++: Enhancing Graph Meta-Learning with Contrastive Learning and Self-Training

0

Sign in to get full access
Overview
- Introduces Meta-GPS++, a method that enhances graph meta-learning by incorporating contrastive learning and self-training.
- Aims to improve few-shot node classification performance on graphs.
- Combines meta-learning, contrastive learning, and self-training in a unified framework.
Plain English Explanation
Meta-GPS++ is a technique that builds on previous work in graph meta-learning to make it even better at learning how to classify nodes in graphs with limited training data.
The key idea is to use contrastive learning and self-training along with the meta-learning approach. Contrastive learning helps the model learn useful representations of the graph structure by identifying what makes nodes similar or different. Self-training allows the model to iteratively improve its own performance by generating additional training data for itself.
By combining these complementary techniques, Meta-GPS++ can learn more effective models for classifying nodes, especially when there is only a small amount of labeled training data available. This could be useful in real-world applications where obtaining labeled data for graphs can be challenging, such as in social network analysis or drug discovery.
Technical Explanation
Meta-GPS++ builds on the Graph Pyramid Shift (GPS) meta-learning framework, which learns to adapt graph neural network models to new tasks with limited data. Meta-GPS++ incorporates two key innovations:
-
Contrastive Learning: The model learns useful representations of the graph structure by training a contrastive objective that encourages the model to identify what makes nodes similar or different from each other. This helps the model extract more informative features from the graph.
-
Self-Training: The model iteratively generates its own additional training data by making predictions on unlabeled nodes and then using those predictions as pseudo-labels to further fine-tune the model. This allows the model to continuously improve its performance in a self-supervised manner.
The authors evaluate Meta-GPS++ on several few-shot node classification benchmarks and show that it outperforms previous meta-learning approaches, especially when the available training data is limited. The improvements are particularly notable on more challenging graph datasets where the graph structure is more complex.
Critical Analysis
The paper provides a thorough evaluation of Meta-GPS++ and demonstrates its advantages over prior meta-learning methods. However, a few potential limitations or areas for future work are worth noting:
-
The self-training process relies on the model's own predictions, which could propagate errors if the initial predictions are not sufficiently accurate. Incorporating human-labeled data or other external sources of information could help mitigate this issue.
-
The experiments are focused on node classification tasks, but the techniques could potentially be extended to other graph-related problems, such as link prediction or graph generation. Exploring the broader applicability of the approach would be an interesting direction for future research.
-
The paper does not provide a detailed analysis of the computational complexity or training time of Meta-GPS++, which could be an important consideration for real-world deployment, especially on large-scale graphs.
Overall, Meta-GPS++ represents a promising advance in graph meta-learning, and the combination of contrastive learning and self-training appears to be a fruitful direction for improving the sample efficiency of graph neural networks.
Conclusion
Meta-GPS++ is a novel graph meta-learning approach that enhances the standard meta-learning framework by incorporating contrastive learning and self-training. By learning more robust and generalizable representations of graph structure, Meta-GPS++ can achieve better few-shot node classification performance, particularly in data-limited scenarios.
The techniques introduced in this paper could have broader implications for improving the sample efficiency and adaptability of graph neural networks, which could be valuable in domains like social network analysis, drug discovery, and beyond. While the paper identifies some potential avenues for future work, Meta-GPS++ represents an important step forward in the field of graph meta-learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Meta-GPS++: Enhancing Graph Meta-Learning with Contrastive Learning and Self-Training
Yonghao Liu, Mengyu Li, Ximing Li, Lan Huang, Fausto Giunchiglia, Yanchun Liang, Xiaoyue Feng, Renchu Guan
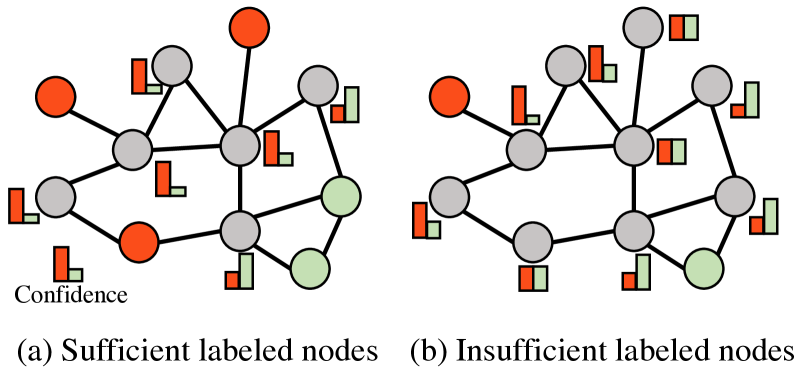
Node classification is an essential problem in graph learning. However, many models typically obtain unsatisfactory performance when applied to few-shot scenarios. Some studies have attempted to combine meta-learning with graph neural networks to solve few-shot node classification on graphs. Despite their promising performance, some limitations remain. First, they employ the node encoding mechanism of homophilic graphs to learn node embeddings, even in heterophilic graphs. Second, existing models based on meta-learning ignore the interference of randomness in the learning process. Third, they are trained using only limited labeled nodes within the specific task, without explicitly utilizing numerous unlabeled nodes. Finally, they treat almost all sampled tasks equally without customizing them for their uniqueness. To address these issues, we propose a novel framework for few-shot node classification called Meta-GPS++. Specifically, we first adopt an efficient method to learn discriminative node representations on homophilic and heterophilic graphs. Then, we leverage a prototype-based approach to initialize parameters and contrastive learning for regularizing the distribution of node embeddings. Moreover, we apply self-training to extract valuable information from unlabeled nodes. Additionally, we adopt S$^2$ (scaling & shifting) transformation to learn transferable knowledge from diverse tasks. The results on real-world datasets show the superiority of Meta-GPS++. Our code is available here.
Read more7/23/2024
0
Multi-View Subgraph Neural Networks: Self-Supervised Learning with Scarce Labeled Data
Zhenzhong Wang, Qingyuan Zeng, Wanyu Lin, Min Jiang, Kay Chen Tan
While graph neural networks (GNNs) have become the de-facto standard for graph-based node classification, they impose a strong assumption on the availability of sufficient labeled samples. This assumption restricts the classification performance of prevailing GNNs on many real-world applications suffering from low-data regimes. Specifically, features extracted from scarce labeled nodes could not provide sufficient supervision for the unlabeled samples, leading to severe over-fitting. In this work, we point out that leveraging subgraphs to capture long-range dependencies can augment the representation of a node with homophily properties, thus alleviating the low-data regime. However, prior works leveraging subgraphs fail to capture the long-range dependencies among nodes. To this end, we present a novel self-supervised learning framework, called multi-view subgraph neural networks (Muse), for handling long-range dependencies. In particular, we propose an information theory-based identification mechanism to identify two types of subgraphs from the views of input space and latent space, respectively. The former is to capture the local structure of the graph, while the latter captures the long-range dependencies among nodes. By fusing these two views of subgraphs, the learned representations can preserve the topological properties of the graph at large, including the local structure and long-range dependencies, thus maximizing their expressiveness for downstream node classification tasks. Experimental results show that Muse outperforms the alternative methods on node classification tasks with limited labeled data.
Read more4/22/2024
0
Enhancing Data-Limited Graph Neural Networks by Actively Distilling Knowledge from Large Language Models
Quan Li, Tianxiang Zhao, Lingwei Chen, Junjie Xu, Suhang Wang
Graphs are pervasive in the real-world, such as social network analysis, bioinformatics, and knowledge graphs. Graph neural networks (GNNs) have great ability in node classification, a fundamental task on graphs. Unfortunately, conventional GNNs still face challenges in scenarios with few labeled nodes, despite the prevalence of few-shot node classification tasks in real-world applications. To address this challenge, various approaches have been proposed, including graph meta-learning, transfer learning, and methods based on Large Language Models (LLMs). However, traditional meta-learning and transfer learning methods often require prior knowledge from base classes or fail to exploit the potential advantages of unlabeled nodes. Meanwhile, LLM-based methods may overlook the zero-shot capabilities of LLMs and rely heavily on the quality of generated contexts. In this paper, we propose a novel approach that integrates LLMs and GNNs, leveraging the zero-shot inference and reasoning capabilities of LLMs and employing a Graph-LLM-based active learning paradigm to enhance GNNs' performance. Extensive experiments demonstrate the effectiveness of our model in improving node classification accuracy with considerably limited labeled data, surpassing state-of-the-art baselines by significant margins.
Read more9/5/2024

0
A Survey of Few-Shot Learning on Graphs: from Meta-Learning to Pre-Training and Prompt Learning
Xingtong Yu, Yuan Fang, Zemin Liu, Yuxia Wu, Zhihao Wen, Jianyuan Bo, Xinming Zhang, Steven C. H. Hoi
Graph representation learning, a critical step in graph-centric tasks, has seen significant advancements. Earlier techniques often operate in an end-to-end setting, which heavily rely on the availability of ample labeled data. This constraint has spurred the emergence of few-shot learning on graphs, where only a few labels are available for each task. Given the extensive literature in this field, this survey endeavors to synthesize recent developments, provide comparative insights, and identify future directions. We systematically categorize existing studies based on two major taxonomies: (1) Problem taxonomy, which explores different types of data scarcity problems and their applications, and (2) Technique taxonomy, which details key strategies for addressing these data-scarce few-shot problems. The techniques can be broadly categorized into meta-learning, pre-training, and hybrid approaches, with a finer-grained classification in each category to aid readers in their method selection process. Within each category, we analyze the relationships among these methods and compare their strengths and limitations. Finally, we outline prospective directions for few-shot learning on graphs to catalyze continued innovation in this field. The website for this survey can be accessed by url{https://github.com/smufang/fewshotgraph}.
Read more9/23/2024