MGIMM: Multi-Granularity Instruction Multimodal Model for Attribute-Guided Remote Sensing Image Detailed Description

0
📈
Sign in to get full access
Overview
- This document appears to be a technical paper or research article, but the provided HTML file does not contain any actual text content.
- The HTML file includes references to various CSS and JavaScript resources, suggesting it is likely a web-based presentation or interactive document.
- However, without the actual text content, it is not possible to provide a detailed plain English summary or technical explanation of the research.
Plain English Explanation
Since the provided HTML file does not contain the actual text content of the research paper, I am unable to provide a plain English explanation. Without access to the full text of the paper, I cannot summarize the core ideas and their significance in easy-to-understand terms, or describe the research using analogies and examples.
Technical Explanation
Without the text content of the research paper, I cannot provide a technical explanation covering the key elements, such as the experiment design, architecture, and insights. The HTML file alone does not contain enough information to analyze the technical details of the research.
Critical Analysis
Due to the lack of text content in the provided HTML file, I cannot critically analyze the research or raise any potential concerns or limitations. A critical analysis requires access to the full research paper and its findings.
Conclusion
Since the HTML file does not contain the actual text content of the research paper, I am unable to summarize the main takeaways or discuss the potential implications of the research. Without the full context of the study, I cannot provide a meaningful conclusion.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
MGIMM: Multi-Granularity Instruction Multimodal Model for Attribute-Guided Remote Sensing Image Detailed Description
Cong Yang, Zuchao Li, Lefei Zhang
Recently, large multimodal models have built a bridge from visual to textual information, but they tend to underperform in remote sensing scenarios. This underperformance is due to the complex distribution of objects and the significant scale differences among targets in remote sensing images, leading to visual ambiguities and insufficient descriptions by these multimodal models. Moreover, the lack of multimodal fine-tuning data specific to the remote sensing field makes it challenging for the model's behavior to align with user queries. To address these issues, this paper proposes an attribute-guided textbf{Multi-Granularity Instruction Multimodal Model (MGIMM)} for remote sensing image detailed description. MGIMM guides the multimodal model to learn the consistency between visual regions and corresponding text attributes (such as object names, colors, and shapes) through region-level instruction tuning. Then, with the multimodal model aligned on region-attribute, guided by multi-grain visual features, MGIMM fully perceives both region-level and global image information, utilizing large language models for comprehensive descriptions of remote sensing images. Due to the lack of a standard benchmark for generating detailed descriptions of remote sensing images, we construct a dataset featuring 38,320 region-attribute pairs and 23,463 image-detailed description pairs. Compared with various advanced methods on this dataset, the results demonstrate the effectiveness of MGIMM's region-attribute guided learning approach. Code can be available at https://github.com/yangcong356/MGIMM.git
Read more6/10/2024

0
RS-GPT4V: A Unified Multimodal Instruction-Following Dataset for Remote Sensing Image Understanding
Linrui Xu, Ling Zhao, Wang Guo, Qiujun Li, Kewang Long, Kaiqi Zou, Yuhan Wang, Haifeng Li
The remote sensing image intelligence understanding model is undergoing a new profound paradigm shift which has been promoted by multi-modal large language model (MLLM), i.e. from the paradigm learning a domain model (LaDM) shifts to paradigm learning a pre-trained general foundation model followed by an adaptive domain model (LaGD). Under the new LaGD paradigm, the old datasets, which have led to advances in RSI intelligence understanding in the last decade, are no longer suitable for fire-new tasks. We argued that a new dataset must be designed to lighten tasks with the following features: 1) Generalization: training model to learn shared knowledge among tasks and to adapt to different tasks; 2) Understanding complex scenes: training model to understand the fine-grained attribute of the objects of interest, and to be able to describe the scene with natural language; 3) Reasoning: training model to be able to realize high-level visual reasoning. In this paper, we designed a high-quality, diversified, and unified multimodal instruction-following dataset for RSI understanding produced by GPT-4V and existing datasets, which we called RS-GPT4V. To achieve generalization, we used a (Question, Answer) which was deduced from GPT-4V via instruction-following to unify the tasks such as captioning and localization; To achieve complex scene, we proposed a hierarchical instruction description with local strategy in which the fine-grained attributes of the objects and their spatial relationships are described and global strategy in which all the local information are integrated to yield detailed instruction descript; To achieve reasoning, we designed multiple-turn QA pair to provide the reasoning ability for a model. The empirical results show that the fine-tuned MLLMs by RS-GPT4V can describe fine-grained information. The dataset is available at: https://github.com/GeoX-Lab/RS-GPT4V.
Read more6/19/2024
0
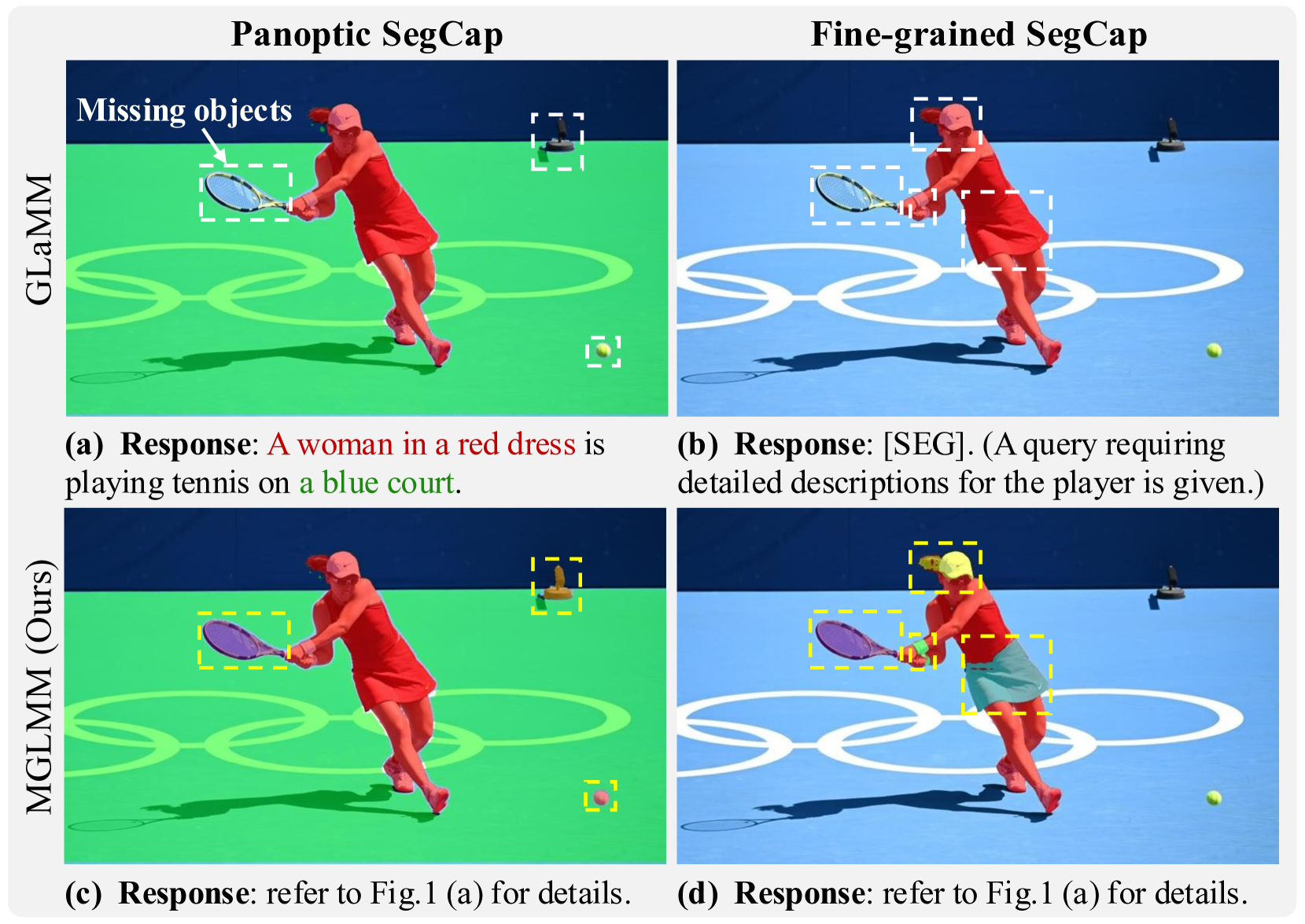
Instruction-guided Multi-Granularity Segmentation and Captioning with Large Multimodal Model
Li Zhou, Xu Yuan, Zenghui Sun, Zikun Zhou, Jingsong Lan
Large Multimodal Models (LMMs) have achieved significant progress by extending large language models. Building on this progress, the latest developments in LMMs demonstrate the ability to generate dense pixel-wise segmentation through the integration of segmentation models.Despite the innovations, the textual responses and segmentation masks of existing works remain at the instance level, showing limited ability to perform fine-grained understanding and segmentation even provided with detailed textual cues.To overcome this limitation, we introduce a Multi-Granularity Large Multimodal Model (MGLMM), which is capable of seamlessly adjusting the granularity of Segmentation and Captioning (SegCap) following user instructions, from panoptic SegCap to fine-grained SegCap. We name such a new task Multi-Granularity Segmentation and Captioning (MGSC). Observing the lack of a benchmark for model training and evaluation over the MGSC task, we establish a benchmark with aligned masks and captions in multi-granularity using our customized automated annotation pipeline. This benchmark comprises 10K images and more than 30K image-question pairs. We will release our dataset along with the implementation of our automated dataset annotation pipeline for further research.Besides, we propose a novel unified SegCap data format to unify heterogeneous segmentation datasets; it effectively facilitates learning to associate object concepts with visual features during multi-task training. Extensive experiments demonstrate that our MGLMM excels at tackling more than eight downstream tasks and achieves state-of-the-art performance in MGSC, GCG, image captioning, referring segmentation, multiple and empty segmentation, and reasoning segmentation tasks. The great performance and versatility of MGLMM underscore its potential impact on advancing multimodal research.
Read more9/23/2024
0
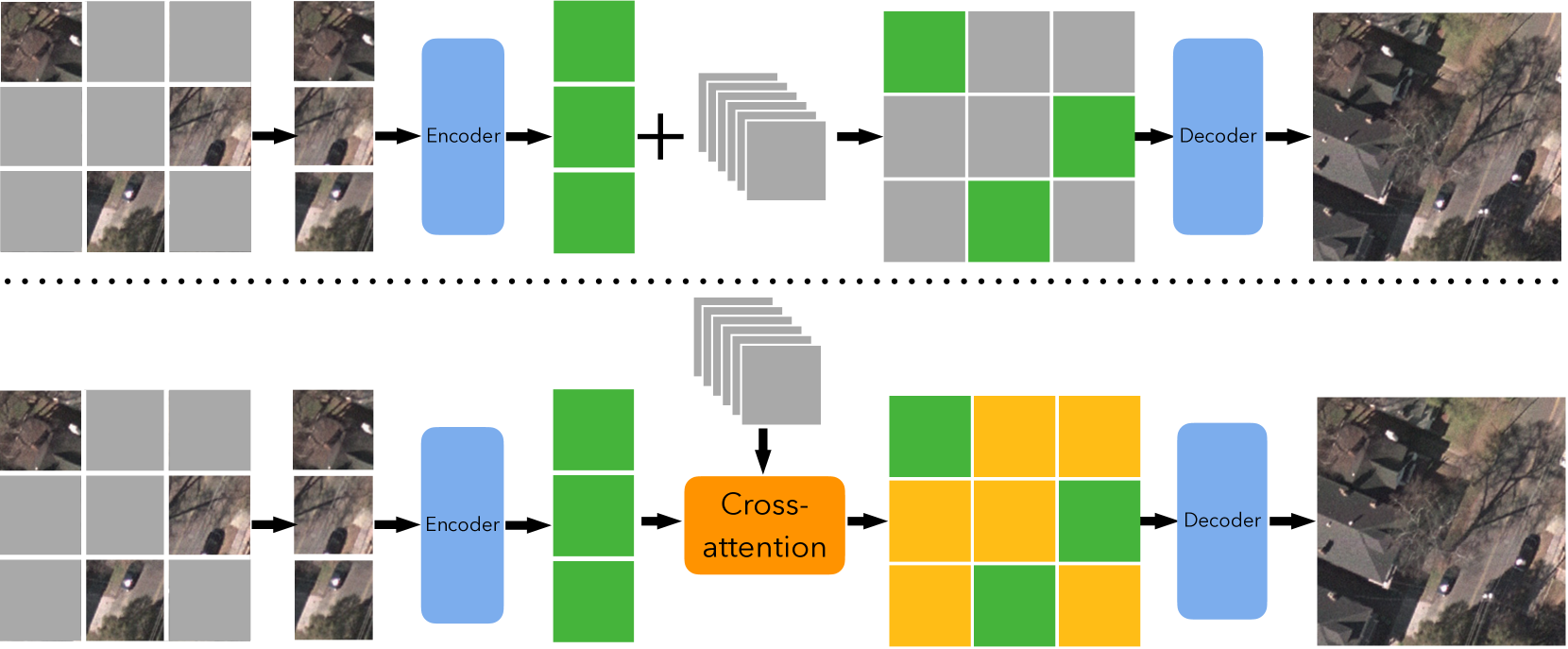
Interactive Masked Image Modeling for Multimodal Object Detection in Remote Sensing
Minh-Duc Vu, Zuheng Ming, Fangchen Feng, Bissmella Bahaduri, Anissa Mokraoui
Object detection in remote sensing imagery plays a vital role in various Earth observation applications. However, unlike object detection in natural scene images, this task is particularly challenging due to the abundance of small, often barely visible objects across diverse terrains. To address these challenges, multimodal learning can be used to integrate features from different data modalities, thereby improving detection accuracy. Nonetheless, the performance of multimodal learning is often constrained by the limited size of labeled datasets. In this paper, we propose to use Masked Image Modeling (MIM) as a pre-training technique, leveraging self-supervised learning on unlabeled data to enhance detection performance. However, conventional MIM such as MAE which uses masked tokens without any contextual information, struggles to capture the fine-grained details due to a lack of interactions with other parts of image. To address this, we propose a new interactive MIM method that can establish interactions between different tokens, which is particularly beneficial for object detection in remote sensing. The extensive ablation studies and evluation demonstrate the effectiveness of our approach.
Read more9/16/2024