MGRR-Net: Multi-level Graph Relational Reasoning Network for Facial Action Units Detection

0
🌐
Sign in to get full access
Overview
- The paper proposes a novel Multi-level Graph Relational Reasoning Network (MGRR-Net) for facial action unit (AU) detection.
- This approach aims to capture the dynamic interactions between local and global facial features, which the authors argue is important for accurately detecting AUs.
- Experiments on DISFA and BP4D datasets show the proposed method outperforms state-of-the-art techniques for AU detection.
Plain English Explanation
The Facial Action Coding System (FACS) is a way to encode the various movements or "action units" (AUs) that can occur in a person's face. Detecting these AUs is important for analyzing facial expressions, which has many applications.
Many existing methods for automatic AU detection focus on modeling the relationships between specific local facial regions or extracting global attention-based features. However, the authors argue that this may not fully capture the rich interactions between the local and global facial features, as well as the variability across different AUs.
To address this, the researchers propose a Multi-level Graph Relational Reasoning Network (MGRR-Net). This network performs feature learning at three different levels - region-level, pixel-wise, and channel-wise. The region-level learning uses a graph neural network to encode the correlations between different AUs, while the pixel-wise and channel-wise learning via graph attention networks enhances the discrimination of the global facial features.
By combining these multi-level features, the MGRR-Net is able to better detect the complex patterns of facial muscle movements that make up different expressions, leading to improved AU recognition performance compared to previous methods.
Technical Explanation
The key innovation of the MGRR-Net is its multi-level feature learning approach. Each layer of the network performs feature extraction at three different granularities:
-
Region-level: A graph neural network is used to model the correlations between different facial regions and the corresponding AUs. This encodes the relationships between local muscle movements.
-
Pixel-wise: A graph attention network is employed to enhance the discrimination of global facial features at the pixel level. This allows the model to capture detailed variability in expression.
-
Channel-wise: Another graph attention network is used to learn salient channel-wise features from the global face representation. This further refines the AU-relevant information.
The features extracted at these three levels are then fused together, allowing the model to jointly reason about the local, regional, and global patterns in the facial imagery. This multi-scale approach is the key to the MGRR-Net's superior performance on the DISFA and BP4D AU detection benchmarks compared to previous state-of-the-art methods.
Critical Analysis
The authors provide a thorough evaluation of the MGRR-Net, demonstrating its effectiveness across multiple facial AU detection datasets. However, a few potential limitations or areas for future work are worth considering:
-
The paper does not explore the model's robustness to variations in facial appearance, occlusions, or other real-world challenges that could impact AU detection in practical applications. Further research on the generalization capabilities of the approach would be valuable.
-
While the multi-level feature learning is a key contribution, the authors do not provide much insight into the relative importance of the different feature levels. Investigating this could lead to further architectural refinements or efficient model design.
-
The computational complexity of the graph-based modules may limit the scalability of the approach, especially for real-time applications. Exploring more efficient graph neural network architectures could be an area for future work.
Overall, the MGRR-Net represents an interesting and promising advance in facial AU detection, but there is still room for further research to address potential limitations and expand the practical applicability of the approach.
Conclusion
The proposed MGRR-Net offers a novel solution for facial action unit detection by leveraging multi-level feature learning to capture the complex interactions between local and global facial characteristics. The authors demonstrate the effectiveness of this approach on benchmark datasets, outperforming existing state-of-the-art methods.
This research highlights the importance of modeling the rich contextual information in facial imagery, rather than relying on just local or global features alone. The MGRR-Net's ability to jointly reason about facial muscles, expressions, and individual characteristics could lead to more robust and accurate facial analysis systems with a wide range of applications, from human-computer interaction to mental health monitoring.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
0
MGRR-Net: Multi-level Graph Relational Reasoning Network for Facial Action Units Detection
Xuri Ge, Joemon M. Jose, Songpei Xu, Xiao Liu, Hu Han
The Facial Action Coding System (FACS) encodes the action units (AUs) in facial images, which has attracted extensive research attention due to its wide use in facial expression analysis. Many methods that perform well on automatic facial action unit (AU) detection primarily focus on modeling various types of AU relations between corresponding local muscle areas, or simply mining global attention-aware facial features, however, neglect the dynamic interactions among local-global features. We argue that encoding AU features just from one perspective may not capture the rich contextual information between regional and global face features, as well as the detailed variability across AUs, because of the diversity in expression and individual characteristics. In this paper, we propose a novel Multi-level Graph Relational Reasoning Network (termed MGRR-Net) for facial AU detection. Each layer of MGRR-Net performs a multi-level (i.e., region-level, pixel-wise and channel-wise level) feature learning. While the region-level feature learning from local face patches features via graph neural network can encode the correlation across different AUs, the pixel-wise and channel-wise feature learning via graph attention network can enhance the discrimination ability of AU features from global face features. The fused features from the three levels lead to improved AU discriminative ability. Extensive experiments on DISFA and BP4D AU datasets show that the proposed approach achieves superior performance than the state-of-the-art methods.
Read more5/24/2024

0
Multi-scale Dynamic and Hierarchical Relationship Modeling for Facial Action Units Recognition
Zihan Wang, Siyang Song, Cheng Luo, Songhe Deng, Weicheng Xie, Linlin Shen
Human facial action units (AUs) are mutually related in a hierarchical manner, as not only they are associated with each other in both spatial and temporal domains but also AUs located in the same/close facial regions show stronger relationships than those of different facial regions. While none of existing approach thoroughly model such hierarchical inter-dependencies among AUs, this paper proposes to comprehensively model multi-scale AU-related dynamic and hierarchical spatio-temporal relationship among AUs for their occurrences recognition. Specifically, we first propose a novel multi-scale temporal differencing network with an adaptive weighting block to explicitly capture facial dynamics across frames at different spatial scales, which specifically considers the heterogeneity of range and magnitude in different AUs' activation. Then, a two-stage strategy is introduced to hierarchically model the relationship among AUs based on their spatial distribution (i.e., local and cross-region AU relationship modelling). Experimental results achieved on BP4D and DISFA show that our approach is the new state-of-the-art in the field of AU occurrence recognition. Our code is publicly available at https://github.com/CVI-SZU/MDHR.
Read more4/10/2024
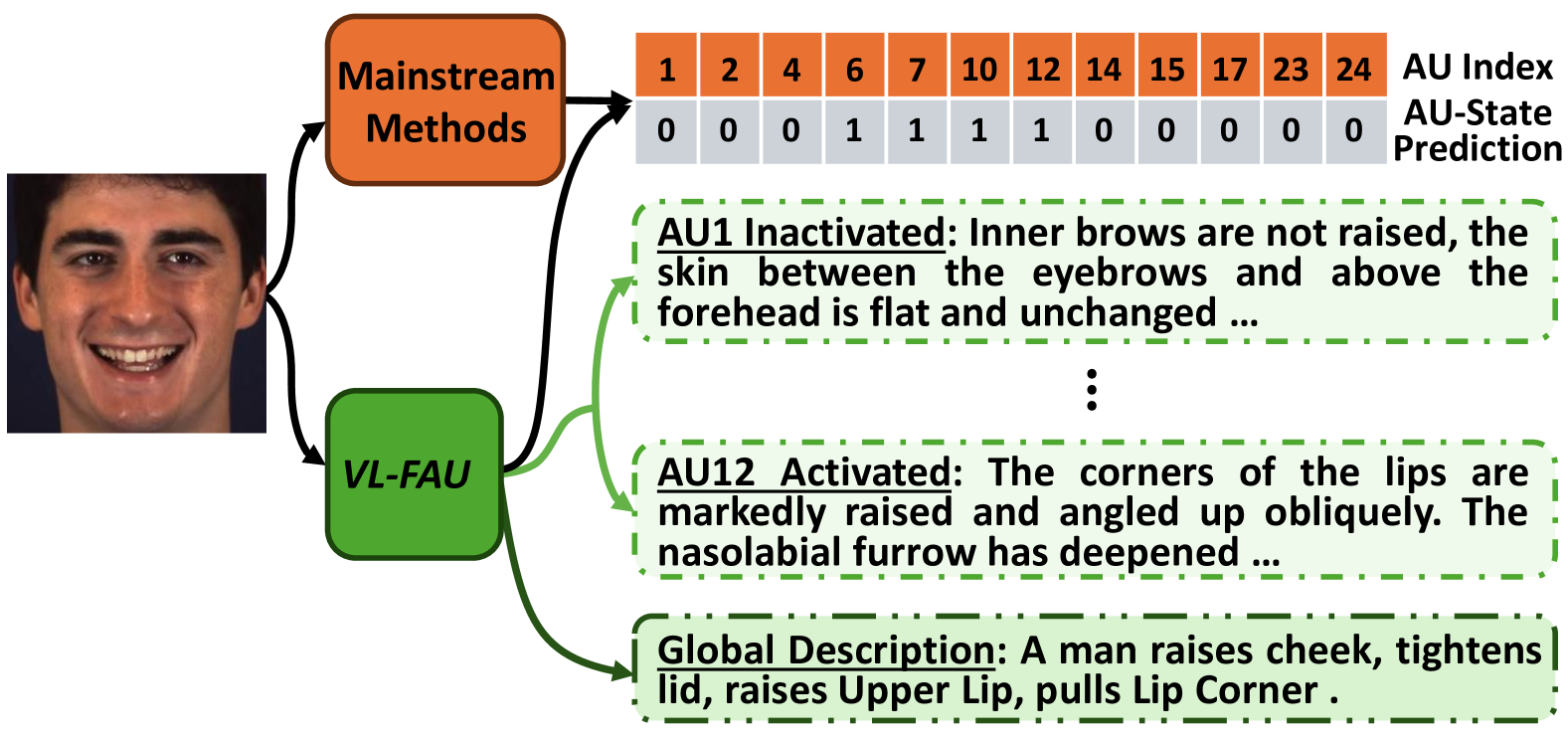
0
Towards End-to-End Explainable Facial Action Unit Recognition via Vision-Language Joint Learning
Xuri Ge, Junchen Fu, Fuhai Chen, Shan An, Nicu Sebe, Joemon M. Jose
Facial action units (AUs), as defined in the Facial Action Coding System (FACS), have received significant research interest owing to their diverse range of applications in facial state analysis. Current mainstream FAU recognition models have a notable limitation, i.e., focusing only on the accuracy of AU recognition and overlooking explanations of corresponding AU states. In this paper, we propose an end-to-end Vision-Language joint learning network for explainable FAU recognition (termed VL-FAU), which aims to reinforce AU representation capability and language interpretability through the integration of joint multimodal tasks. Specifically, VL-FAU brings together language models to generate fine-grained local muscle descriptions and distinguishable global face description when optimising FAU recognition. Through this, the global facial representation and its local AU representations will achieve higher distinguishability among different AUs and different subjects. In addition, multi-level AU representation learning is utilised to improve AU individual attention-aware representation capabilities based on multi-scale combined facial stem feature. Extensive experiments on DISFA and BP4D AU datasets show that the proposed approach achieves superior performance over the state-of-the-art methods on most of the metrics. In addition, compared with mainstream FAU recognition methods, VL-FAU can provide local- and global-level interpretability language descriptions with the AUs' predictions.
Read more8/2/2024

0
Learning Contrastive Feature Representations for Facial Action Unit Detection
Ziqiao Shang, Bin Liu, Fengmao Lv, Fei Teng, Tianrui Li
Facial action unit (AU) detection has long encountered the challenge of detecting subtle feature differences when AUs activate. Existing methods often rely on encoding pixel-level information of AUs, which not only encodes additional redundant information but also leads to increased model complexity and limited generalizability. Additionally, the accuracy of AU detection is negatively impacted by the class imbalance issue of each AU type, and the presence of noisy and false AU labels. In this paper, we introduce a novel contrastive learning framework aimed for AU detection that incorporates both self-supervised and supervised signals, thereby enhancing the learning of discriminative features for accurate AU detection. To tackle the class imbalance issue, we employ a negative sample re-weighting strategy that adjusts the step size of updating parameters for minority and majority class samples. Moreover, to address the challenges posed by noisy and false AU labels, we employ a sampling technique that encompasses three distinct types of positive sample pairs. This enables us to inject self-supervised signals into the supervised signal, effectively mitigating the adverse effects of noisy labels. Our experimental assessments, conducted on four widely-utilized benchmark datasets (BP4D, DISFA, GFT and Aff-Wild2), underscore the superior performance of our approach compared to state-of-the-art methods of AU detection. Our code is available at url{https://github.com/Ziqiao-Shang/AUNCE}.
Read more7/15/2024