Multi-scale Multi-instance Visual Sound Localization and Segmentation

0

Sign in to get full access
Overview
- The paper presents a novel approach for multi-scale multi-instance visual sound localization and segmentation.
- It introduces a deep learning model that can locate and segment sound sources in videos, using both visual and audio cues.
- The model can handle multiple sound sources at different scales within a single video frame.
Plain English Explanation
The paper describes a new deep learning model that can analyze videos and identify where different sounds are coming from. This is called "sound localization and segmentation".
The key idea is that the model can detect multiple sound sources at the same time, even if they are at different sizes or locations in the video. For example, it could spot both a person speaking and a dog barking in the same frame.
To do this, the model uses information from both the video (the visual cues) and the audio. By combining these two types of data, the model can more accurately pinpoint where the different sounds are originating.
This cross-modal cognitive consensus guided audio-visual approach allows the system to align sight and sound and better understand audio-visual information fusion for semantic segmentation.
Technical Explanation
The paper introduces a deep neural network architecture called Multi-scale Multi-instance Visual Sound Localization and Segmentation (MSMVLS). The model takes a video as input and produces two outputs:
- A set of bounding boxes indicating the locations of different sound sources in each video frame.
- A segmentation mask showing which pixels in the frame correspond to each sound source.
The key innovations of the MSMVLS model are:
- Multi-scale processing: The model uses a multi-scale feature extraction backbone to capture sound sources at different sizes.
- Multi-instance detection: The model can detect multiple sound sources within a single video frame, rather than just a single source.
- Audio-visual fusion: The model combines visual and audio features to improve the accuracy of sound localization and segmentation.
The authors evaluate their model on several benchmark datasets for audio-visual event localization and segmentation. They show that MSMVLS outperforms previous state-of-the-art methods on these tasks.
Critical Analysis
The paper makes a valuable contribution by introducing a novel architecture that can handle the challenging problem of localizing and segmenting multiple sound sources in videos. The multi-scale and multi-instance capabilities of the model are particularly impressive.
However, the authors acknowledge some limitations of their approach. For example, the model may struggle with very small or occluded sound sources, and its performance could be further improved by incorporating more sophisticated audio processing techniques.
Additionally, the paper does not provide much analysis of the model's robustness or potential biases. It would be useful to understand how the model behaves in more diverse or challenging real-world scenarios, beyond the curated benchmark datasets.
Overall, this research represents an important step forward in audio-visual scene understanding, and the MSMVLS model could have valuable applications in areas like surveillance, human-computer interaction, and content analysis.
Conclusion
This paper presents a novel deep learning model for multi-scale multi-instance visual sound localization and segmentation. The model's ability to detect and localize multiple sound sources in video frames, using both visual and audio cues, is a significant advancement in the field of audio-visual scene understanding.
The technical innovations, such as the multi-scale feature extraction and audio-visual fusion, demonstrate the potential for this approach to be applied in real-world scenarios. While the paper acknowledges some limitations, the overall research represents an important step towards more comprehensive and robust audio-visual perception systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-scale Multi-instance Visual Sound Localization and Segmentation
Shentong Mo, Haofan Wang
Visual sound localization is a typical and challenging problem that predicts the location of objects corresponding to the sound source in a video. Previous methods mainly used the audio-visual association between global audio and one-scale visual features to localize sounding objects in each image. Despite their promising performance, they omitted multi-scale visual features of the corresponding image, and they cannot learn discriminative regions compared to ground truths. To address this issue, we propose a novel multi-scale multi-instance visual sound localization framework, namely M2VSL, that can directly learn multi-scale semantic features associated with sound sources from the input image to localize sounding objects. Specifically, our M2VSL leverages learnable multi-scale visual features to align audio-visual representations at multi-level locations of the corresponding image. We also introduce a novel multi-scale multi-instance transformer to dynamically aggregate multi-scale cross-modal representations for visual sound localization. We conduct extensive experiments on VGGSound-Instruments, VGG-Sound Sources, and AVSBench benchmarks. The results demonstrate that the proposed M2VSL can achieve state-of-the-art performance on sounding object localization and segmentation.
Read more9/4/2024
0
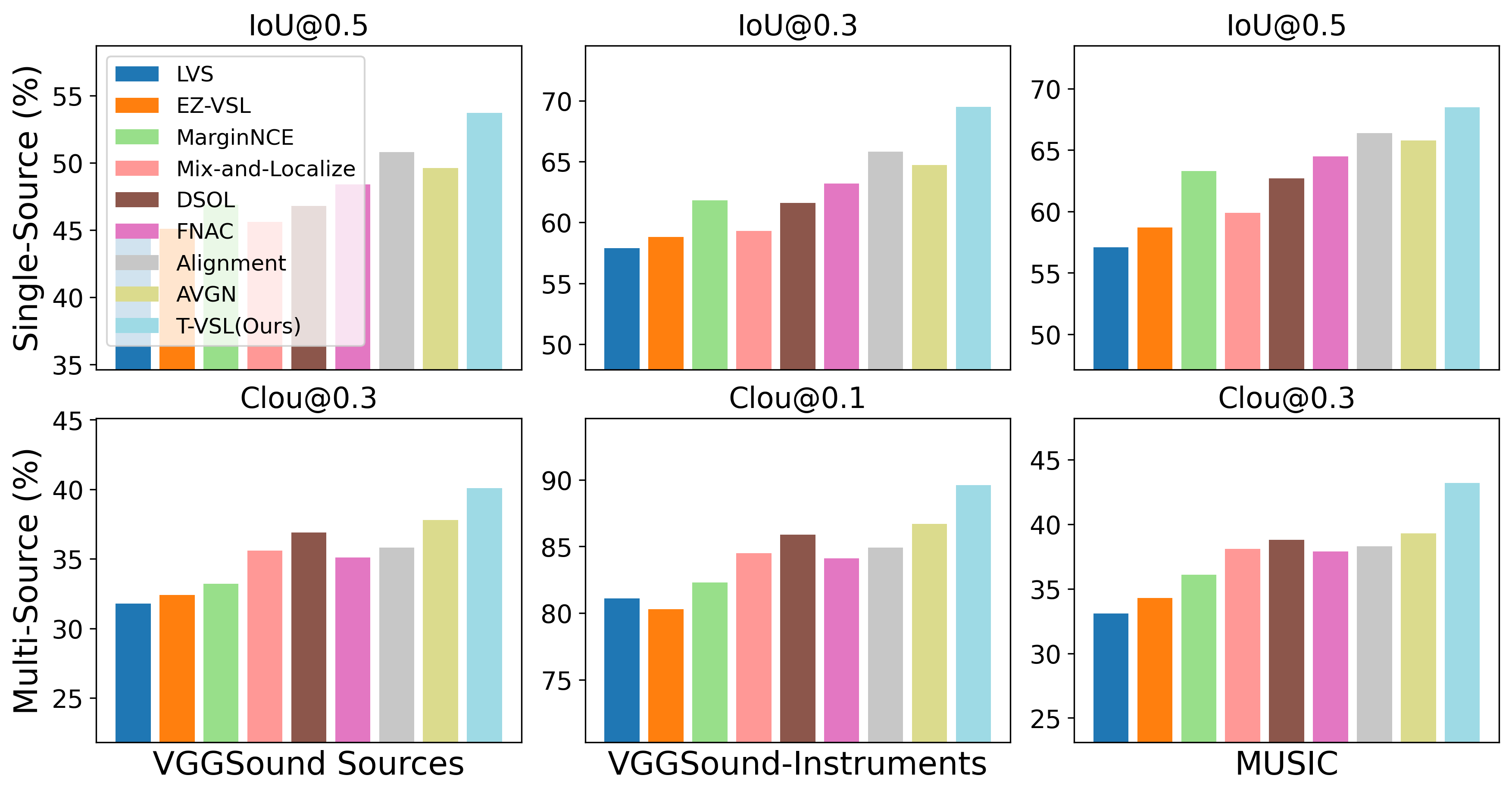
T-VSL: Text-Guided Visual Sound Source Localization in Mixtures
Tanvir Mahmud, Yapeng Tian, Diana Marculescu
Visual sound source localization poses a significant challenge in identifying the semantic region of each sounding source within a video. Existing self-supervised and weakly supervised source localization methods struggle to accurately distinguish the semantic regions of each sounding object, particularly in multi-source mixtures. These methods often rely on audio-visual correspondence as guidance, which can lead to substantial performance drops in complex multi-source localization scenarios. The lack of access to individual source sounds in multi-source mixtures during training exacerbates the difficulty of learning effective audio-visual correspondence for localization. To address this limitation, in this paper, we propose incorporating the text modality as an intermediate feature guide using tri-modal joint embedding models (e.g., AudioCLIP) to disentangle the semantic audio-visual source correspondence in multi-source mixtures. Our framework, dubbed T-VSL, begins by predicting the class of sounding entities in mixtures. Subsequently, the textual representation of each sounding source is employed as guidance to disentangle fine-grained audio-visual source correspondence from multi-source mixtures, leveraging the tri-modal AudioCLIP embedding. This approach enables our framework to handle a flexible number of sources and exhibits promising zero-shot transferability to unseen classes during test time. Extensive experiments conducted on the MUSIC, VGGSound, and VGGSound-Instruments datasets demonstrate significant performance improvements over state-of-the-art methods. Code is released at https://github.com/enyac-group/T-VSL/tree/main
Read more7/9/2024

0
Unveiling Visual Biases in Audio-Visual Localization Benchmarks
Liangyu Chen, Zihao Yue, Boshen Xu, Qin Jin
Audio-Visual Source Localization (AVSL) aims to localize the source of sound within a video. In this paper, we identify a significant issue in existing benchmarks: the sounding objects are often easily recognized based solely on visual cues, which we refer to as visual bias. Such biases hinder these benchmarks from effectively evaluating AVSL models. To further validate our hypothesis regarding visual biases, we examine two representative AVSL benchmarks, VGG-SS and EpicSounding-Object, where the vision-only models outperform all audiovisual baselines. Our findings suggest that existing AVSL benchmarks need further refinement to facilitate audio-visual learning.
Read more9/12/2024

0
Cross-modal Cognitive Consensus guided Audio-Visual Segmentation
Zhaofeng Shi, Qingbo Wu, Fanman Meng, Linfeng Xu, Hongliang Li
Audio-Visual Segmentation (AVS) aims to extract the sounding object from a video frame, which is represented by a pixel-wise segmentation mask for application scenarios such as multi-modal video editing, augmented reality, and intelligent robot systems. The pioneering work conducts this task through dense feature-level audio-visual interaction, which ignores the dimension gap between different modalities. More specifically, the audio clip could only provide a Global semantic label in each sequence, but the video frame covers multiple semantic objects across different Local regions, which leads to mislocalization of the representationally similar but semantically different object. In this paper, we propose a Cross-modal Cognitive Consensus guided Network (C3N) to align the audio-visual semantics from the global dimension and progressively inject them into the local regions via an attention mechanism. Firstly, a Cross-modal Cognitive Consensus Inference Module (C3IM) is developed to extract a unified-modal label by integrating audio/visual classification confidence and similarities of modality-agnostic label embeddings. Then, we feed the unified-modal label back to the visual backbone as the explicit semantic-level guidance via a Cognitive Consensus guided Attention Module (CCAM), which highlights the local features corresponding to the interested object. Extensive experiments on the Single Sound Source Segmentation (S4) setting and Multiple Sound Source Segmentation (MS3) setting of the AVSBench dataset demonstrate the effectiveness of the proposed method, which achieves state-of-the-art performance. Code is available at https://github.com/ZhaofengSHI/AVS-C3N.
Read more7/18/2024