A Significantly Better Class of Activation Functions Than ReLU Like Activation Functions
2405.04459
0
0
🌀
Abstract
This paper introduces a significantly better class of activation functions than the almost universally used ReLU like and Sigmoidal class of activation functions. Two new activation functions referred to as the Cone and Parabolic-Cone that differ drastically from popular activation functions and significantly outperform these on the CIFAR-10 and Imagenette benchmmarks are proposed. The cone activation functions are positive only on a finite interval and are strictly negative except at the end-points of the interval, where they become zero. Thus the set of inputs that produce a positive output for a neuron with cone activation functions is a hyperstrip and not a half-space as is the usual case. Since a hyper strip is the region between two parallel hyper-planes, it allows neurons to more finely divide the input feature space into positive and negative classes than with infinitely wide half-spaces. In particular the XOR function can be learn by a single neuron with cone-like activation functions. Both the cone and parabolic-cone activation functions are shown to achieve higher accuracies with significantly fewer neurons on benchmarks. The results presented in this paper indicate that many nonlinear real-world datasets may be separated with fewer hyperstrips than half-spaces. The Cone and Parabolic-Cone activation functions have larger derivatives than ReLU and are shown to significantly speedup training.
Create account to get full access
Overview
- This paper introduces two new activation functions - the Cone and Parabolic-Cone - that outperform the commonly used ReLU and sigmoid-like activation functions on computer vision benchmarks.
- The key idea is that these new activation functions have a finite positive range, unlike ReLU which is positive for all positive inputs. This allows neurons to more finely divide the input feature space into positive and negative classes.
- The authors show that these new activation functions can learn the XOR function with a single neuron, and achieve higher accuracies with fewer neurons on CIFAR-10 and Imagenette.
- They also demonstrate that the new activation functions have larger derivatives, leading to faster training compared to ReLU.
Plain English Explanation
The paper presents a significantly better class of activation functions than the commonly used ReLU and sigmoid-like functions. Activation functions determine how a neural network transforms its inputs into outputs, and the choice of activation function can have a big impact on the network's performance.
The key innovation is the Cone and Parabolic-Cone activation functions, which differ quite a bit from popular options like ReLU. Unlike ReLU, which is positive for all positive inputs, these new functions are only positive on a finite interval. This means the set of inputs that produce a positive output for a neuron is a "hyperstrip" (the region between two parallel planes) rather than the usual "halfspace" (one side of a plane).
This hyperstrip structure allows neurons to more finely divide up the input feature space into positive and negative classes. The authors show that this enables a single neuron with a Cone-like activation to learn the XOR function, which is notoriously difficult for traditional neural networks. They also demonstrate that the new activations achieve higher accuracies with fewer neurons on computer vision benchmarks like CIFAR-10 and Imagenette.
Interestingly, the new activation functions also have larger derivatives than ReLU, which means they can speed up the training process. Overall, this research suggests that many real-world datasets may be more efficiently separated using hyperstrips instead of halfspaces, pointing to a promising direction for improving the efficiency and performance of neural networks.
Technical Explanation
The paper introduces two new activation functions, the Cone and Parabolic-Cone, which differ significantly from the widely used ReLU and sigmoid-like activations.
The key distinction is that the new activation functions are only positive on a finite interval, and are strictly negative except at the endpoints where they become zero. This means the set of inputs that produce a positive output for a neuron with these activations is a "hyperstrip" (the region between two parallel hyperplanes) rather than the usual "halfspace" (one side of a hyperplane).
The authors show that this hyperstrip structure allows neurons to more finely divide the input feature space into positive and negative classes. In particular, they demonstrate that a single neuron with a Cone-like activation can learn the XOR function, which is known to be difficult for traditional neural networks.
Experiments on the CIFAR-10 and Imagenette computer vision benchmarks reveal that the Cone and Parabolic-Cone activations achieve higher accuracies with significantly fewer neurons compared to ReLU and sigmoid-like functions. The authors attribute this to the ability of the new activations to more efficiently separate complex, nonlinear datasets using hyperstrips instead of halfspaces.
Interestingly, the Cone and Parabolic-Cone activations also have larger derivatives than ReLU, which the authors show leads to faster training convergence. This is an important practical benefit, as training efficiency is a key concern in many real-world applications of neural networks.
Overall, this work introduces a novel class of activation functions that offer compelling advantages over existing options, both in terms of representational power and training efficiency. The results suggest that many nonlinear datasets may be more effectively learned using hyperstrips rather than halfspaces, pointing to an interesting direction for future research and development in neural network architectures.
Critical Analysis
The paper presents a compelling case for the Cone and Parabolic-Cone activation functions as a significant improvement over commonly used ReLU and sigmoid-like activations. The authors provide strong empirical evidence of the new activations' superior performance on computer vision benchmarks, and offer a clear theoretical explanation for their advantages.
One potential limitation is that the paper only evaluates the new activations on image classification tasks. It would be interesting to see how they perform on a wider range of problem domains, such as natural language processing or graph-structured data. Additionally, the authors do not explore the robustness of the new activations to adversarial attacks or other forms of distribution shift, which is an important consideration for real-world deployment.
Further research could also investigate the underlying reasons for the new activations' ability to learn the XOR function with a single neuron. Understanding the representational capacity and limitations of the Cone and Parabolic-Cone functions could yield valuable insights into the inductive biases that lead to their performance advantages.
Overall, this paper presents a promising new direction for activation function design, with the potential to improve the efficiency and effectiveness of neural networks across a variety of applications. Readers are encouraged to think critically about the findings and consider how the new activations might be leveraged or extended in their own work.
Conclusion
This paper introduces two novel activation functions, the Cone and Parabolic-Cone, that significantly outperform the commonly used ReLU and sigmoid-like activations on computer vision benchmarks. The key innovation is the finite positive range of these new activations, which allows neurons to more finely divide the input feature space into positive and negative classes using "hyperstrips" instead of the usual "halfspaces".
The authors demonstrate that this hyperstrip structure enables a single neuron with a Cone-like activation to learn the XOR function, and leads to higher accuracies with fewer neurons on CIFAR-10 and Imagenette. Additionally, the new activations have larger derivatives than ReLU, resulting in faster training convergence.
Overall, this work suggests that many nonlinear real-world datasets may be more efficiently separated using hyperstrips rather than halfspaces, pointing to a promising direction for improving the performance and efficiency of neural networks. The findings presented in this paper are an important contribution to the ongoing research on activation function design and its impact on neural network capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
Nonlinearity Enhanced Adaptive Activation Function
David Yevick
0
0
A simply implemented activation function with even cubic nonlinearity is introduced that increases the accuracy of neural networks without substantial additional computational resources. This is partially enabled through an apparent tradeoff between convergence and accuracy. The activation function generalizes the standard RELU function by introducing additional degrees of freedom through optimizable parameters that enable the degree of nonlinearity to be adjusted. The associated accuracy enhancement is quantified in the context of the MNIST digit data set through a comparison with standard techniques.
4/1/2024
🔄
A Method on Searching Better Activation Functions
Haoyuan Sun, Zihao Wu, Bo Xia, Pu Chang, Zibin Dong, Yifu Yuan, Yongzhe Chang, Xueqian Wang
0
0
The success of artificial neural networks (ANNs) hinges greatly on the judicious selection of an activation function, introducing non-linearity into network and enabling them to model sophisticated relationships in data. However, the search of activation functions has largely relied on empirical knowledge in the past, lacking theoretical guidance, which has hindered the identification of more effective activation functions. In this work, we offer a proper solution to such issue. Firstly, we theoretically demonstrate the existence of the worst activation function with boundary conditions (WAFBC) from the perspective of information entropy. Furthermore, inspired by the Taylor expansion form of information entropy functional, we propose the Entropy-based Activation Function Optimization (EAFO) methodology. EAFO methodology presents a novel perspective for designing static activation functions in deep neural networks and the potential of dynamically optimizing activation during iterative training. Utilizing EAFO methodology, we derive a novel activation function from ReLU, known as Correction Regularized ReLU (CRReLU). Experiments conducted with vision transformer and its variants on CIFAR-10, CIFAR-100 and ImageNet-1K datasets demonstrate the superiority of CRReLU over existing corrections of ReLU. Extensive empirical studies on task of large language model (LLM) fine-tuning, CRReLU exhibits superior performance compared to GELU, suggesting its broader potential for practical applications.
5/24/2024
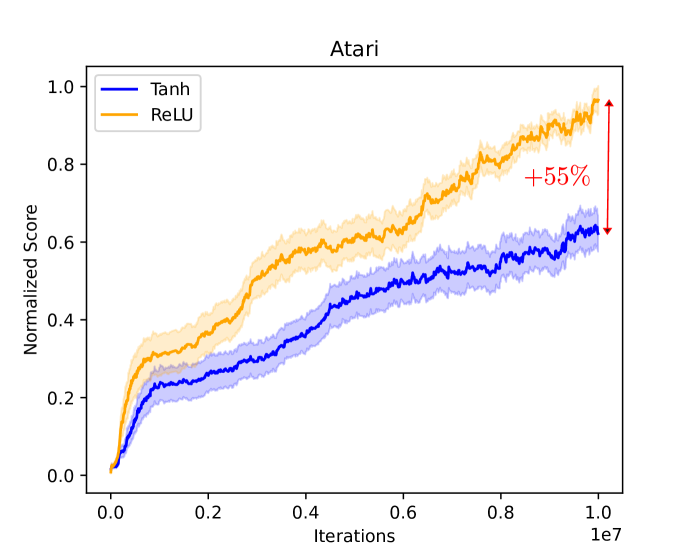
Latent Assistance Networks: Rediscovering Hyperbolic Tangents in RL
Jacob E. Kooi, Mark Hoogendoorn, Vincent Franc{c}ois-Lavet
0
0
Activation functions are one of the key components of a neural network. The most commonly used activation functions can be classed into the category of continuously differentiable (e.g. tanh) and linear-unit functions (e.g. ReLU), both having their own strengths and drawbacks with respect to downstream performance and representation capacity through learning (e.g. measured by the number of dead neurons and the effective rank). In reinforcement learning, the performance of continuously differentiable activations often falls short as compared to linear-unit functions. From the perspective of the activations in the last hidden layer, this paper provides insights regarding this sub-optimality and explores how activation functions influence the occurrence of dead neurons and the magnitude of the effective rank. Additionally, a novel neural architecture is proposed that leverages the product of independent activation values. In the Atari domain, we show faster learning, a reduction in dead neurons and increased effective rank.
6/14/2024
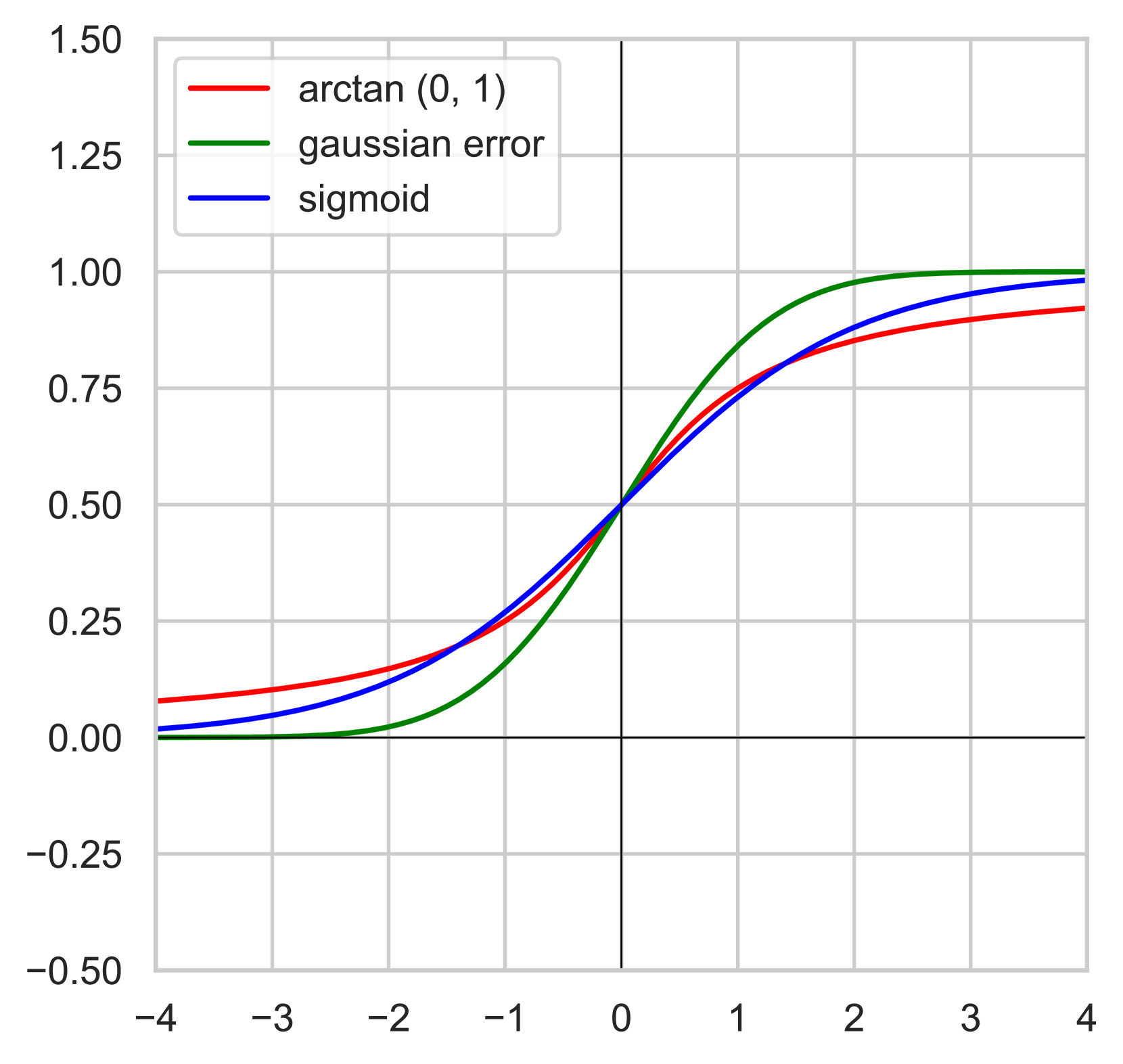
Expanded Gating Ranges Improve Activation Functions
Allen Hao Huang
0
0
Activation functions are core components of all deep learning architectures. Currently, the most popular activation functions are smooth ReLU variants like GELU and SiLU. These are self-gated activation functions where the range of the gating function is between zero and one. In this paper, we explore the viability of using arctan as a gating mechanism. A self-gated activation function that uses arctan as its gating function has a monotonically increasing first derivative. To make this activation function competitive, it is necessary to introduce a trainable parameter for every MLP block to expand the range of the gating function beyond zero and one. We find that this technique also improves existing self-gated activation functions. We conduct an empirical evaluation of Expanded ArcTan Linear Unit (xATLU), Expanded GELU (xGELU), and Expanded SiLU (xSiLU) and show that they outperform existing activation functions within a transformer architecture. Additionally, expanded gating ranges show promising results in improving first-order Gated Linear Units (GLU).
6/3/2024