Causal Discovery with Fewer Conditional Independence Tests
2406.01823
0
0

Abstract
Many questions in science center around the fundamental problem of understanding causal relationships. However, most constraint-based causal discovery algorithms, including the well-celebrated PC algorithm, often incur an exponential number of conditional independence (CI) tests, posing limitations in various applications. Addressing this, our work focuses on characterizing what can be learned about the underlying causal graph with a reduced number of CI tests. We show that it is possible to a learn a coarser representation of the hidden causal graph with a polynomial number of tests. This coarser representation, named Causal Consistent Partition Graph (CCPG), comprises of a partition of the vertices and a directed graph defined over its components. CCPG satisfies consistency of orientations and additional constraints which favor finer partitions. Furthermore, it reduces to the underlying causal graph when the causal graph is identifiable. As a consequence, our results offer the first efficient algorithm for recovering the true causal graph with a polynomial number of tests, in special cases where the causal graph is fully identifiable through observational data and potentially additional interventions.
Create account to get full access
Overview
- This paper proposes a new causal discovery algorithm that can identify causal relationships between variables using fewer independence tests compared to traditional methods.
- The key insight is to use "proxy variables" that can help infer causal relationships without directly testing the independence of all variable pairs.
- The algorithm is shown to be more sample-efficient and scalable than existing causal discovery techniques, making it suitable for real-world applications with limited data.
Plain English Explanation
Causal discovery is the process of understanding how different factors or variables are connected and influence each other. This paper introduces a new approach that can figure out these causal relationships using fewer statistical tests compared to previous methods.
The core idea is to identify "proxy variables" - variables that can serve as stand-ins or representatives for other variables. By leveraging these proxies, the algorithm can infer causal connections without having to directly check the independence of every possible pair of variables. This makes the process more efficient, especially when dealing with large datasets or complex relationships.
For example, imagine you want to understand how factors like diet, exercise, and sleep affect a person's health. Rather than testing the independence of all these variables directly, the new algorithm might find that a person's fitness tracker data could serve as a good proxy for their exercise habits. This proxy information can then be used to deduce how exercise impacts health, without needing to measure exercise levels directly.
By reducing the number of statistical tests required, this approach can discover causal models more quickly and with less data, making it useful for real-world applications where data may be limited. The authors demonstrate the benefits of their technique through experiments and comparisons to other causal discovery methods.
Technical Explanation
The key innovation in this paper is the use of proxy variables to streamline the causal discovery process. Traditional causal discovery algorithms, such as constraint-based or score-based methods, rely on exhaustively testing the independence of all variable pairs. This can be computationally expensive, especially for high-dimensional datasets.
The proposed algorithm, called PCDC (Proxy-based Causal Discovery via Conditional Independence), leverages proxy variables to reduce the number of independence tests required. The core steps are:
- Identify a set of proxy variables that can serve as representatives for the other variables in the system.
- Use conditional independence tests to determine which variables are directly caused by the proxies, and which variables are independent of the proxies given other variables.
- Iteratively refine the set of proxy variables and repeat the conditional independence tests to build a more complete causal model.
By focusing on conditional independence rather than pairwise independence, PCDC can discover causal relationships with fewer overall tests. The authors prove theoretical guarantees about the accuracy and efficiency of this approach compared to traditional methods.
The paper also introduces an extension called PCDC+, which further improves sample efficiency by adaptively selecting the most informative conditional independence tests to perform. This makes PCDC+ particularly well-suited for real-world applications with limited data, as demonstrated through empirical evaluations on both synthetic and real-world datasets.
Critical Analysis
The PCDC algorithm presented in this paper offers an innovative approach to causal discovery that can be more sample-efficient and scalable than existing methods. The key strength is the use of proxy variables to reduce the number of independence tests required, which is a clever insight.
However, the paper does not address several important practical considerations. For example, the authors assume the availability of an "oracle" that can perfectly identify the proxy variables, which may not be realistic in many real-world scenarios. Additionally, the conditional independence tests used by PCDC rely on strong parametric assumptions that may not hold in complex, non-linear systems.
Further research is needed to explore more robust and data-driven techniques for proxy variable selection, as well as the extension to non-linear causal discovery. Additionally, the paper focuses on the theoretical properties of PCDC but would benefit from a more thorough empirical evaluation on a wider range of real-world datasets to better understand its practical limitations and strengths.
Overall, the PCDC algorithm represents an interesting and promising direction for improving the efficiency of causal discovery. However, addressing the limitations mentioned above could further enhance its applicability and impact in the field of causal inference.
Conclusion
This paper introduces a new causal discovery algorithm called PCDC that can identify causal relationships using fewer independence tests compared to traditional methods. The key innovation is the use of proxy variables to streamline the causal discovery process, making it more sample-efficient and scalable.
The authors demonstrate the theoretical advantages of PCDC and an improved version called PCDC+, which further enhances sample efficiency. While the paper offers an interesting and promising approach, additional research is needed to address practical considerations, such as more robust proxy variable selection and extensions to non-linear causal models.
Overall, the PCDC algorithm represents an important step forward in the field of causal discovery, with the potential to enable more accurate and efficient causal modeling in a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
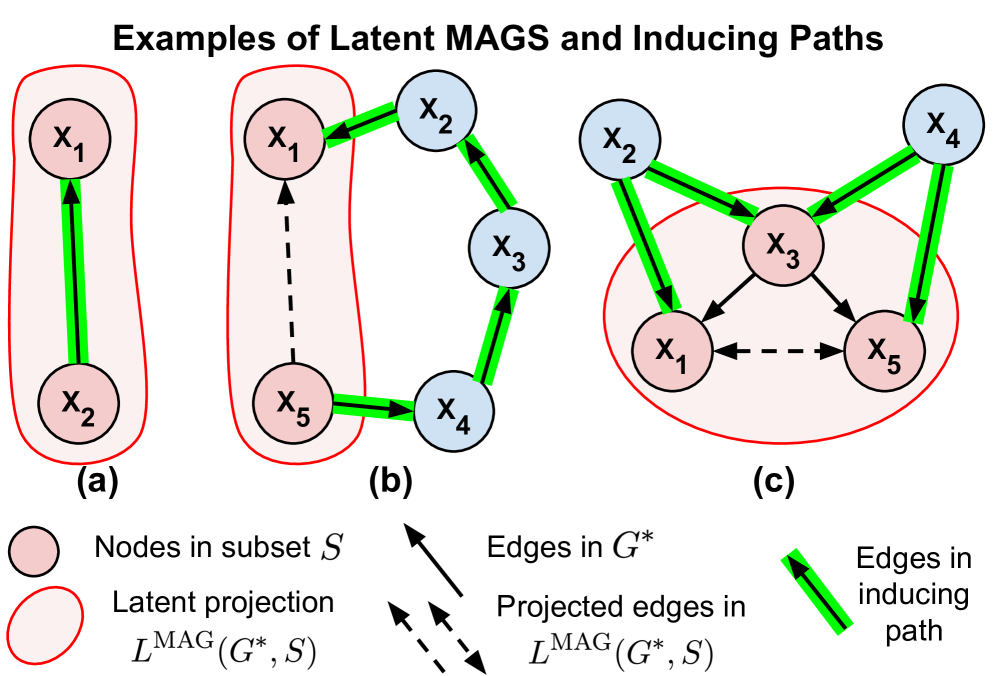
Causal Discovery over High-Dimensional Structured Hypothesis Spaces with Causal Graph Partitioning
Ashka Shah, Adela DePavia, Nathaniel Hudson, Ian Foster, Rick Stevens
0
0
The aim in many sciences is to understand the mechanisms that underlie the observed distribution of variables, starting from a set of initial hypotheses. Causal discovery allows us to infer mechanisms as sets of cause and effect relationships in a generalized way -- without necessarily tailoring to a specific domain. Causal discovery algorithms search over a structured hypothesis space, defined by the set of directed acyclic graphs, to find the graph that best explains the data. For high-dimensional problems, however, this search becomes intractable and scalable algorithms for causal discovery are needed to bridge the gap. In this paper, we define a novel causal graph partition that allows for divide-and-conquer causal discovery with theoretical guarantees. We leverage the idea of a superstructure -- a set of learned or existing candidate hypotheses -- to partition the search space. We prove under certain assumptions that learning with a causal graph partition always yields the Markov Equivalence Class of the true causal graph. We show our algorithm achieves comparable accuracy and a faster time to solution for biologically-tuned synthetic networks and networks up to ${10^4}$ variables. This makes our method applicable to gene regulatory network inference and other domains with high-dimensional structured hypothesis spaces.
6/11/2024
Large Language Models for Constrained-Based Causal Discovery
Kai-Hendrik Cohrs, Gherardo Varando, Emiliano Diaz, Vasileios Sitokonstantinou, Gustau Camps-Valls
0
0
Causality is essential for understanding complex systems, such as the economy, the brain, and the climate. Constructing causal graphs often relies on either data-driven or expert-driven approaches, both fraught with challenges. The former methods, like the celebrated PC algorithm, face issues with data requirements and assumptions of causal sufficiency, while the latter demand substantial time and domain knowledge. This work explores the capabilities of Large Language Models (LLMs) as an alternative to domain experts for causal graph generation. We frame conditional independence queries as prompts to LLMs and employ the PC algorithm with the answers. The performance of the LLM-based conditional independence oracle on systems with known causal graphs shows a high degree of variability. We improve the performance through a proposed statistical-inspired voting schema that allows some control over false-positive and false-negative rates. Inspecting the chain-of-thought argumentation, we find causal reasoning to justify its answer to a probabilistic query. We show evidence that knowledge-based CIT could eventually become a complementary tool for data-driven causal discovery.
6/12/2024
⛏️
Methods for Recovering Conditional Independence Graphs: A Survey
Harsh Shrivastava, Urszula Chajewska
0
0
Conditional Independence (CI) graphs are a type of probabilistic graphical models that are primarily used to gain insights about feature relationships. Each edge represents the partial correlation between the connected features which gives information about their direct dependence. In this survey, we list out different methods and study the advances in techniques developed to recover CI graphs. We cover traditional optimization methods as well as recently developed deep learning architectures along with their recommended implementations. To facilitate wider adoption, we include preliminaries that consolidate associated operations, for example techniques to obtain covariance matrix for mixed datatypes.
6/12/2024
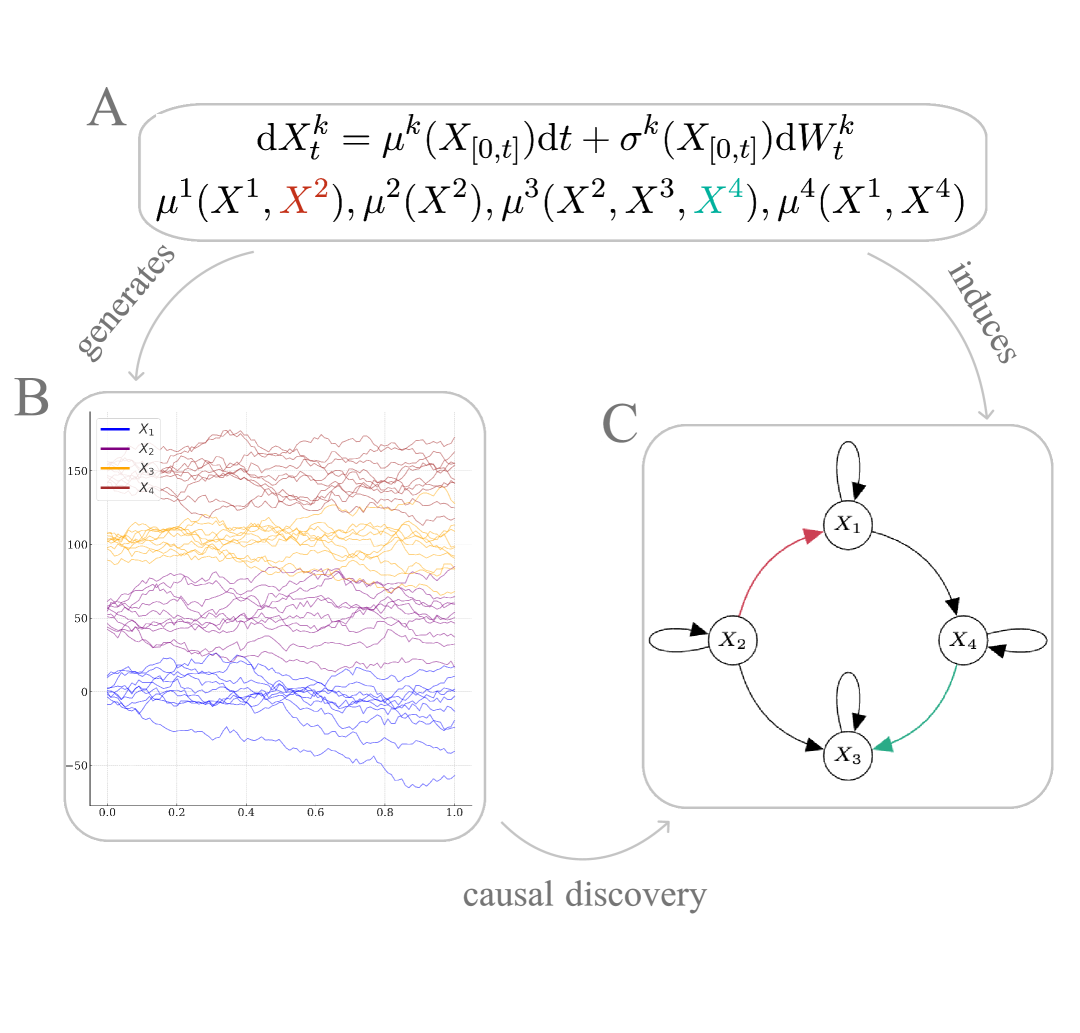
Signature Kernel Conditional Independence Tests in Causal Discovery for Stochastic Processes
Georg Manten, Cecilia Casolo, Emilio Ferrucci, S{o}ren Wengel Mogensen, Cristopher Salvi, Niki Kilbertus
0
0
Inferring the causal structure underlying stochastic dynamical systems from observational data holds great promise in domains ranging from science and health to finance. Such processes can often be accurately modeled via stochastic differential equations (SDEs), which naturally imply causal relationships via which variables enter the differential of which other variables. In this paper, we develop a kernel-based test of conditional independence (CI) on path-space -- e.g., solutions to SDEs, but applicable beyond that -- by leveraging recent advances in signature kernels. We demonstrate strictly superior performance of our proposed CI test compared to existing approaches on path-space and provide theoretical consistency results. Then, we develop constraint-based causal discovery algorithms for acyclic stochastic dynamical systems (allowing for self-loops) that leverage temporal information to recover the entire directed acyclic graph. Assuming faithfulness and a CI oracle, we show that our algorithms are sound and complete. We empirically verify that our developed CI test in conjunction with the causal discovery algorithms outperform baselines across a range of settings.
6/12/2024