Metadata-enhanced contrastive learning from retinal optical coherence tomography images

0
💬
Sign in to get full access
Overview
- Deep learning has potential to automate medical image analysis tasks like screening, monitoring, and grading disease.
- Pretraining models on large natural image datasets using contrastive learning can help them extract robust and generalizable features.
- However, applying standard contrastive methods to medical image datasets presents two key challenges.
Plain English Explanation
Deep learning models have shown promising results for automating various medical image analysis tasks, such as screening patients for diseases, tracking disease progression over time, and grading the severity of medical conditions. One way to train these models effectively is through a technique called contrastive learning. This involves pretraining the model on a large dataset of natural images, which helps the model learn general visual features that can then be applied to medical images.
However, directly applying standard contrastive learning methods to medical image datasets can run into two main issues. First, some of the image transformations that are typically used to create contrasting image pairs for contrastive learning don't work as well for medical images as they do for natural images. Second, the assumption made by standard contrastive methods - that any two images are dissimilar - doesn't hold true for medical datasets, where multiple images may depict the same anatomy or disease state, especially in longitudinal datasets that track the same patients over time.
Technical Explanation
This paper proposes a novel approach to address these challenges by enhancing standard contrastive learning frameworks with the use of readily available patient metadata. The key idea is to use information like patient identity, eye position (left or right), and time series data to better approximate the true relationships between images in the contrastive training process.
The authors evaluate their metadata-enhanced contrastive learning approach on two large longitudinal datasets containing over 170,000 retinal OCT images from nearly 8,000 patients with age-related macular degeneration (AMD). They find that this method outperforms both standard contrastive learning and a retinal image foundation model on five out of six downstream image-level tasks related to AMD. Due to its modular design, the proposed approach can be readily tested and applied to incorporate available metadata into the contrastive pretraining of models for a variety of medical imaging tasks.
Critical Analysis
The paper does a good job of identifying and addressing key challenges in applying contrastive learning to medical image datasets. The use of readily available metadata to better inform the contrastive relationships between images is a clever and practical solution. The authors also note that their approach is modular, making it easy to test and apply to other medical imaging domains.
However, the paper does not discuss any potential limitations or caveats of the proposed method. For example, the reliance on specific types of metadata (patient identity, eye position, time series) may limit the generalizability of the approach to datasets without such information. Additionally, the paper does not explore how the quality or completeness of the metadata might impact the performance of the contrastive pretraining.
Further research could investigate the robustness of the metadata-enhanced contrastive learning approach to missing or noisy metadata, as well as its applicability to a wider range of medical imaging domains and downstream tasks. Exploring the interpretability of the learned features and how they compare to clinically-relevant biomarkers could also be a valuable line of inquiry.
Conclusion
This paper presents a novel approach to address the challenges of applying contrastive learning to medical image datasets. By incorporating readily available patient metadata into the contrastive training process, the authors demonstrate improved performance on a range of downstream tasks related to age-related macular degeneration. The modular design of the proposed method makes it a promising and flexible tool for enhancing the label-efficiency of medical image analysis models through contrastive pretraining.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Metadata-enhanced contrastive learning from retinal optical coherence tomography images
Robbie Holland, Oliver Leingang, Hrvoje Bogunovi'c, Sophie Riedl, Lars Fritsche, Toby Prevost, Hendrik P. N. Scholl, Ursula Schmidt-Erfurth, Sobha Sivaprasad, Andrew J. Lotery, Daniel Rueckert, Martin J. Menten
Deep learning has potential to automate screening, monitoring and grading of disease in medical images. Pretraining with contrastive learning enables models to extract robust and generalisable features from natural image datasets, facilitating label-efficient downstream image analysis. However, the direct application of conventional contrastive methods to medical datasets introduces two domain-specific issues. Firstly, several image transformations which have been shown to be crucial for effective contrastive learning do not translate from the natural image to the medical image domain. Secondly, the assumption made by conventional methods, that any two images are dissimilar, is systematically misleading in medical datasets depicting the same anatomy and disease. This is exacerbated in longitudinal image datasets that repeatedly image the same patient cohort to monitor their disease progression over time. In this paper we tackle these issues by extending conventional contrastive frameworks with a novel metadata-enhanced strategy. Our approach employs widely available patient metadata to approximate the true set of inter-image contrastive relationships. To this end we employ records for patient identity, eye position (i.e. left or right) and time series information. In experiments using two large longitudinal datasets containing 170,427 retinal OCT images of 7,912 patients with age-related macular degeneration (AMD), we evaluate the utility of using metadata to incorporate the temporal dynamics of disease progression into pretraining. Our metadata-enhanced approach outperforms both standard contrastive methods and a retinal image foundation model in five out of six image-level downstream tasks related to AMD. Due to its modularity, our method can be quickly and cost-effectively tested to establish the potential benefits of including available metadata in contrastive pretraining.
Read more7/29/2024

0
Time-Equivariant Contrastive Learning for Degenerative Disease Progression in Retinal OCT
Taha Emre, Arunava Chakravarty, Dmitrii Lachinov, Antoine Rivail, Ursula Schmidt-Erfurth, Hrvoje Bogunovi'c
Contrastive pretraining provides robust representations by ensuring their invariance to different image transformations while simultaneously preventing representational collapse. Equivariant contrastive learning, on the other hand, provides representations sensitive to specific image transformations while remaining invariant to others. By introducing equivariance to time-induced transformations, such as disease-related anatomical changes in longitudinal imaging, the model can effectively capture such changes in the representation space. In this work, we pro-pose a Time-equivariant Contrastive Learning (TC) method. First, an encoder embeds two unlabeled scans from different time points of the same patient into the representation space. Next, a temporal equivariance module is trained to predict the representation of a later visit based on the representation from one of the previous visits and the corresponding time interval with a novel regularization loss term while preserving the invariance property to irrelevant image transformations. On a large longitudinal dataset, our model clearly outperforms existing equivariant contrastive methods in predicting progression from intermediate age-related macular degeneration (AMD) to advanced wet-AMD within a specified time-window.
Read more5/16/2024
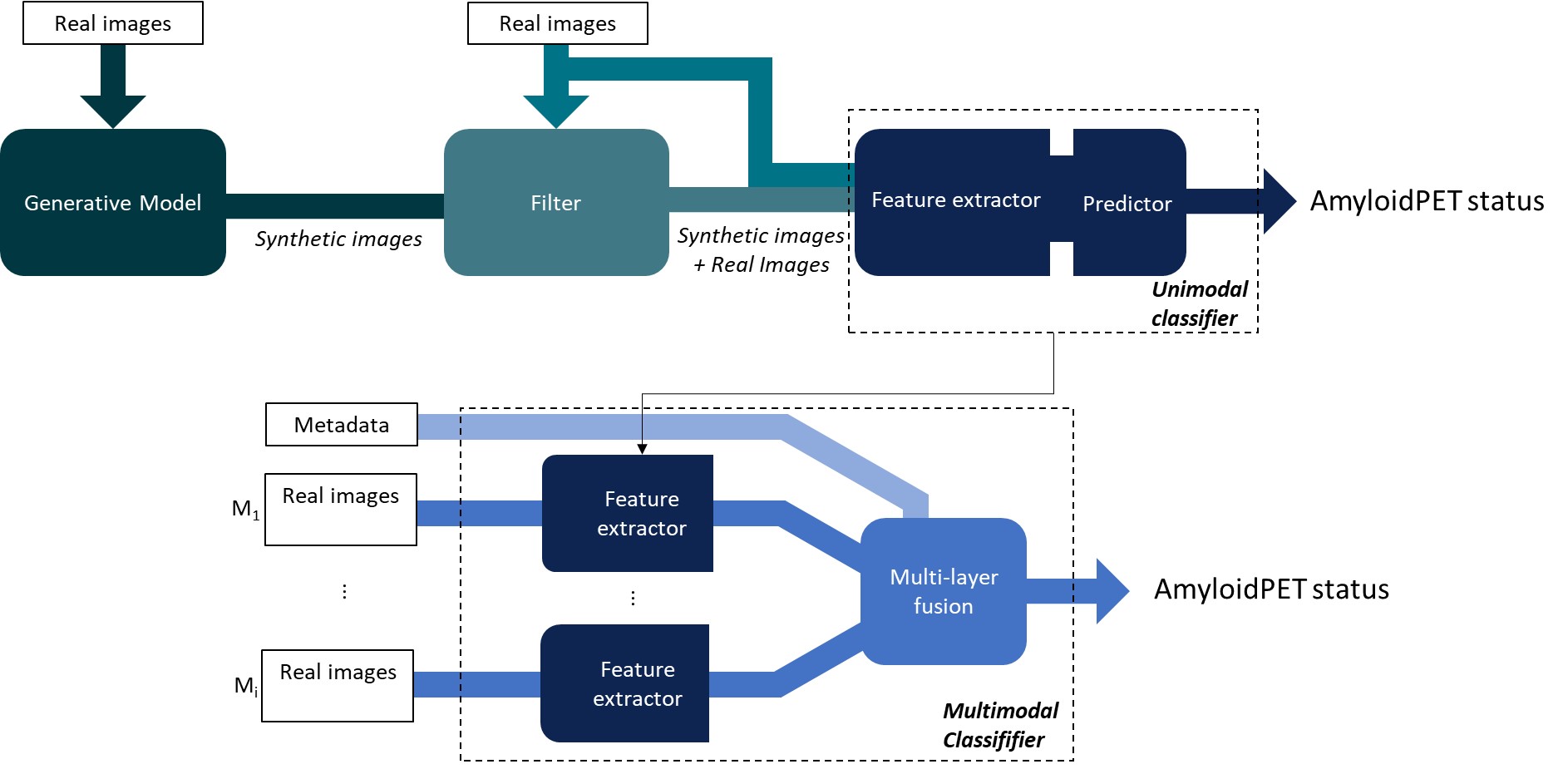
0
Generative artificial intelligence in ophthalmology: multimodal retinal images for the diagnosis of Alzheimer's disease with convolutional neural networks
I. R. Slootweg, M. Thach, K. R. Curro-Tafili, F. D. Verbraak, F. H. Bouwman, Y. A. L. Pijnenburg, J. F. Boer, J. H. P. de Kwisthout, L. Bagheriye, P. J. Gonz'alez
Background/Aim. This study aims to predict Amyloid Positron Emission Tomography (AmyloidPET) status with multimodal retinal imaging and convolutional neural networks (CNNs) and to improve the performance through pretraining with synthetic data. Methods. Fundus autofluorescence, optical coherence tomography (OCT), and OCT angiography images from 328 eyes of 59 AmyloidPET positive subjects and 108 AmyloidPET negative subjects were used for classification. Denoising Diffusion Probabilistic Models (DDPMs) were trained to generate synthetic images and unimodal CNNs were pretrained on synthetic data and finetuned on real data or trained solely on real data. Multimodal classifiers were developed to combine predictions of the four unimodal CNNs with patient metadata. Class activation maps of the unimodal classifiers provided insight into the network's attention to inputs. Results. DDPMs generated diverse, realistic images without memorization. Pretraining unimodal CNNs with synthetic data improved AUPR at most from 0.350 to 0.579. Integration of metadata in multimodal CNNs improved AUPR from 0.486 to 0.634, which was the best overall best classifier. Class activation maps highlighted relevant retinal regions which correlated with AD. Conclusion. Our method for generating and leveraging synthetic data has the potential to improve AmyloidPET prediction from multimodal retinal imaging. A DDPM can generate realistic and unique multimodal synthetic retinal images. Our best performing unimodal and multimodal classifiers were not pretrained on synthetic data, however pretraining with synthetic data slightly improved classification performance for two out of the four modalities.
Read more6/27/2024

0
Enhancing Retinal Disease Classification from OCTA Images via Active Learning Techniques
Jacob Thrasher, Annahita Amireskandari, Prashnna Gyawali
Eye diseases are common in older Americans and can lead to decreased vision and blindness. Recent advancements in imaging technologies allow clinicians to capture high-quality images of the retinal blood vessels via Optical Coherence Tomography Angiography (OCTA), which contain vital information for diagnosing these diseases and expediting preventative measures. OCTA provides detailed vascular imaging as compared to the solely structural information obtained by common OCT imaging. Although there have been considerable studies on OCT imaging, there have been limited to no studies exploring the role of artificial intelligence (AI) and machine learning (ML) approaches for predictive modeling with OCTA images. In this paper, we explore the use of deep learning to identify eye disease in OCTA images. However, due to the lack of labeled data, the straightforward application of deep learning doesn't necessarily yield good generalization. To this end, we utilize active learning to select the most valuable subset of data to train our model. We demonstrate that active learning subset selection greatly outperforms other strategies, such as inverse frequency class weighting, random undersampling, and oversampling, by up to 49% in F1 evaluation.
Read more7/23/2024