Meta-Gradient Search Control: A Method for Improving the Efficiency of Dyna-style Planning
2406.19561
0
0

Abstract
We study how a Reinforcement Learning (RL) system can remain sample-efficient when learning from an imperfect model of the environment. This is particularly challenging when the learning system is resource-constrained and in continual settings, where the environment dynamics change. To address these challenges, our paper introduces an online, meta-gradient algorithm that tunes a probability with which states are queried during Dyna-style planning. Our study compares the aggregate, empirical performance of this meta-gradient method to baselines that employ conventional sampling strategies. Results indicate that our method improves efficiency of the planning process, which, as a consequence, improves the sample-efficiency of the overall learning process. On the whole, we observe that our meta-learned solutions avoid several pathologies of conventional planning approaches, such as sampling inaccurate transitions and those that stall credit assignment. We believe these findings could prove useful, in future work, for designing model-based RL systems at scale.
Create account to get full access
Overview
- Proposes a method called "Meta-Gradient Search Control" to improve the efficiency of Dyna-style planning, a popular technique in reinforcement learning.
- Dyna-style planning involves learning a model of the environment and using it to generate simulated experiences to supplement real-world interactions.
- The proposed method aims to intelligently allocate the limited planning budget to the most promising states, leading to faster learning and better performance.
Plain English Explanation
Meta-Gradient Search Control is a technique that can make Dyna-style planning more efficient. Dyna-style planning is a common approach in reinforcement learning, where an agent learns a model of the environment and then uses that model to generate simulated experiences. These simulated experiences are then used to supplement the agent's actual interactions with the environment, helping it learn faster.
The key idea behind Meta-Gradient Search Control is to intelligently allocate the limited planning budget (the time and computational resources available for simulating experiences) to the most promising states. By focusing the planning on the states that are likely to be most informative, the agent can learn more efficiently and achieve better performance.
This is achieved by using a "meta-gradient" - a gradient that captures how the planning budget should be allocated to different states. The authors show that this meta-gradient can be estimated and used to guide the planning process, leading to faster learning and better results.
Technical Explanation
The paper introduces Meta-Gradient Search Control, a method for improving the efficiency of Dyna-style planning. Dyna-style planning involves learning a model of the environment and using it to generate simulated experiences, which are then used to supplement the agent's real-world interactions.
The key innovation of Meta-Gradient Search Control is the use of a "meta-gradient" to guide the allocation of the limited planning budget. This meta-gradient captures how the planning budget should be distributed across different states in order to maximize the agent's learning and performance.
The authors derive the meta-gradient mathematically and show how it can be estimated and used to direct the planning process. They evaluate the method on a range of reinforcement learning tasks and demonstrate that it can lead to significant improvements in sample efficiency and final performance compared to standard Dyna-style planning.
Critical Analysis
The paper presents a novel and promising approach for enhancing the efficiency of Dyna-style planning. The proposed Meta-Gradient Search Control method is well-motivated and the authors provide a solid theoretical and empirical analysis to support its effectiveness.
One potential limitation is that the meta-gradient estimation requires access to the environment model, which may not always be available in real-world scenarios. The authors acknowledge this and discuss potential ways to overcome this limitation, such as using model-free meta-gradient estimation techniques.
Additionally, the paper does not explore the scalability of the method to larger and more complex environments. Further research would be needed to understand how well the approach generalizes to more challenging reinforcement learning problems.
Overall, the research presented in this paper is a valuable contribution to the field of reinforcement learning, and the Meta-Gradient Search Control technique has the potential to significantly improve the efficiency of planning-based reinforcement learning algorithms.
Conclusion
The paper introduces Meta-Gradient Search Control, a novel method for enhancing the efficiency of Dyna-style planning in reinforcement learning. By using a meta-gradient to guide the allocation of the limited planning budget, the technique can lead to faster learning and better performance compared to standard Dyna-style planning approaches.
The research presented in this paper represents an important step forward in the field of reinforcement learning, as improving the efficiency of planning-based methods can have significant implications for the application of these techniques in real-world scenarios. While the approach has some limitations, the authors have demonstrated its effectiveness and laid the groundwork for further developments in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A New View on Planning in Online Reinforcement Learning
Kevin Roice, Parham Mohammad Panahi, Scott M. Jordan, Adam White, Martha White
0
0
This paper investigates a new approach to model-based reinforcement learning using background planning: mixing (approximate) dynamic programming updates and model-free updates, similar to the Dyna architecture. Background planning with learned models is often worse than model-free alternatives, such as Double DQN, even though the former uses significantly more memory and computation. The fundamental problem is that learned models can be inaccurate and often generate invalid states, especially when iterated many steps. In this paper, we avoid this limitation by constraining background planning to a set of (abstract) subgoals and learning only local, subgoal-conditioned models. This goal-space planning (GSP) approach is more computationally efficient, naturally incorporates temporal abstraction for faster long-horizon planning and avoids learning the transition dynamics entirely. We show that our GSP algorithm can propagate value from an abstract space in a manner that helps a variety of base learners learn significantly faster in different domains.
6/4/2024

Model-Agnostic Zeroth-Order Policy Optimization for Meta-Learning of Ergodic Linear Quadratic Regulators
Yunian Pan, Quanyan Zhu
0
0
Meta-learning has been proposed as a promising machine learning topic in recent years, with important applications to image classification, robotics, computer games, and control systems. In this paper, we study the problem of using meta-learning to deal with uncertainty and heterogeneity in ergodic linear quadratic regulators. We integrate the zeroth-order optimization technique with a typical meta-learning method, proposing an algorithm that omits the estimation of policy Hessian, which applies to tasks of learning a set of heterogeneous but similar linear dynamic systems. The induced meta-objective function inherits important properties of the original cost function when the set of linear dynamic systems are meta-learnable, allowing the algorithm to optimize over a learnable landscape without projection onto the feasible set. We provide a convergence result for the exact gradient descent process by analyzing the boundedness and smoothness of the gradient for the meta-objective, which justify the proposed algorithm with gradient estimation error being small. We also provide a numerical example to corroborate this perspective.
5/28/2024
Sample-Efficient Robust Multi-Agent Reinforcement Learning in the Face of Environmental Uncertainty
Laixi Shi, Eric Mazumdar, Yuejie Chi, Adam Wierman
0
0
To overcome the sim-to-real gap in reinforcement learning (RL), learned policies must maintain robustness against environmental uncertainties. While robust RL has been widely studied in single-agent regimes, in multi-agent environments, the problem remains understudied -- despite the fact that the problems posed by environmental uncertainties are often exacerbated by strategic interactions. This work focuses on learning in distributionally robust Markov games (RMGs), a robust variant of standard Markov games, wherein each agent aims to learn a policy that maximizes its own worst-case performance when the deployed environment deviates within its own prescribed uncertainty set. This results in a set of robust equilibrium strategies for all agents that align with classic notions of game-theoretic equilibria. Assuming a non-adaptive sampling mechanism from a generative model, we propose a sample-efficient model-based algorithm (DRNVI) with finite-sample complexity guarantees for learning robust variants of various notions of game-theoretic equilibria. We also establish an information-theoretic lower bound for solving RMGs, which confirms the near-optimal sample complexity of DRNVI with respect to problem-dependent factors such as the size of the state space, the target accuracy, and the horizon length.
5/10/2024
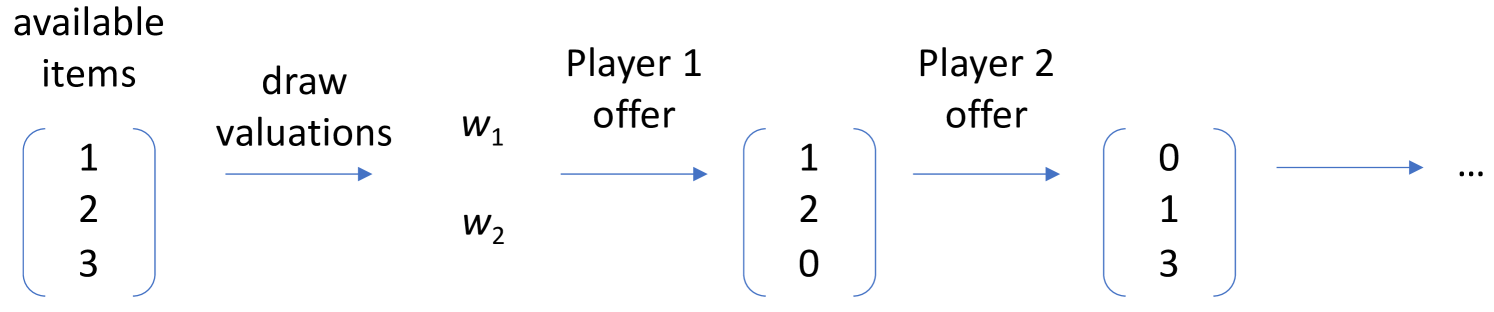
A Meta-Game Evaluation Framework for Deep Multiagent Reinforcement Learning
Zun Li, Michael P. Wellman
0
0
Evaluating deep multiagent reinforcement learning (MARL) algorithms is complicated by stochasticity in training and sensitivity of agent performance to the behavior of other agents. We propose a meta-game evaluation framework for deep MARL, by framing each MARL algorithm as a meta-strategy, and repeatedly sampling normal-form empirical games over combinations of meta-strategies resulting from different random seeds. Each empirical game captures both self-play and cross-play factors across seeds. These empirical games provide the basis for constructing a sampling distribution, using bootstrapping, over a variety of game analysis statistics. We use this approach to evaluate state-of-the-art deep MARL algorithms on a class of negotiation games. From statistics on individual payoffs, social welfare, and empirical best-response graphs, we uncover strategic relationships among self-play, population-based, model-free, and model-based MARL methods.We also investigate the effect of run-time search as a meta-strategy operator, and find via meta-game analysis that the search version of a meta-strategy generally leads to improved performance.
5/2/2024