MFF-EINV2: Multi-scale Feature Fusion across Spectral-Spatial-Temporal Domains for Sound Event Localization and Detection

0

Sign in to get full access
Overview
- This paper presents a novel sound event localization and detection (SELD) model called MFF-EINV2 that fuses multi-scale features across spectral, spatial, and temporal domains.
- The proposed method employs a multi-level feature fusion architecture to effectively capture and integrate information from different modalities.
- Key innovations include the use of SFFNet, SFDDF, and MFLN modules for multi-scale feature fusion.
- The model is evaluated on benchmark SELD datasets and demonstrates state-of-the-art performance.
Plain English Explanation
The paper describes a new deep learning model called MFF-EINV2 that is designed to locate and detect sound events. The key innovation is the way the model fuses information from different perspectives or "domains" - the spectral (frequency) domain, the spatial (location) domain, and the temporal (time) domain.
Typically, SELD models process audio data in one or two of these domains, but MFF-EINV2 combines features from all three. It does this using specialized "fusion" modules, like SFFNet, that can effectively integrate information across scales and modalities.
The result is a more holistic understanding of the audio scene, allowing the model to better pinpoint the location and timing of sound events. This multi-faceted approach leads to state-of-the-art SELD performance on standard benchmarks.
Technical Explanation
The MFF-EINV2 model uses a multi-level feature fusion architecture to combine information from the spectral, spatial, and temporal domains for sound event localization and detection.
At the core of the model are several innovative fusion modules. The SFFNet module fuses spatial and frequency-domain features using a wavelet-based approach. The SFDDF module integrates spatial and frequency features in a dual-domain manner. And the MFLN module performs lightweight multi-level feature fusion for stereo inputs.
These fusion modules are stacked in a hierarchical manner to progressively combine features from the three domains at multiple scales. This allows the model to capture both local and global acoustic information.
The final fused features are then fed into a detection head and a localization head to predict the presence/absence of sound events and their spatial coordinates, respectively. The model is trained end-to-end on benchmark SELD datasets.
Critical Analysis
The authors thoroughly evaluate MFF-EINV2 on multiple SELD datasets and demonstrate state-of-the-art performance. However, they acknowledge several limitations and areas for future work:
- The model's complexity may limit its deployment in real-time or low-power applications. Techniques like model pruning or compression could be explored to improve efficiency.
- The fusion modules were designed manually, rather than learned in an end-to-end fashion. MFDS-Net and Triple-Domain show that learned fusion can further improve performance.
- The model assumes a fixed number of sound sources, which may not always be the case in real-world scenarios. Extending the approach to handle a variable number of sources would be valuable.
Overall, MFF-EINV2 represents a significant advance in SELD, but there is still room for improvement in terms of efficiency, adaptability, and end-to-end optimization of the fusion process.
Conclusion
The MFF-EINV2 model presented in this paper demonstrates the value of fusing multi-scale features across spectral, spatial, and temporal domains for sound event localization and detection. By effectively combining information from these complementary perspectives, the model achieves state-of-the-art performance on benchmark datasets.
While the proposed fusion architecture and modules are novel and effective, there are opportunities to further optimize the model for efficiency and adaptability. Future work could explore learned fusion mechanisms and variable-source handling to enhance the model's real-world applicability. Overall, this research represents an important step forward in developing robust and versatile SELD systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MFF-EINV2: Multi-scale Feature Fusion across Spectral-Spatial-Temporal Domains for Sound Event Localization and Detection
Da Mu, Zhicheng Zhang, Haobo Yue
Sound Event Localization and Detection (SELD) involves detecting and localizing sound events using multichannel sound recordings. Previously proposed Event-Independent Network V2 (EINV2) has achieved outstanding performance on SELD. However, it still faces challenges in effectively extracting features across spectral, spatial, and temporal domains. This paper proposes a three-stage network structure named Multi-scale Feature Fusion (MFF) module to fully extract multi-scale features across spectral, spatial, and temporal domains. The MFF module utilizes parallel subnetworks architecture to generate multi-scale spectral and spatial features. The TF-Convolution Module is employed to provide multi-scale temporal features. We incorporated MFF into EINV2 and term the proposed method as MFF-EINV2. Experimental results in 2022 and 2023 DCASE challenge task3 datasets show the effectiveness of our MFF-EINV2, which achieves state-of-the-art (SOTA) performance compared to published methods.
Read more6/18/2024

0
SFFNet: A Wavelet-Based Spatial and Frequency Domain Fusion Network for Remote Sensing Segmentation
Yunsong Yang, Genji Yuan, Jinjiang Li
In order to fully utilize spatial information for segmentation and address the challenge of handling areas with significant grayscale variations in remote sensing segmentation, we propose the SFFNet (Spatial and Frequency Domain Fusion Network) framework. This framework employs a two-stage network design: the first stage extracts features using spatial methods to obtain features with sufficient spatial details and semantic information; the second stage maps these features in both spatial and frequency domains. In the frequency domain mapping, we introduce the Wavelet Transform Feature Decomposer (WTFD) structure, which decomposes features into low-frequency and high-frequency components using the Haar wavelet transform and integrates them with spatial features. To bridge the semantic gap between frequency and spatial features, and facilitate significant feature selection to promote the combination of features from different representation domains, we design the Multiscale Dual-Representation Alignment Filter (MDAF). This structure utilizes multiscale convolutions and dual-cross attentions. Comprehensive experimental results demonstrate that, compared to existing methods, SFFNet achieves superior performance in terms of mIoU, reaching 84.80% and 87.73% respectively.The code is located at https://github.com/yysdck/SFFNet.
Read more5/6/2024
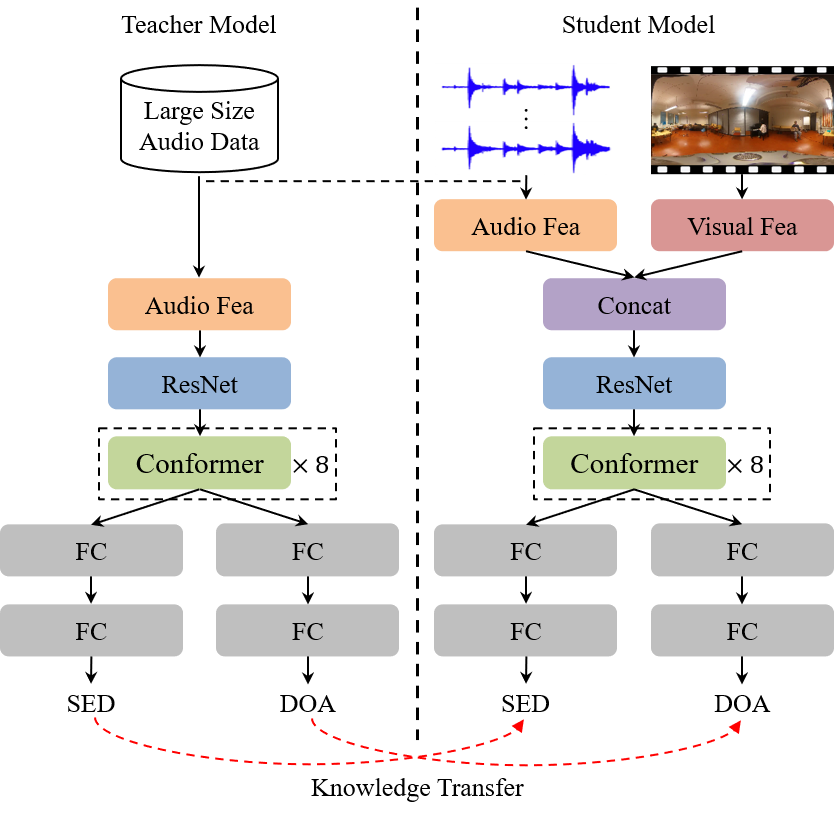
0
Exploring Audio-Visual Information Fusion for Sound Event Localization and Detection In Low-Resource Realistic Scenarios
Ya Jiang, Qing Wang, Jun Du, Maocheng Hu, Pengfei Hu, Zeyan Liu, Shi Cheng, Zhaoxu Nian, Yuxuan Dong, Mingqi Cai, Xin Fang, Chin-Hui Lee
This study presents an audio-visual information fusion approach to sound event localization and detection (SELD) in low-resource scenarios. We aim at utilizing audio and video modality information through cross-modal learning and multi-modal fusion. First, we propose a cross-modal teacher-student learning (TSL) framework to transfer information from an audio-only teacher model, trained on a rich collection of audio data with multiple data augmentation techniques, to an audio-visual student model trained with only a limited set of multi-modal data. Next, we propose a two-stage audio-visual fusion strategy, consisting of an early feature fusion and a late video-guided decision fusion to exploit synergies between audio and video modalities. Finally, we introduce an innovative video pixel swapping (VPS) technique to extend an audio channel swapping (ACS) method to an audio-visual joint augmentation. Evaluation results on the Detection and Classification of Acoustic Scenes and Events (DCASE) 2023 Challenge data set demonstrate significant improvements in SELD performances. Furthermore, our submission to the SELD task of the DCASE 2023 Challenge ranks first place by effectively integrating the proposed techniques into a model ensemble.
Read more6/24/2024

0
Multi-scale Multi-instance Visual Sound Localization and Segmentation
Shentong Mo, Haofan Wang
Visual sound localization is a typical and challenging problem that predicts the location of objects corresponding to the sound source in a video. Previous methods mainly used the audio-visual association between global audio and one-scale visual features to localize sounding objects in each image. Despite their promising performance, they omitted multi-scale visual features of the corresponding image, and they cannot learn discriminative regions compared to ground truths. To address this issue, we propose a novel multi-scale multi-instance visual sound localization framework, namely M2VSL, that can directly learn multi-scale semantic features associated with sound sources from the input image to localize sounding objects. Specifically, our M2VSL leverages learnable multi-scale visual features to align audio-visual representations at multi-level locations of the corresponding image. We also introduce a novel multi-scale multi-instance transformer to dynamically aggregate multi-scale cross-modal representations for visual sound localization. We conduct extensive experiments on VGGSound-Instruments, VGG-Sound Sources, and AVSBench benchmarks. The results demonstrate that the proposed M2VSL can achieve state-of-the-art performance on sounding object localization and segmentation.
Read more9/4/2024