MICap: A Unified Model for Identity-aware Movie Descriptions

0
Sign in to get full access
Overview
- MICap is a unified model for generating identity-aware movie descriptions
- It addresses challenges with traditional "fill-in-the-blank" movie description approaches
- The model aims to generate more natural, coherent, and identity-aware movie descriptions
Plain English Explanation
MICap is a new AI model that can generate descriptions of movies in a more natural and identity-aware way. Traditional movie description models often use a "fill-in-the-blank" approach, where they insert character names or other details into a pre-written template. However, this can result in descriptions that feel robotic or disconnected from the actual movie.
MICap: A Unified Model for Identity-aware Movie Descriptions aims to address this by taking a more holistic approach. The model tries to understand the relationships between the characters, the plot, and the overall themes of the movie. It then uses this understanding to generate descriptions that feel more coherent and true to the identity of the film.
For example, rather than just saying "Tom Cruise plays Ethan Hunt in this movie," a MICap-generated description might say "Ethan Hunt, the daring IMF agent, embarks on a high-stakes mission to save the world from a nefarious plot." The model weaves together the character, the plot, and the tone of the movie to create a more immersive and engaging description.
Technical Explanation
MICap: A Unified Model for Identity-aware Movie Descriptions presents a novel approach to movie description generation that aims to capture the identity and essence of a film.
The key innovations of the MICap model are:
-
Unified Modeling: MICap combines information about the characters, plot, and themes of a movie into a single, integrated model. This allows the model to generate descriptions that are more coherent and true to the overall identity of the film.
-
Identity-aware Generation: Rather than simply inserting character names or plot points into a template, MICap generates descriptions that reflect the unique personality and tone of the movie. This results in more natural and engaging descriptions.
-
Multimodal Inputs: MICap leverages both textual information (e.g., movie scripts) and visual information (e.g., movie frames) to build a more comprehensive understanding of the film.
The authors evaluate MICap on several movie description benchmarks and show that it outperforms previous state-of-the-art models in terms of both automatic metrics and human evaluations. This demonstrates the effectiveness of their unified and identity-aware approach to movie description generation.
Critical Analysis
The MICap paper presents a compelling and well-designed model for generating more natural and identity-aware movie descriptions. However, there are a few potential limitations and areas for further research:
-
Scalability: While the authors demonstrate the effectiveness of MICap on several benchmarks, it's unclear how the model would scale to generating descriptions for a large and diverse corpus of movies. Evaluating the model's performance and generalization on a broader range of films would be an important next step.
-
Interpretability: The unified modeling approach used by MICap may make it challenging to understand the specific mechanisms and reasoning behind the generated descriptions. Providing more insight into the model's internal workings could improve its transparency and trustworthiness.
-
Fairness and Bias: As with any AI system trained on real-world data, there is a risk of MICap perpetuating or amplifying societal biases related to gender, race, or other demographic factors. Careful analysis and mitigation of such biases should be a priority.
Overall, the MICap paper presents a promising step forward in the field of movie description generation. By taking a more holistic and identity-aware approach, the model has the potential to generate more engaging and meaningful descriptions that better capture the essence of a film.
Conclusion
MICap: A Unified Model for Identity-aware Movie Descriptions introduces a novel approach to generating movie descriptions that are more natural, coherent, and true to the overall identity of a film. By combining information about characters, plot, and themes into a unified model, the authors demonstrate the ability to produce descriptions that are more engaging and immersive than traditional "fill-in-the-blank" methods.
While the model shows promising results, further research is needed to address potential scalability and interpretability challenges, as well as to ensure fairness and mitigate biases. Nonetheless, the MICap framework represents an important step forward in the field of movie description generation, with the potential to enhance the way we interact with and understand films.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MICap: A Unified Model for Identity-aware Movie Descriptions
Haran Raajesh, Naveen Reddy Desanur, Zeeshan Khan, Makarand Tapaswi
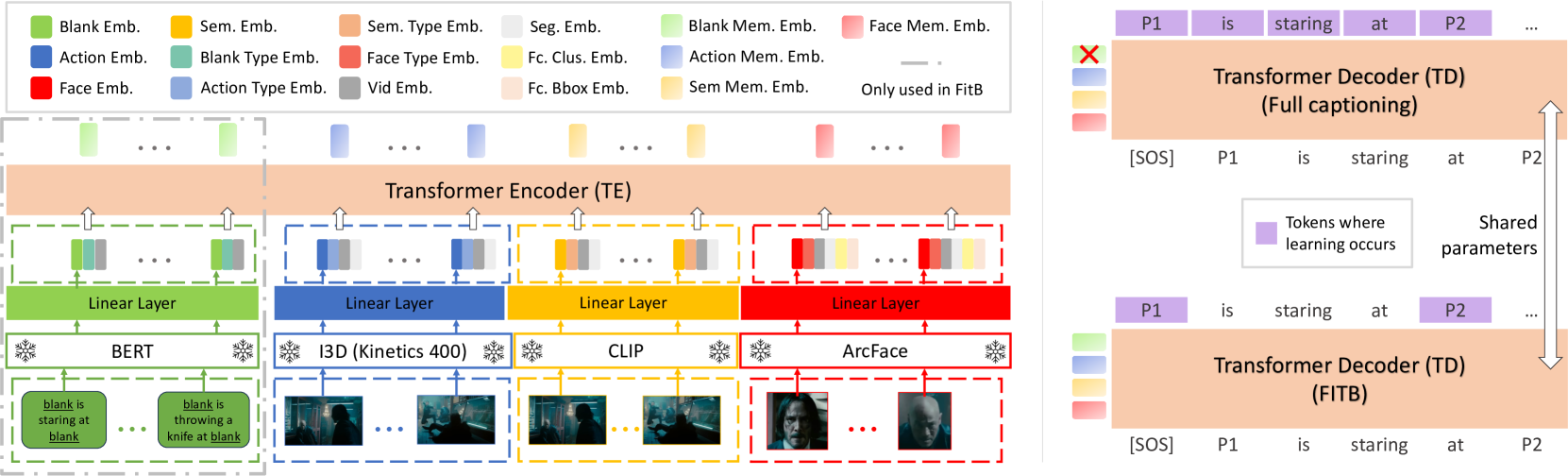
Characters are an important aspect of any storyline and identifying and including them in descriptions is necessary for story understanding. While previous work has largely ignored identity and generated captions with someone (anonymized names), recent work formulates id-aware captioning as a fill-in-the-blanks (FITB) task, where, given a caption with blanks, the goal is to predict person id labels. However, to predict captions with ids, a two-stage approach is required: first predict captions with someone, then fill in identities. In this work, we present a new single stage approach that can seamlessly switch between id-aware caption generation or FITB when given a caption with blanks. Our model, Movie-Identity Captioner (MICap), uses a shared auto-regressive decoder that benefits from training with FITB and full-caption generation objectives, while the encoder can benefit from or disregard captions with blanks as input. Another challenge with id-aware captioning is the lack of a metric to capture subtle differences between person ids. To this end, we introduce iSPICE, a caption evaluation metric that focuses on identity tuples created through intermediate scene graphs. We evaluate MICap on Large-Scale Movie Description Challenge (LSMDC), where we show a 4.2% improvement in FITB accuracy, and a 1-2% bump in classic captioning metrics.
Read more5/21/2024
🖼️
0
CIC: A framework for Culturally-aware Image Captioning
Youngsik Yun, Jihie Kim
Image Captioning generates descriptive sentences from images using Vision-Language Pre-trained models (VLPs) such as BLIP, which has improved greatly. However, current methods lack the generation of detailed descriptive captions for the cultural elements depicted in the images, such as the traditional clothing worn by people from Asian cultural groups. In this paper, we propose a new framework, Culturally-aware Image Captioning (CIC), that generates captions and describes cultural elements extracted from cultural visual elements in images representing cultures. Inspired by methods combining visual modality and Large Language Models (LLMs) through appropriate prompts, our framework (1) generates questions based on cultural categories from images, (2) extracts cultural visual elements from Visual Question Answering (VQA) using generated questions, and (3) generates culturally-aware captions using LLMs with the prompts. Our human evaluation conducted on 45 participants from 4 different cultural groups with a high understanding of the corresponding culture shows that our proposed framework generates more culturally descriptive captions when compared to the image captioning baseline based on VLPs. Resources can be found at https://shane3606.github.io/cic..
Read more8/20/2024

0
IFCap: Image-like Retrieval and Frequency-based Entity Filtering for Zero-shot Captioning
Soeun Lee, Si-Woo Kim, Taewhan Kim, Dong-Jin Kim
Recent advancements in image captioning have explored text-only training methods to overcome the limitations of paired image-text data. However, existing text-only training methods often overlook the modality gap between using text data during training and employing images during inference. To address this issue, we propose a novel approach called Image-like Retrieval, which aligns text features with visually relevant features to mitigate the modality gap. Our method further enhances the accuracy of generated captions by designing a Fusion Module that integrates retrieved captions with input features. Additionally, we introduce a Frequency-based Entity Filtering technique that significantly improves caption quality. We integrate these methods into a unified framework, which we refer to as IFCap ($textbf{I}$mage-like Retrieval and $textbf{F}$requency-based Entity Filtering for Zero-shot $textbf{Cap}$tioning). Through extensive experimentation, our straightforward yet powerful approach has demonstrated its efficacy, outperforming the state-of-the-art methods by a significant margin in both image captioning and video captioning compared to zero-shot captioning based on text-only training.
Read more9/27/2024
🖼️
0
Inserting Faces inside Captions: Image Captioning with Attention Guided Merging
Yannis Tevissen (ARMEDIA-SAMOVAR, ML), Khalil Guetari, Marine Tassel, Erwan Kerleroux, Fr'ed'eric Petitpont
Image captioning models are widely used to describe recent and archived pictures with the objective of improving their accessibility and retrieval. Yet, these approaches tend to be inefficient and biased at retrieving people's names. In this work we introduce AstroCaptions, a dataset for the image captioning task. This dataset specifically contains thousands of public fig-ures that are complex to identify for a traditional model. We also propose a novel post-processing method to insert identified people's names inside the caption using explainable AI tools and the grounding capabilities of vi-sion-language models. The results obtained with this method show signifi-cant improvements of captions quality and a potential of reducing halluci-nations. Up to 93.2% of the persons detected can be inserted in the image captions leading to improvements in the BLEU, ROUGE, CIDEr and METEOR scores of each captioning model.
Read more5/7/2024