A Meta-Game Evaluation Framework for Deep Multiagent Reinforcement Learning
2405.00243
0
0
Abstract
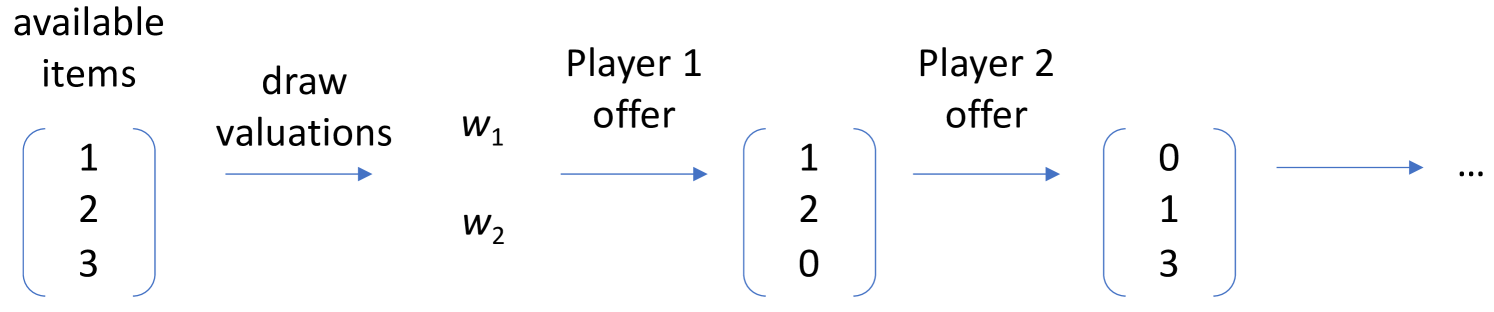
Evaluating deep multiagent reinforcement learning (MARL) algorithms is complicated by stochasticity in training and sensitivity of agent performance to the behavior of other agents. We propose a meta-game evaluation framework for deep MARL, by framing each MARL algorithm as a meta-strategy, and repeatedly sampling normal-form empirical games over combinations of meta-strategies resulting from different random seeds. Each empirical game captures both self-play and cross-play factors across seeds. These empirical games provide the basis for constructing a sampling distribution, using bootstrapping, over a variety of game analysis statistics. We use this approach to evaluate state-of-the-art deep MARL algorithms on a class of negotiation games. From statistics on individual payoffs, social welfare, and empirical best-response graphs, we uncover strategic relationships among self-play, population-based, model-free, and model-based MARL methods.We also investigate the effect of run-time search as a meta-strategy operator, and find via meta-game analysis that the search version of a meta-strategy generally leads to improved performance.
Create account to get full access
Overview
- Introduces a meta-game evaluation framework for assessing the performance of deep multiagent reinforcement learning (MARL) systems
- Proposes a set of metrics to quantify the abilities of MARL agents, including their robustness, adaptability, and sample efficiency
- Demonstrates the framework on several MARL benchmarks, providing insights into the strengths and weaknesses of different MARL algorithms
Plain English Explanation
This paper presents a new way to evaluate the performance of deep multiagent reinforcement learning (MARL) systems. MARL is a field of artificial intelligence that focuses on training multiple agents to interact and cooperate in complex environments. The researchers developed a "meta-game" evaluation framework that uses a set of specialized metrics to assess the capabilities of MARL agents, such as how robust they are to changes in the environment, how quickly they can adapt to new situations, and how efficiently they can learn.
The researchers then applied this evaluation framework to several MARL benchmarks, which are standardized testing environments used to compare different MARL algorithms. By analyzing the performance of various MARL algorithms across these benchmarks, the researchers were able to gain insights into the strengths and weaknesses of different approaches. For example, they might find that one algorithm is very good at learning quickly but struggles with adapting to changes, while another algorithm is more robust but less sample-efficient.
This evaluation framework provides a more comprehensive way to assess the capabilities of MARL systems, going beyond just measuring their performance on specific tasks. By using this framework, researchers and developers can better understand the strengths and weaknesses of different MARL algorithms, which can help them design more effective and versatile MARL systems for real-world applications.
Technical Explanation
The paper introduces a meta-game evaluation framework for assessing the performance of deep multiagent reinforcement learning (MARL) systems. The framework consists of a set of metrics that quantify the abilities of MARL agents, including their robustness, adaptability, and sample efficiency.
To evaluate robustness, the framework measures how well the agents perform when facing adversarial perturbations or changes in the environment. Adaptability is assessed by testing the agents' ability to quickly learn and adjust to new situations or tasks. Sample efficiency is measured by tracking how quickly the agents can learn and improve their performance with limited training data.
The researchers applied this evaluation framework to several MARL benchmarks, including cooperative navigation, predator-prey, and two-player games. By analyzing the performance of different MARL algorithms across these benchmarks, the researchers were able to gain insights into the strengths and weaknesses of various approaches.
For example, the results showed that some algorithms were highly sample-efficient, able to learn quickly with limited training data, but struggled with adaptability. Other algorithms were more robust to changes in the environment but less sample-efficient.
The meta-game evaluation framework provides a more comprehensive way to assess the capabilities of MARL systems, going beyond just measuring their performance on specific tasks. By using this framework, researchers and developers can better understand the trade-offs and nuances of different MARL algorithms, which can help them design more effective and versatile MARL systems for real-world applications.
Critical Analysis
The meta-game evaluation framework proposed in this paper is a valuable contribution to the field of MARL, as it provides a more holistic way to assess the capabilities of MARL systems. By focusing on metrics like robustness, adaptability, and sample efficiency, the framework sheds light on important aspects of MARL performance that are often overlooked in traditional benchmarking approaches.
One potential limitation of the framework is that it may not capture all the relevant factors that determine the real-world performance of MARL systems. For example, the framework does not explicitly consider the scalability of MARL algorithms or their ability to handle partial observability or communication constraints, which are important factors in many real-world applications.
Additionally, the framework relies on the availability of well-designed MARL benchmarks, which can be challenging to develop and may not fully reflect the complexity of real-world scenarios. As the authors note, further research is needed to explore the generalizability of the framework and its applicability to a broader range of MARL domains.
Despite these limitations, the meta-game evaluation framework represents a significant step forward in the assessment of MARL systems. By providing a more nuanced and comprehensive evaluation approach, this framework can help researchers and developers design more effective and versatile MARL solutions for real-world applications.
Conclusion
This paper introduces a meta-game evaluation framework for assessing the performance of deep multiagent reinforcement learning (MARL) systems. The framework uses a set of specialized metrics to quantify the abilities of MARL agents, including their robustness, adaptability, and sample efficiency.
By applying this evaluation framework to several MARL benchmarks, the researchers were able to gain insights into the strengths and weaknesses of different MARL algorithms. This information can help researchers and developers design more effective and versatile MARL systems for real-world applications, where factors like robustness, adaptability, and sample efficiency are crucial.
The meta-game evaluation framework represents a significant advancement in the assessment of MARL systems, going beyond traditional performance-based benchmarks to provide a more comprehensive and nuanced understanding of MARL capabilities. As the field of MARL continues to evolve, this framework can serve as a valuable tool for guiding research and development efforts in the pursuit of more intelligent and capable multiagent systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
MESA: Cooperative Meta-Exploration in Multi-Agent Learning through Exploiting State-Action Space Structure
Zhicheng Zhang, Yancheng Liang, Yi Wu, Fei Fang
0
0
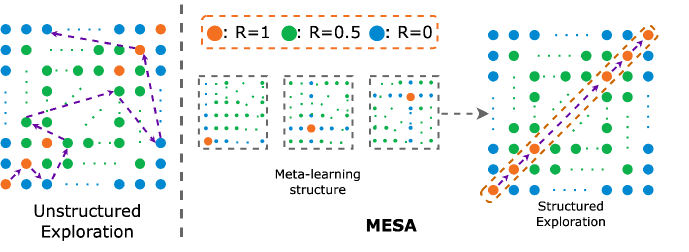
Multi-agent reinforcement learning (MARL) algorithms often struggle to find strategies close to Pareto optimal Nash Equilibrium, owing largely to the lack of efficient exploration. The problem is exacerbated in sparse-reward settings, caused by the larger variance exhibited in policy learning. This paper introduces MESA, a novel meta-exploration method for cooperative multi-agent learning. It learns to explore by first identifying the agents' high-rewarding joint state-action subspace from training tasks and then learning a set of diverse exploration policies to cover the subspace. These trained exploration policies can be integrated with any off-policy MARL algorithm for test-time tasks. We first showcase MESA's advantage in a multi-step matrix game. Furthermore, experiments show that with learned exploration policies, MESA achieves significantly better performance in sparse-reward tasks in several multi-agent particle environments and multi-agent MuJoCo environments, and exhibits the ability to generalize to more challenging tasks at test time.
5/3/2024

Efficient Multi-agent Reinforcement Learning by Planning
Qihan Liu, Jianing Ye, Xiaoteng Ma, Jun Yang, Bin Liang, Chongjie Zhang
0
0
Multi-agent reinforcement learning (MARL) algorithms have accomplished remarkable breakthroughs in solving large-scale decision-making tasks. Nonetheless, most existing MARL algorithms are model-free, limiting sample efficiency and hindering their applicability in more challenging scenarios. In contrast, model-based reinforcement learning (MBRL), particularly algorithms integrating planning, such as MuZero, has demonstrated superhuman performance with limited data in many tasks. Hence, we aim to boost the sample efficiency of MARL by adopting model-based approaches. However, incorporating planning and search methods into multi-agent systems poses significant challenges. The expansive action space of multi-agent systems often necessitates leveraging the nearly-independent property of agents to accelerate learning. To tackle this issue, we propose the MAZero algorithm, which combines a centralized model with Monte Carlo Tree Search (MCTS) for policy search. We design a novel network structure to facilitate distributed execution and parameter sharing. To enhance search efficiency in deterministic environments with sizable action spaces, we introduce two novel techniques: Optimistic Search Lambda (OS($lambda$)) and Advantage-Weighted Policy Optimization (AWPO). Extensive experiments on the SMAC benchmark demonstrate that MAZero outperforms model-free approaches in terms of sample efficiency and provides comparable or better performance than existing model-based methods in terms of both sample and computational efficiency. Our code is available at https://github.com/liuqh16/MAZero.
5/21/2024
🏅
What is the Solution for State-Adversarial Multi-Agent Reinforcement Learning?
Songyang Han, Sanbao Su, Sihong He, Shuo Han, Haizhao Yang, Shaofeng Zou, Fei Miao
0
0
Various methods for Multi-Agent Reinforcement Learning (MARL) have been developed with the assumption that agents' policies are based on accurate state information. However, policies learned through Deep Reinforcement Learning (DRL) are susceptible to adversarial state perturbation attacks. In this work, we propose a State-Adversarial Markov Game (SAMG) and make the first attempt to investigate different solution concepts of MARL under state uncertainties. Our analysis shows that the commonly used solution concepts of optimal agent policy and robust Nash equilibrium do not always exist in SAMGs. To circumvent this difficulty, we consider a new solution concept called robust agent policy, where agents aim to maximize the worst-case expected state value. We prove the existence of robust agent policy for finite state and finite action SAMGs. Additionally, we propose a Robust Multi-Agent Adversarial Actor-Critic (RMA3C) algorithm to learn robust policies for MARL agents under state uncertainties. Our experiments demonstrate that our algorithm outperforms existing methods when faced with state perturbations and greatly improves the robustness of MARL policies. Our code is public on https://songyanghan.github.io/what_is_solution/.
4/15/2024
Higher Replay Ratio Empowers Sample-Efficient Multi-Agent Reinforcement Learning
Linjie Xu, Zichuan Liu, Alexander Dockhorn, Diego Perez-Liebana, Jinyu Wang, Lei Song, Jiang Bian
0
0
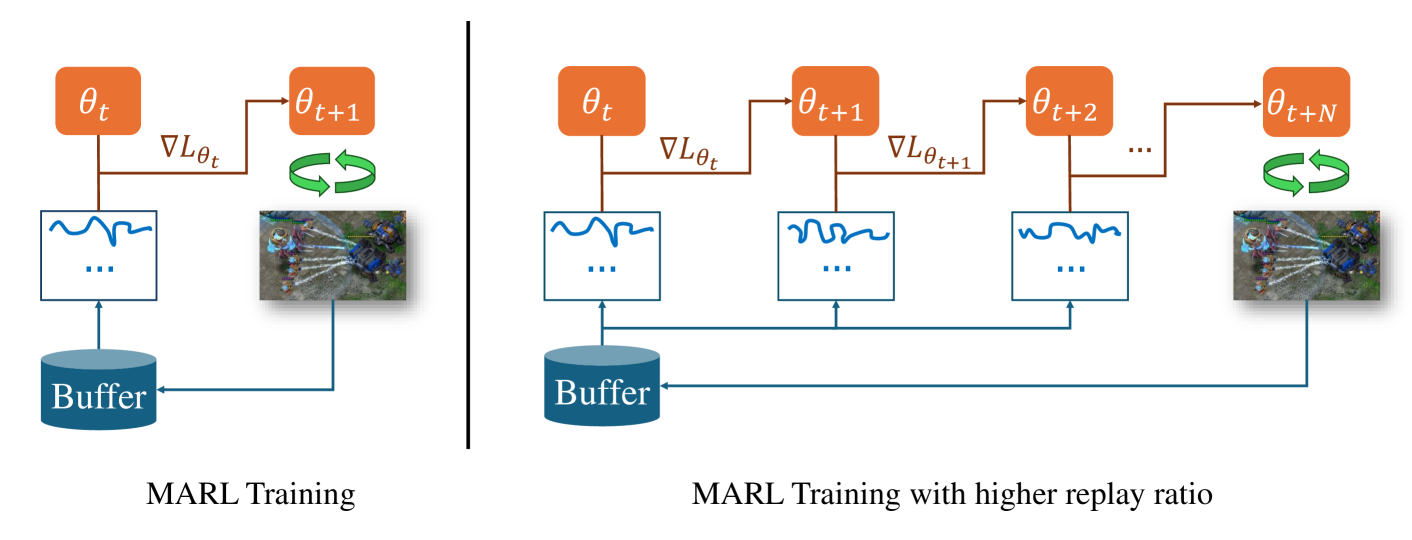
One of the notorious issues for Reinforcement Learning (RL) is poor sample efficiency. Compared to single agent RL, the sample efficiency for Multi-Agent Reinforcement Learning (MARL) is more challenging because of its inherent partial observability, non-stationary training, and enormous strategy space. Although much effort has been devoted to developing new methods and enhancing sample efficiency, we look at the widely used episodic training mechanism. In each training step, tens of frames are collected, but only one gradient step is made. We argue that this episodic training could be a source of poor sample efficiency. To better exploit the data already collected, we propose to increase the frequency of the gradient updates per environment interaction (a.k.a. Replay Ratio or Update-To-Data ratio). To show its generality, we evaluate $3$ MARL methods on $6$ SMAC tasks. The empirical results validate that a higher replay ratio significantly improves the sample efficiency for MARL algorithms. The codes to reimplement the results presented in this paper are open-sourced at https://anonymous.4open.science/r/rr_for_MARL-0D83/.
4/16/2024