MetaTool: Facilitating Large Language Models to Master Tools with Meta-task Augmentation

0

Sign in to get full access
Overview
• This paper introduces a new technique called "MetaTool" that helps large language models (LLMs) learn to use a variety of tools more effectively.
• The key idea is to augment the training data with "meta-tasks" that focus on tool usage, in addition to the standard language modeling tasks. This helps the LLM develop a better understanding of how to leverage different tools to accomplish various goals.
Plain English Explanation
• Large language models (LLMs) like GPT-3 are incredibly powerful, but they can struggle to use external tools and applications in a seamless way. The MetaTool technique aims to address this by training the LLM on additional "meta-tasks" that focus on using tools.
• For example, the model might be trained not just to generate text, but also to use a calculator, a search engine, a note-taking app, and other tools to accomplish specific tasks. This helps the LLM develop a better understanding of how to leverage different tools and integrate them into its workflow.
• The authors believe this approach can significantly improve the ability of LLMs to master a wide range of tools and applications, making them more versatile and useful in real-world scenarios. By augmenting the training data with these meta-tasks, the model can learn to seamlessly integrate tool usage into its natural language processing capabilities.
Technical Explanation
• The core idea of MetaTool is to augment the standard language modeling training tasks with "meta-tasks" that focus on tool usage. These meta-tasks involve prompting the LLM to use specific tools (e.g., a calculator, a search engine, a note-taking app) to accomplish various goals.
• For example, the LLM might be asked to use a calculator to perform arithmetic operations, or to use a search engine to find information on a given topic. By training the model on these types of tool-centric tasks, the authors hypothesize that the LLM will develop a better understanding of how to leverage different tools and integrate them into its natural language processing capabilities.
• The authors conduct experiments to evaluate the effectiveness of the MetaTool approach, comparing the performance of LLMs trained with and without the meta-task augmentation on a variety of tool-related tasks. Their results suggest that the MetaTool-trained models significantly outperform their counterparts in terms of tool mastery and task completion.
Critical Analysis
• The paper provides a compelling approach to improving the tool-using abilities of large language models, but there are some potential limitations and areas for further research.
• One concern is the scalability of the meta-task augmentation approach – as the number of tools and applications grows, the training data and computational requirements may become increasingly burdensome. The authors acknowledge this challenge and suggest the need for more efficient meta-task generation and integration techniques.
• Additionally, the paper focuses primarily on a limited set of tool-related tasks, and it's unclear how well the MetaTool approach would generalize to a much broader range of tools and use cases. Further research is needed to explore the model's performance across a wider spectrum of tool-centric applications.
• Another potential issue is the potential for the meta-task augmentation to introduce biases or distortions into the LLM's language modeling capabilities. The authors should investigate the impact of the meta-tasks on the model's general text generation and understanding abilities.
Conclusion
• The MetaTool approach proposed in this paper represents a promising step towards empowering large language models to more seamlessly integrate and leverage a variety of tools and applications. By augmenting the training data with meta-tasks focused on tool usage, the authors demonstrate significant improvements in the LLM's ability to master and utilize different tools.
• This research has important implications for the development of more versatile and capable AI systems that can effectively combine their natural language processing capabilities with a wide range of task-specific tools. As the field of AI continues to evolve, techniques like MetaTool may play a crucial role in unlocking the full potential of large language models and pushing the boundaries of what these systems can accomplish.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MetaTool: Facilitating Large Language Models to Master Tools with Meta-task Augmentation
Xiaohan Wang, Dian Li, Yilin Zhao, Sinbadliu, Hui Wang
Utilizing complex tools with Large Language Models (LLMs) is a critical component for grounding AI agents in various real-world scenarios. The core challenge of manipulating tools lies in understanding their usage and functionality. The prevailing approach involves few-shot prompting with demonstrations or fine-tuning on expert trajectories. However, for complex tools and tasks, mere in-context demonstrations may fail to cover sufficient knowledge. Training-based methods are also constrained by the high cost of dataset construction and limited generalizability. In this paper, we introduce a new tool learning methodology (MetaTool) that is generalizable for mastering any reusable toolset. Our approach includes a self-supervised data augmentation technique that enables LLMs to gain a comprehensive understanding of various tools, thereby improving their ability to complete tasks effectively. We develop a series of meta-tasks that involve predicting masked factors of tool execution. These self-supervised tasks enable the automatic generation of high-quality QA data concerning tool comprehension. By incorporating meta-task data into the instruction tuning process, the proposed MetaTool model achieves significant superiority to open-source models and is comparable to GPT-4/GPT-3.5 on multiple tool-oriented tasks.
Read more7/19/2024

0
Chain of Tools: Large Language Model is an Automatic Multi-tool Learner
Zhengliang Shi, Shen Gao, Xiuyi Chen, Yue Feng, Lingyong Yan, Haibo Shi, Dawei Yin, Zhumin Chen, Suzan Verberne, Zhaochun Ren
Augmenting large language models (LLMs) with external tools has emerged as a promising approach to extend their utility, empowering them to solve practical tasks. Existing work typically empowers LLMs as tool users with a manually designed workflow, where the LLM plans a series of tools in a step-by-step manner, and sequentially executes each tool to obtain intermediate results until deriving the final answer. However, they suffer from two challenges in realistic scenarios: (1) The handcrafted control flow is often ad-hoc and constraints the LLM to local planning; (2) The LLM is instructed to use only manually demonstrated tools or well-trained Python functions, which limits its generalization to new tools. In this work, we first propose Automatic Tool Chain (ATC), a framework that enables the LLM to act as a multi-tool user, which directly utilizes a chain of tools through programming. To scale up the scope of the tools, we next propose a black-box probing method. This further empowers the LLM as a tool learner that can actively discover and document tool usages, teaching themselves to properly master new tools. For a comprehensive evaluation, we build a challenging benchmark named ToolFlow, which diverges from previous benchmarks by its long-term planning scenarios and complex toolset. Experiments on both existing datasets and ToolFlow illustrate the superiority of our framework. Analysis on different settings also validates the effectiveness and the utility of our black-box probing algorithm.
Read more5/28/2024

0
Tool Learning with Large Language Models: A Survey
Changle Qu, Sunhao Dai, Xiaochi Wei, Hengyi Cai, Shuaiqiang Wang, Dawei Yin, Jun Xu, Ji-Rong Wen
Recently, tool learning with large language models (LLMs) has emerged as a promising paradigm for augmenting the capabilities of LLMs to tackle highly complex problems. Despite growing attention and rapid advancements in this field, the existing literature remains fragmented and lacks systematic organization, posing barriers to entry for newcomers. This gap motivates us to conduct a comprehensive survey of existing works on tool learning with LLMs. In this survey, we focus on reviewing existing literature from the two primary aspects (1) why tool learning is beneficial and (2) how tool learning is implemented, enabling a comprehensive understanding of tool learning with LLMs. We first explore the why by reviewing both the benefits of tool integration and the inherent benefits of the tool learning paradigm from six specific aspects. In terms of how, we systematically review the literature according to a taxonomy of four key stages in the tool learning workflow: task planning, tool selection, tool calling, and response generation. Additionally, we provide a detailed summary of existing benchmarks and evaluation methods, categorizing them according to their relevance to different stages. Finally, we discuss current challenges and outline potential future directions, aiming to inspire both researchers and industrial developers to further explore this emerging and promising area. We also maintain a GitHub repository to continually keep track of the relevant papers and resources in this rising area at url{https://github.com/quchangle1/LLM-Tool-Survey}.
Read more5/31/2024
0
Empowering Large Language Models for Textual Data Augmentation
Yichuan Li, Kaize Ding, Jianling Wang, Kyumin Lee
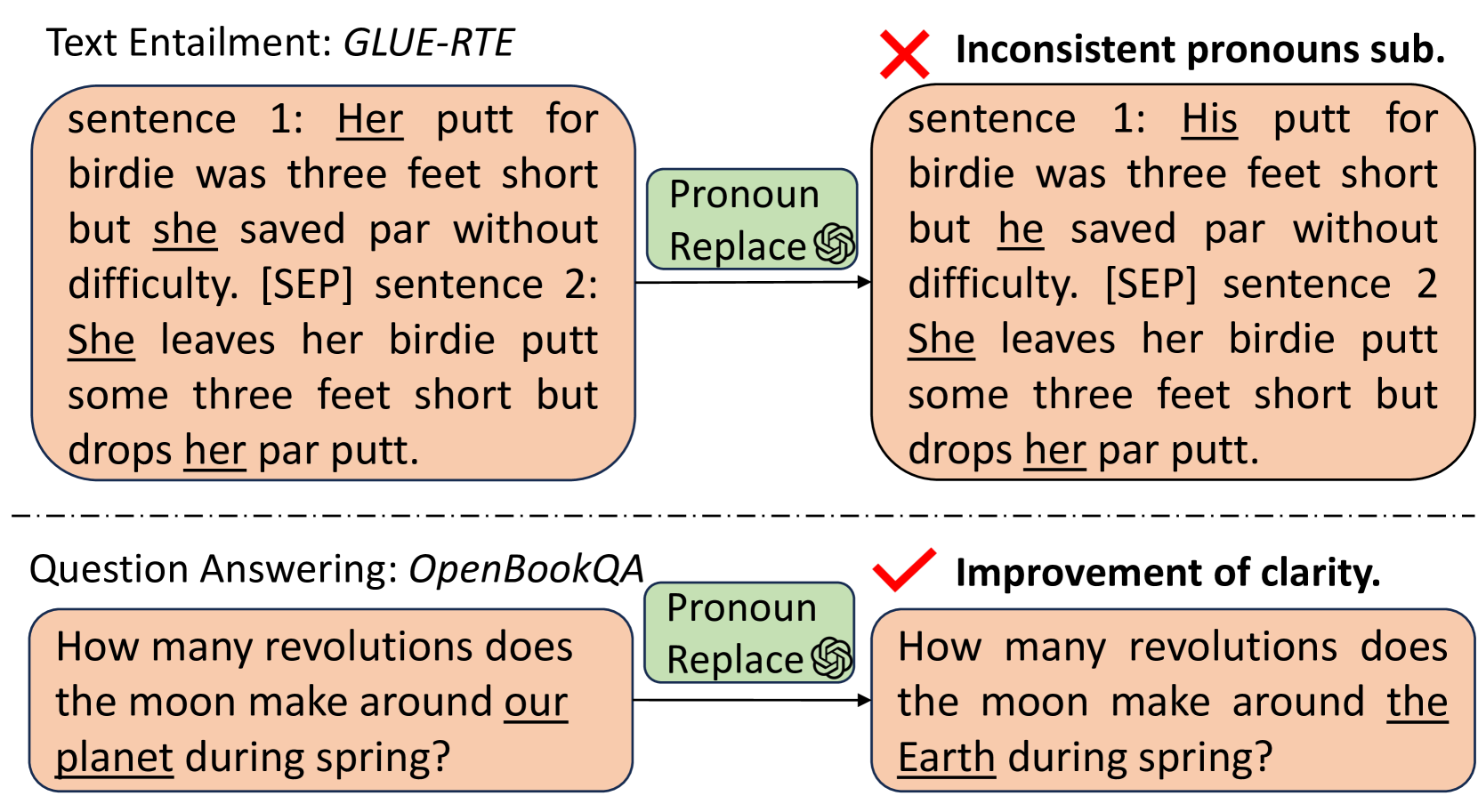
With the capabilities of understanding and executing natural language instructions, Large language models (LLMs) can potentially act as a powerful tool for textual data augmentation. However, the quality of augmented data depends heavily on the augmentation instructions provided, and the effectiveness can fluctuate across different downstream tasks. While manually crafting and selecting instructions can offer some improvement, this approach faces scalability and consistency issues in practice due to the diversity of downstream tasks. In this work, we address these limitations by proposing a new solution, which can automatically generate a large pool of augmentation instructions and select the most suitable task-informed instructions, thereby empowering LLMs to create high-quality augmented data for different downstream tasks. Empirically, the proposed approach consistently generates augmented data with better quality compared to non-LLM and LLM-based data augmentation methods, leading to the best performance on 26 few-shot learning tasks sourced from a wide range of application domains.
Read more4/30/2024