Multi-Level Feature Fusion Network for Lightweight Stereo Image Super-Resolution

0
✨
Sign in to get full access
Overview
- Stereo image super-resolution utilizes the disparity between left and right perspective images to reconstruct higher-quality images
- Existing methods focus on cascading feature extraction and cross-view feature interaction modules, which increases network complexity
- The paper proposes an efficient Multi-Level Feature Fusion Network for Lightweight Stereo Image Super-Resolution (MFFSSR)
Plain English Explanation
When you take two photos of the same scene from slightly different angles, the slight difference in perspective is called the "disparity effect." This disparity can be used to reconstruct higher-quality images through a process called "stereo image super-resolution."
Many existing methods for stereo image super-resolution use complex networks with multiple feature extraction and cross-view interaction modules. While this can improve performance, it also makes the networks larger and more computationally expensive.
To address this, the researchers propose a more efficient network called MFFSSR. It uses a Hybrid Attention Feature Extraction Block (HAFEB) to extract multi-level features from each view, and a cross-view interaction module that efficiently shares information between the views. This allows MFFSSR to reconstruct accurate image details and textures more efficiently than previous methods.
Technical Explanation
The key components of MFFSSR are:
-
Hybrid Attention Feature Extraction Block (HAFEB): This module extracts multi-level intra-view features using a combination of spatial and channel attention mechanisms. The channel separation strategy allows the embedded cross-view interaction module to efficiently share information between the left and right views.
-
Cross-View Feature Interaction: The channel-separated features from the HAFEB modules are fused using a cross-view interaction module, which enhances the complementary information between the left and right views.
-
Multi-Level Feature Fusion: Features from multiple levels of the HAFEB modules are fused to reconstruct the final high-resolution image, capturing details and textures at different scales.
Extensive experiments demonstrate that MFFSSR achieves superior performance in stereo image super-resolution while using fewer network parameters compared to previous methods.
Critical Analysis
The paper provides a thorough evaluation of MFFSSR against various state-of-the-art stereo image super-resolution methods. However, the authors do not discuss potential limitations or future research directions in depth.
One area for further exploration could be the applicability of MFFSSR to other types of multi-view or depth-aware super-resolution tasks, beyond just stereo images. Additionally, the authors could investigate ways to further improve the efficiency of the cross-view feature interaction module, as this is a critical component of their proposed approach.
Overall, the MFFSSR framework represents an interesting and promising direction for lightweight, high-performance stereo image super-resolution, with potential for broader impact in multi-view super-resolution and related fields.
Conclusion
The proposed MFFSSR network offers an efficient solution for stereo image super-resolution, leveraging a Hybrid Attention Feature Extraction Block and cross-view feature interaction to reconstruct high-quality images with fewer network parameters. This work demonstrates the potential for more streamlined, yet effective, approaches to leveraging multi-view information for image enhancement tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
0
Multi-Level Feature Fusion Network for Lightweight Stereo Image Super-Resolution
Yunxiang Li, Wenbin Zou, Qiaomu Wei, Feng Huang, Jing Wu
Stereo image super-resolution utilizes the cross-view complementary information brought by the disparity effect of left and right perspective images to reconstruct higher-quality images. Cascading feature extraction modules and cross-view feature interaction modules to make use of the information from stereo images is the focus of numerous methods. However, this adds a great deal of network parameters and structural redundancy. To facilitate the application of stereo image super-resolution in downstream tasks, we propose an efficient Multi-Level Feature Fusion Network for Lightweight Stereo Image Super-Resolution (MFFSSR). Specifically, MFFSSR utilizes the Hybrid Attention Feature Extraction Block (HAFEB) to extract multi-level intra-view features. Using the channel separation strategy, HAFEB can efficiently interact with the embedded cross-view interaction module. This structural configuration can efficiently mine features inside the view while improving the efficiency of cross-view information sharing. Hence, reconstruct image details and textures more accurately. Abundant experiments demonstrate the effectiveness of MFFSSR. We achieve superior performance with fewer parameters. The source code is available at https://github.com/KarosLYX/MFFSSR.
Read more5/10/2024
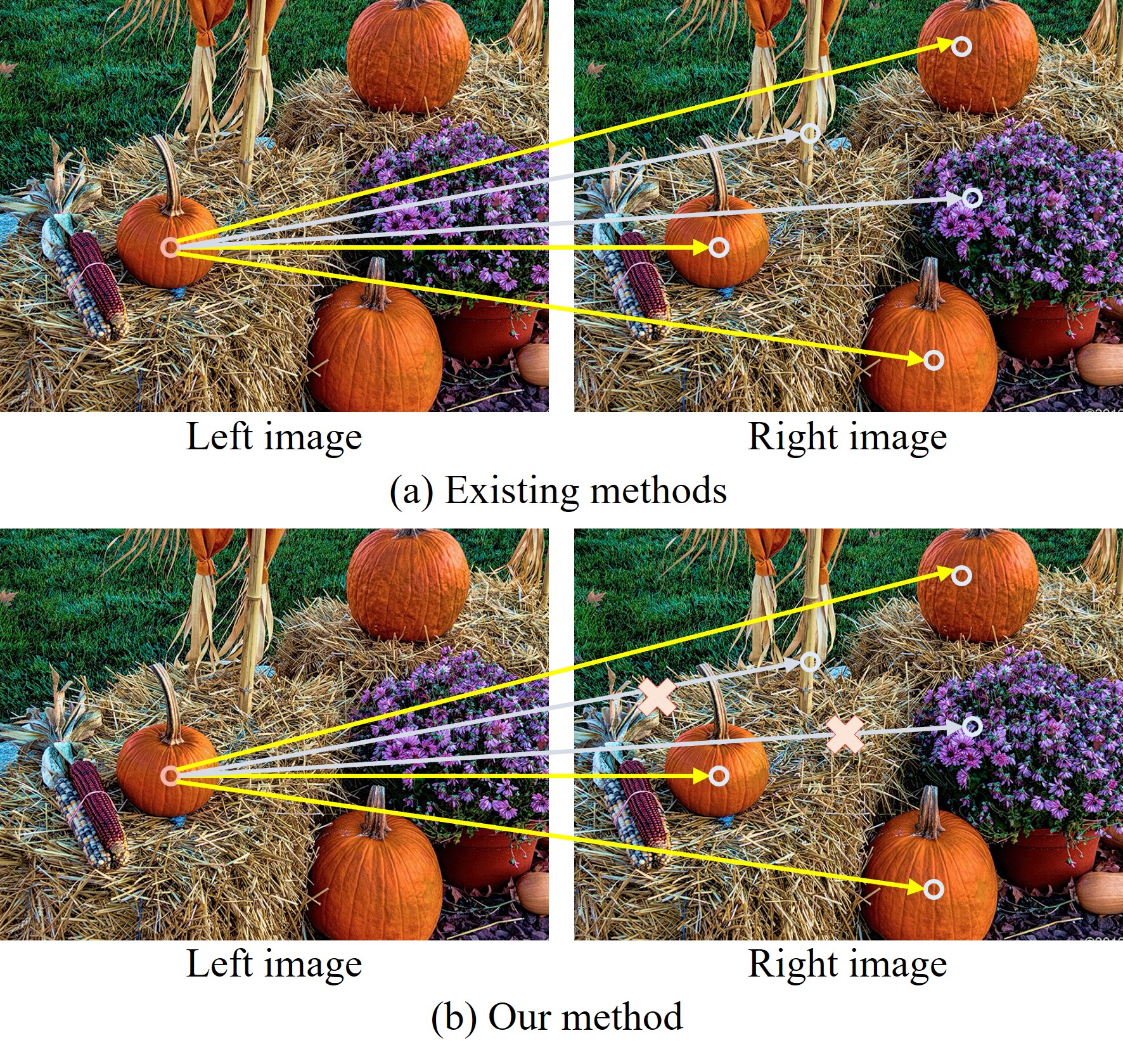
0
Learning Accurate and Enriched Features for Stereo Image Super-Resolution
Hu Gao, Depeng Dang
Stereo image super-resolution (stereoSR) aims to enhance the quality of super-resolution results by incorporating complementary information from an alternative view. Although current methods have shown significant advancements, they typically operate on representations at full resolution to preserve spatial details, facing challenges in accurately capturing contextual information. Simultaneously, they utilize all feature similarities to cross-fuse information from the two views, potentially disregarding the impact of irrelevant information. To overcome this problem, we propose a mixed-scale selective fusion network (MSSFNet) to preserve precise spatial details and incorporate abundant contextual information, and adaptively select and fuse most accurate features from two views to enhance the promotion of high-quality stereoSR. Specifically, we develop a mixed-scale block (MSB) that obtains contextually enriched feature representations across multiple spatial scales while preserving precise spatial details. Furthermore, to dynamically retain the most essential cross-view information, we design a selective fusion attention module (SFAM) that searches and transfers the most accurate features from another view. To learn an enriched set of local and non-local features, we introduce a fast fourier convolution block (FFCB) to explicitly integrate frequency domain knowledge. Extensive experiments show that MSSFNet achieves significant improvements over state-of-the-art approaches on both quantitative and qualitative evaluations.
Read more6/26/2024
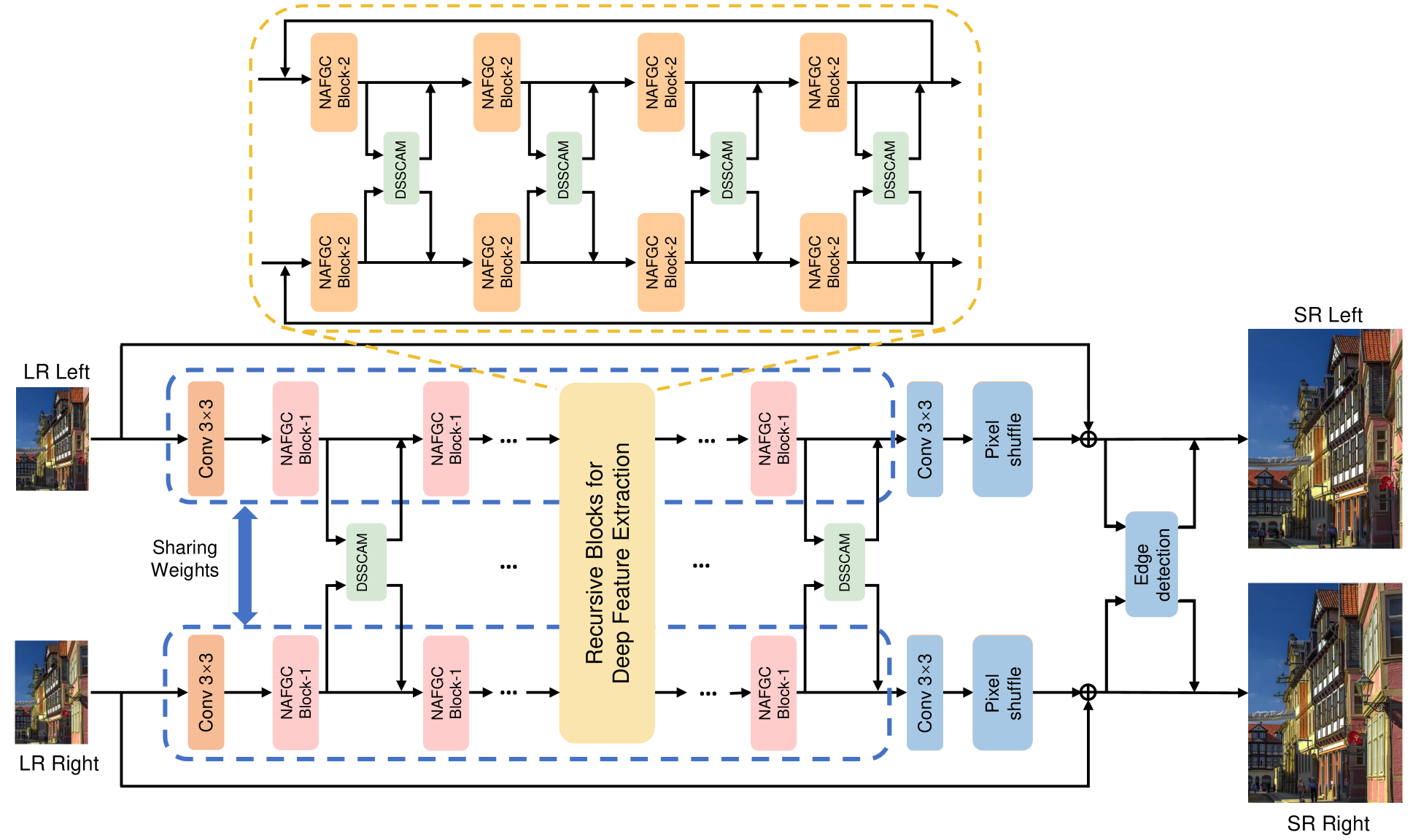
0
NAFRSSR: a Lightweight Recursive Network for Efficient Stereo Image Super-Resolution
Yihong Chen, Zhen Fan, Shuai Dong, Zhiwei Chen, Wenjie Li, Minghui Qin, Min Zeng, Xubing Lu, Guofu Zhou, Xingsen Gao, Jun-Ming Liu
Stereo image super-resolution (SR) refers to the reconstruction of a high-resolution (HR) image from a pair of low-resolution (LR) images as typically captured by a dual-camera device. To enhance the quality of SR images, most previous studies focused on increasing the number and size of feature maps and introducing complex and computationally intensive structures, resulting in models with high computational complexity. Here, we propose a simple yet efficient stereo image SR model called NAFRSSR, which is modified from the previous state-of-the-art model NAFSSR by introducing recursive connections and lightweighting the constituent modules. Our NAFRSSR model is composed of nonlinear activation free and group convolution-based blocks (NAFGCBlocks) and depth-separated stereo cross attention modules (DSSCAMs). The NAFGCBlock improves feature extraction and reduces number of parameters by removing the simple channel attention mechanism from NAFBlock and using group convolution. The DSSCAM enhances feature fusion and reduces number of parameters by replacing 1x1 pointwise convolution in SCAM with weight-shared 3x3 depthwise convolution. Besides, we propose to incorporate trainable edge detection operator into NAFRSSR to further improve the model performance. Four variants of NAFRSSR with different sizes, namely, NAFRSSR-Mobile (NAFRSSR-M), NAFRSSR-Tiny (NAFRSSR-T), NAFRSSR-Super (NAFRSSR-S) and NAFRSSR-Base (NAFRSSR-B) are designed, and they all exhibit fewer parameters, higher PSNR/SSIM, and faster speed than the previous state-of-the-art models. In particular, to the best of our knowledge, NAFRSSR-M is the lightest (0.28M parameters) and fastest (50 ms inference time) model achieving an average PSNR/SSIM as high as 24.657 dB/0.7622 on the benchmark datasets. Codes and models will be released at https://github.com/JNUChenYiHong/NAFRSSR.
Read more5/15/2024

0
Lightweight Multiscale Feature Fusion Super-Resolution Network Based on Two-branch Convolution and Transformer
Li Ke, Liu Yukai
The single image super-resolution(SISR) algorithms under deep learning currently have two main models, one based on convolutional neural networks and the other based on Transformer. The former uses the stacking of convolutional layers with different convolutional kernel sizes to design the model, which enables the model to better extract the local features of the image; the latter uses the self-attention mechanism to design the model, which allows the model to establish long-distance dependencies between image pixel points through the self-attention mechanism and then better extract the global features of the image. However, both of the above methods face their problems. Based on this, this paper proposes a new lightweight multi-scale feature fusion network model based on two-way complementary convolutional and Transformer, which integrates the respective features of Transformer and convolutional neural networks through a two-branch network architecture, to realize the mutual fusion of global and local information. Meanwhile, considering the partial loss of information caused by the low-pixel images trained by the deep neural network, this paper designs a modular connection method of multi-stage feature supplementation to fuse the feature maps extracted from the shallow stage of the model with those extracted from the deep stage of the model, to minimize the loss of the information in the feature images that is beneficial to the image restoration as much as possible, to facilitate the obtaining of a higher-quality restored image. The practical results finally show that the model proposed in this paper is optimal in image recovery performance when compared with other lightweight models with the same amount of parameters.
Read more9/11/2024