A Method on Searching Better Activation Functions
2405.12954
0
0
🔄
Abstract
The success of artificial neural networks (ANNs) hinges greatly on the judicious selection of an activation function, introducing non-linearity into network and enabling them to model sophisticated relationships in data. However, the search of activation functions has largely relied on empirical knowledge in the past, lacking theoretical guidance, which has hindered the identification of more effective activation functions. In this work, we offer a proper solution to such issue. Firstly, we theoretically demonstrate the existence of the worst activation function with boundary conditions (WAFBC) from the perspective of information entropy. Furthermore, inspired by the Taylor expansion form of information entropy functional, we propose the Entropy-based Activation Function Optimization (EAFO) methodology. EAFO methodology presents a novel perspective for designing static activation functions in deep neural networks and the potential of dynamically optimizing activation during iterative training. Utilizing EAFO methodology, we derive a novel activation function from ReLU, known as Correction Regularized ReLU (CRReLU). Experiments conducted with vision transformer and its variants on CIFAR-10, CIFAR-100 and ImageNet-1K datasets demonstrate the superiority of CRReLU over existing corrections of ReLU. Extensive empirical studies on task of large language model (LLM) fine-tuning, CRReLU exhibits superior performance compared to GELU, suggesting its broader potential for practical applications.
Create account to get full access
Overview
- This paper explores the importance of activation functions in artificial neural networks (ANNs) and proposes a novel approach for designing and optimizing them.
- The authors demonstrate the theoretical existence of the "worst activation function with boundary conditions" (WAFBC) from an information entropy perspective.
- Inspired by the Taylor expansion form of information entropy, the authors introduce the Entropy-based Activation Function Optimization (EAFO) methodology.
- Using EAFO, the authors derive a new activation function called Correction Regularized ReLU (CRReLU), which outperforms existing ReLU variants in various computer vision and language model tasks.
Plain English Explanation
Artificial neural networks (ANNs) are a type of machine learning model inspired by the human brain. They are incredibly powerful at modeling complex relationships in data, but their success often hinges on the choice of an "activation function." An activation function introduces non-linearity into the network, allowing it to learn sophisticated patterns.
In the past, the search for effective activation functions has been largely based on empirical knowledge, without much theoretical guidance. This paper offers a solution to this problem. The authors first demonstrate the theoretical existence of the "worst activation function with boundary conditions" (WAFBC) from an information entropy perspective. This provides a baseline for understanding what makes a good activation function.
Inspired by the mathematical concept of information entropy, the authors then propose the Entropy-based Activation Function Optimization (EAFO) methodology. This offers a novel way to design and dynamically optimize activation functions during the training of deep neural networks.
Using the EAFO approach, the authors derive a new activation function called Correction Regularized ReLU (CRReLU), which is an improvement on the widely used ReLU (Rectified Linear Unit) function. Experiments show that CRReLU outperforms existing ReLU variants in various computer vision and language model tasks, suggesting its potential for practical applications.
Technical Explanation
The authors first theoretically demonstrate the existence of the "worst activation function with boundary conditions" (WAFBC) from the perspective of information entropy. This provides a fundamental understanding of what makes a good activation function.
Inspired by the Taylor expansion form of information entropy, the authors then propose the Entropy-based Activation Function Optimization (EAFO) methodology. EAFO offers a novel approach for designing static activation functions in deep neural networks and the potential for dynamically optimizing activation functions during iterative training.
Using the EAFO methodology, the authors derive a new activation function called Correction Regularized ReLU (CRReLU), which is an extension of the popular ReLU (Rectified Linear Unit) function. Experiments conducted on computer vision tasks, such as image classification on CIFAR-10, CIFAR-100, and ImageNet-1K datasets, as well as language model fine-tuning tasks, demonstrate the superiority of CRReLU over existing ReLU variants.
Critical Analysis
The paper provides a strong theoretical foundation for understanding activation functions and introduces a novel methodology (EAFO) for designing and optimizing them. The authors' derivation of the CRReLU activation function and its empirical evaluation across various tasks suggest its potential benefits over existing solutions.
However, the paper does not address the computational complexity or training time implications of the EAFO methodology and the CRReLU function. Additionally, the authors do not discuss the scalability of their approach to larger-scale models or its applicability to different domains beyond computer vision and language modeling.
Further research could explore the generalizability of the EAFO approach, investigate its impact on model interpretability and robustness, and compare its performance to other state-of-the-art activation function search methods. Empirical studies on a wider range of tasks and datasets would also help validate the broader applicability of the CRReLU function.
Conclusion
This paper offers a novel theoretical framework and methodology for designing and optimizing activation functions in artificial neural networks. The authors' derivation of the CRReLU activation function, which outperforms existing ReLU variants, suggests that their Entropy-based Activation Function Optimization (EAFO) approach can lead to the development of more effective activation functions. The potential benefits of CRReLU and the EAFO methodology could have far-reaching implications for improving the performance and capabilities of deep learning models across various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
Nonlinearity Enhanced Adaptive Activation Function
David Yevick
0
0
A simply implemented activation function with even cubic nonlinearity is introduced that increases the accuracy of neural networks without substantial additional computational resources. This is partially enabled through an apparent tradeoff between convergence and accuracy. The activation function generalizes the standard RELU function by introducing additional degrees of freedom through optimizable parameters that enable the degree of nonlinearity to be adjusted. The associated accuracy enhancement is quantified in the context of the MNIST digit data set through a comparison with standard techniques.
4/1/2024
🚀
Optimizing cnn-Bigru performance: Mish activation and comparative analysis with Relu
Asmaa Benchama, Khalid Zebbara
0
0
Deep learning is currently extensively employed across a range of research domains. The continuous advancements in deep learning techniques contribute to solving intricate challenges. Activation functions (AF) are fundamental components within neural networks, enabling them to capture complex patterns and relationships in the data. By introducing non-linearities, AF empowers neural networks to model and adapt to the diverse and nuanced nature of real-world data, enhancing their ability to make accurate predictions across various tasks. In the context of intrusion detection, the Mish, a recent AF, was implemented in the CNN-BiGRU model, using three datasets: ASNM-TUN, ASNM-CDX, and HOGZILLA. The comparison with Rectified Linear Unit (ReLU), a widely used AF, revealed that Mish outperforms ReLU, showcasing superior performance across the evaluated datasets. This study illuminates the effectiveness of AF in elevating the performance of intrusion detection systems.
6/3/2024
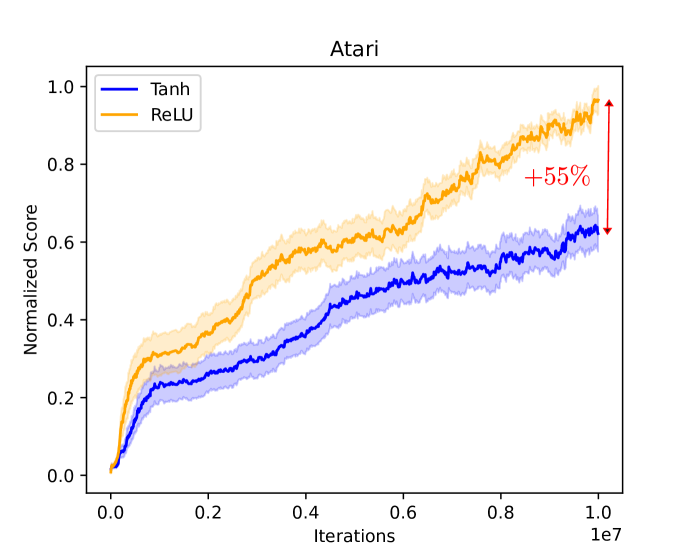
Latent Assistance Networks: Rediscovering Hyperbolic Tangents in RL
Jacob E. Kooi, Mark Hoogendoorn, Vincent Franc{c}ois-Lavet
0
0
Activation functions are one of the key components of a neural network. The most commonly used activation functions can be classed into the category of continuously differentiable (e.g. tanh) and linear-unit functions (e.g. ReLU), both having their own strengths and drawbacks with respect to downstream performance and representation capacity through learning (e.g. measured by the number of dead neurons and the effective rank). In reinforcement learning, the performance of continuously differentiable activations often falls short as compared to linear-unit functions. From the perspective of the activations in the last hidden layer, this paper provides insights regarding this sub-optimality and explores how activation functions influence the occurrence of dead neurons and the magnitude of the effective rank. Additionally, a novel neural architecture is proposed that leverages the product of independent activation values. In the Atari domain, we show faster learning, a reduction in dead neurons and increased effective rank.
6/14/2024
🌀
A Significantly Better Class of Activation Functions Than ReLU Like Activation Functions
Mathew Mithra Noel, Yug Oswal
0
0
This paper introduces a significantly better class of activation functions than the almost universally used ReLU like and Sigmoidal class of activation functions. Two new activation functions referred to as the Cone and Parabolic-Cone that differ drastically from popular activation functions and significantly outperform these on the CIFAR-10 and Imagenette benchmmarks are proposed. The cone activation functions are positive only on a finite interval and are strictly negative except at the end-points of the interval, where they become zero. Thus the set of inputs that produce a positive output for a neuron with cone activation functions is a hyperstrip and not a half-space as is the usual case. Since a hyper strip is the region between two parallel hyper-planes, it allows neurons to more finely divide the input feature space into positive and negative classes than with infinitely wide half-spaces. In particular the XOR function can be learn by a single neuron with cone-like activation functions. Both the cone and parabolic-cone activation functions are shown to achieve higher accuracies with significantly fewer neurons on benchmarks. The results presented in this paper indicate that many nonlinear real-world datasets may be separated with fewer hyperstrips than half-spaces. The Cone and Parabolic-Cone activation functions have larger derivatives than ReLU and are shown to significantly speedup training.
5/8/2024