MetaLLM: A High-performant and Cost-efficient Dynamic Framework for Wrapping LLMs

0

Sign in to get full access
Overview
- Presents a novel framework called MetaLLM for dynamically wrapping and optimizing the use of large language models (LLMs)
- Aims to improve the performance and cost-efficiency of LLM deployment without modifying the underlying models
- Leverages meta-learning techniques to automatically learn an optimal assignment of LLM queries to available resources
Plain English Explanation
MetaLLM is a new system that helps make it easier and more efficient to use large language models (LLMs) like GPT-3 or BERT. LLMs are powerful AI models that can generate human-like text, but they can be expensive to run and sometimes perform poorly on specific tasks.
MetaLLM acts as a middle layer between the user and the LLM. It dynamically manages how the user's queries are sent to the LLM, optimizing things like speed and cost. For example, it might route simpler queries to a smaller, cheaper LLM model, while sending more complex ones to a larger, more capable (but more expensive) LLM. This helps get the best performance at the lowest cost.
MetaLLM uses 'meta-learning' techniques to automatically learn the best way to assign queries to LLMs based on the user's needs and the available resources. This means the system can adapt and improve over time without the user having to manually configure it.
The goal is to make it easier and more affordable for companies and developers to take advantage of powerful LLMs in their applications, without having to worry about the underlying complexity.
Technical Explanation
The key innovation in MetaLLM is its use of meta-learning to dynamically optimize the assignment of LLM queries to available resources. The authors propose a multi-level architecture that consists of a meta-controller and multiple base LLM models.
The meta-controller is trained using model-agnostic meta-learning (MAML) to learn an optimal query assignment policy. This policy takes into account factors like the complexity of the query, the capabilities of each base LLM, and the current system load to determine the best LLM to use for a given request.
The authors evaluate MetaLLM on several benchmarks and real-world use cases, demonstrating significant improvements in both performance and cost-efficiency compared to static LLM deployments. For example, they show up to 2.3x speedups on language modeling tasks and up to 40% reduction in compute costs.
Critical Analysis
The MetaLLM framework is a promising approach to improving the practicality of LLMs, but there are a few potential limitations and areas for further research:
-
The meta-learning process used to train the query assignment policy may be computationally intensive and require significant upfront effort. The authors mention plans to explore more efficient meta-learning techniques like RouteLLM.
-
The current implementation only considers a single level of LLM abstraction. Extending the framework to support hierarchies of LLMs with different capabilities and costs could further improve the optimization potential.
-
The paper does not provide detailed analysis of the generalization capabilities of the learned policy. It would be valuable to understand how well the system performs on unseen queries or when the available LLM resources change over time.
-
The authors focus on language modeling tasks, but the broader applicability of MetaLLM to other LLM use cases, such as text generation or question answering, is not thoroughly explored.
Overall, MetaLLM represents an important step towards making LLMs more accessible and practical for a wide range of applications. Further research and real-world deployments will help refine the approach and address the identified limitations.
Conclusion
The MetaLLM framework introduces a novel way to improve the performance and cost-efficiency of deploying large language models (LLMs) without modifying the underlying models. By leveraging meta-learning techniques, the system can automatically learn an optimal policy for assigning queries to available LLM resources, taking into account factors like query complexity and system load.
The authors demonstrate the effectiveness of MetaLLM through extensive evaluations, showing significant improvements in both speed and cost-efficiency compared to static LLM deployments. While there are some areas for further research and refinement, this work represents an important step towards making powerful LLMs more accessible and practical for a wide range of applications and use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MetaLLM: A High-performant and Cost-efficient Dynamic Framework for Wrapping LLMs
Quang H. Nguyen, Duy C. Hoang, Juliette Decugis, Saurav Manchanda, Nitesh V. Chawla, Khoa D. Doan
The rapid progress in machine learning (ML) has brought forth many large language models (LLMs) that excel in various tasks and areas. These LLMs come with different abilities and costs in terms of computation or pricing. Since the demand for each query can vary, e.g., because of the queried domain or its complexity, defaulting to one LLM in an application is not usually the best choice, whether it is the biggest, priciest, or even the one with the best average test performance. Consequently, picking the right LLM that is both accurate and cost-effective for an application remains a challenge. In this paper, we introduce MetaLLM, a framework that dynamically and intelligently routes each query to the optimal LLM (among several available LLMs) for classification tasks, achieving significantly improved accuracy and cost-effectiveness. By framing the selection problem as a multi-armed bandit, MetaLLM balances prediction accuracy and cost efficiency under uncertainty. Our experiments, conducted on popular LLM platforms such as OpenAI's GPT models, Amazon's Titan, Anthropic's Claude, and Meta's LLaMa, showcase MetaLLM's efficacy in real-world scenarios, laying the groundwork for future extensions beyond classification tasks.
Read more7/25/2024
0
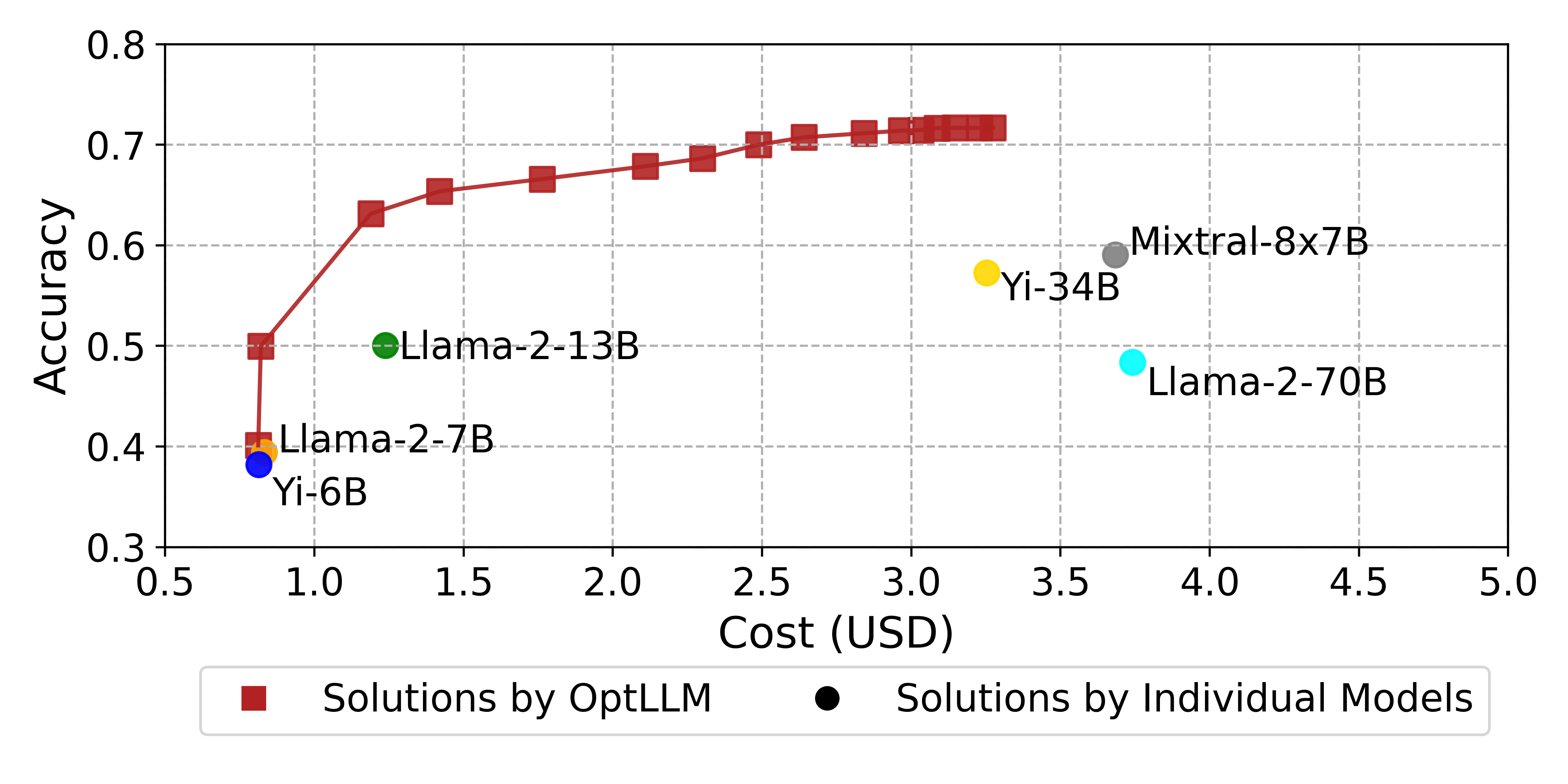
OptLLM: Optimal Assignment of Queries to Large Language Models
Yueyue Liu, Hongyu Zhang, Yuantian Miao, Van-Hoang Le, Zhiqiang Li
Large Language Models (LLMs) have garnered considerable attention owing to their remarkable capabilities, leading to an increasing number of companies offering LLMs as services. Different LLMs achieve different performance at different costs. A challenge for users lies in choosing the LLMs that best fit their needs, balancing cost and performance. In this paper, we propose a framework for addressing the cost-effective query allocation problem for LLMs. Given a set of input queries and candidate LLMs, our framework, named OptLLM, provides users with a range of optimal solutions to choose from, aligning with their budget constraints and performance preferences, including options for maximizing accuracy and minimizing cost. OptLLM predicts the performance of candidate LLMs on each query using a multi-label classification model with uncertainty estimation and then iteratively generates a set of non-dominated solutions by destructing and reconstructing the current solution. To evaluate the effectiveness of OptLLM, we conduct extensive experiments on various types of tasks, including text classification, question answering, sentiment analysis, reasoning, and log parsing. Our experimental results demonstrate that OptLLM substantially reduces costs by 2.40% to 49.18% while achieving the same accuracy as the best LLM. Compared to other multi-objective optimization algorithms, OptLLM improves accuracy by 2.94% to 69.05% at the same cost or saves costs by 8.79% and 95.87% while maintaining the highest attainable accuracy.
Read more5/27/2024

0
RouteLLM: Learning to Route LLMs with Preference Data
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M Waleed Kadous, Ion Stoica
Large language models (LLMs) exhibit impressive capabilities across a wide range of tasks, yet the choice of which model to use often involves a trade-off between performance and cost. More powerful models, though effective, come with higher expenses, while less capable models are more cost-effective. To address this dilemma, we propose several efficient router models that dynamically select between a stronger and a weaker LLM during inference, aiming to optimize the balance between cost and response quality. We develop a training framework for these routers leveraging human preference data and data augmentation techniques to enhance performance. Our evaluation on widely-recognized benchmarks shows that our approach significantly reduces costs-by over 2 times in certain cases-without compromising the quality of responses. Interestingly, our router models also demonstrate significant transfer learning capabilities, maintaining their performance even when the strong and weak models are changed at test time. This highlights the potential of these routers to provide a cost-effective yet high-performance solution for deploying LLMs.
Read more7/23/2024

0
METAL: Towards Multilingual Meta-Evaluation
Rishav Hada, Varun Gumma, Mohamed Ahmed, Kalika Bali, Sunayana Sitaram
With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
Read more4/3/2024