Inserting Faces inside Captions: Image Captioning with Attention Guided Merging

0
🖼️
Sign in to get full access
Overview
- This paper introduces a new dataset called AstroCaptions, which is designed for the image captioning task.
- The dataset specifically contains thousands of public figures that are complex to identify for traditional models.
- The paper also proposes a novel post-processing method to insert identified people's names into the image captions using explainable AI tools and the grounding capabilities of vision-language models.
Plain English Explanation
Image captioning models are tools that can automatically describe the contents of images in words. These models are useful for improving the accessibility and searchability of images, especially for people with visual impairments. However, the authors of this paper found that existing image captioning models tend to be inefficient and biased when it comes to identifying the names of people in images.
To address this issue, the researchers created a new dataset called AstroCaptions that contains thousands of images of public figures, which can be challenging for traditional captioning models to identify correctly. The researchers also developed a new post-processing method that uses explainable AI tools and the capabilities of vision-language models to insert the identified names of people into the image captions.
The results of this approach showed significant improvements in the quality of the image captions, with up to 93.2% of the detected people's names being successfully inserted into the captions. This led to better scores on standard captioning evaluation metrics like BLEU, ROUGE, CIDEr, and METEOR.
Overall, this research is an important step towards making image captioning systems more accurate and inclusive, especially when it comes to identifying the people featured in images.
Technical Explanation
The researchers created the AstroCaptions dataset, which contains thousands of images of public figures, to address the limitations of existing image captioning models in identifying people's names. They then developed a novel post-processing method that leverages explainable AI tools and the grounding capabilities of vision-language models to insert the detected names of people into the generated image captions.
The post-processing method first uses an object detection model to identify the people in the images. It then employs explainable AI techniques to determine which parts of the caption correspond to the detected people, and inserts the names into the appropriate places.
The researchers evaluated their approach using standard image captioning metrics, such as BLEU, ROUGE, CIDEr, and METEOR. The results showed significant improvements in caption quality, with up to 93.2% of the detected people's names being successfully inserted into the captions.
The AstroCaptions dataset and the proposed post-processing method represent an important contribution to the field of image captioning, particularly in terms of improving the accuracy and inclusiveness of these models when it comes to identifying people in images.
Critical Analysis
The researchers acknowledge that their dataset and method have some limitations. For instance, the AstroCaptions dataset may not be representative of the full diversity of public figures, and the post-processing method relies on the accuracy of the underlying object detection and explainable AI tools.
Additionally, the paper does not discuss the potential ethical implications of automatically identifying people in images, such as privacy concerns or the risk of reinforcing biases. The authors could have addressed these issues more thoroughly.
Further research could explore ways to integrate the name insertion process more seamlessly into the captioning model, rather than relying on a separate post-processing step. This could potentially lead to even better caption quality and reduce the risk of hallucinations.
Overall, the research presented in this paper is a valuable contribution to the field of image captioning, but there are still opportunities for improvement and further exploration of the ethical considerations.
Conclusion
This paper introduces a new dataset called AstroCaptions and a novel post-processing method to improve the accuracy of image captioning models in identifying and including people's names. The results demonstrate significant improvements in caption quality, with up to 93.2% of detected people's names being successfully inserted into the captions.
This work represents an important step towards making image captioning systems more inclusive and accessible, particularly for people with visual impairments or those interested in searching for images of specific public figures. However, the authors acknowledge the need to address the limitations of their approach and consider the potential ethical implications of their work.
Future research in this area could focus on integrating the name insertion process more seamlessly into the captioning model, as well as exploring ways to ensure the ethical and responsible development of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Inserting Faces inside Captions: Image Captioning with Attention Guided Merging
Yannis Tevissen (ARMEDIA-SAMOVAR, ML), Khalil Guetari, Marine Tassel, Erwan Kerleroux, Fr'ed'eric Petitpont
Image captioning models are widely used to describe recent and archived pictures with the objective of improving their accessibility and retrieval. Yet, these approaches tend to be inefficient and biased at retrieving people's names. In this work we introduce AstroCaptions, a dataset for the image captioning task. This dataset specifically contains thousands of public fig-ures that are complex to identify for a traditional model. We also propose a novel post-processing method to insert identified people's names inside the caption using explainable AI tools and the grounding capabilities of vi-sion-language models. The results obtained with this method show signifi-cant improvements of captions quality and a potential of reducing halluci-nations. Up to 93.2% of the persons detected can be inserted in the image captions leading to improvements in the BLEU, ROUGE, CIDEr and METEOR scores of each captioning model.
Read more5/7/2024
0
Improving face generation quality and prompt following with synthetic captions
Michail Tarasiou, Stylianos Moschoglou, Jiankang Deng, Stefanos Zafeiriou
Recent advancements in text-to-image generation using diffusion models have significantly improved the quality of generated images and expanded the ability to depict a wide range of objects. However, ensuring that these models adhere closely to the text prompts remains a considerable challenge. This issue is particularly pronounced when trying to generate photorealistic images of humans. Without significant prompt engineering efforts models often produce unrealistic images and typically fail to incorporate the full extent of the prompt information. This limitation can be largely attributed to the nature of captions accompanying the images used in training large scale diffusion models, which typically prioritize contextual information over details related to the person's appearance. In this paper we address this issue by introducing a training-free pipeline designed to generate accurate appearance descriptions from images of people. We apply this method to create approximately 250,000 captions for publicly available face datasets. We then use these synthetic captions to fine-tune a text-to-image diffusion model. Our results demonstrate that this approach significantly improves the model's ability to generate high-quality, realistic human faces and enhances adherence to the given prompts, compared to the baseline model. We share our synthetic captions, pretrained checkpoints and training code.
Read more5/20/2024

0
Caption-Driven Explorations: Aligning Image and Text Embeddings through Human-Inspired Foveated Vision
Dario Zanca, Andrea Zugarini, Simon Dietz, Thomas R. Altstidl, Mark A. Turban Ndjeuha, Leo Schwinn, Bjoern Eskofier
Understanding human attention is crucial for vision science and AI. While many models exist for free-viewing, less is known about task-driven image exploration. To address this, we introduce CapMIT1003, a dataset with captions and click-contingent image explorations, to study human attention during the captioning task. We also present NevaClip, a zero-shot method for predicting visual scanpaths by combining CLIP models with NeVA algorithms. NevaClip generates fixations to align the representations of foveated visual stimuli and captions. The simulated scanpaths outperform existing human attention models in plausibility for captioning and free-viewing tasks. This research enhances the understanding of human attention and advances scanpath prediction models.
Read more8/20/2024
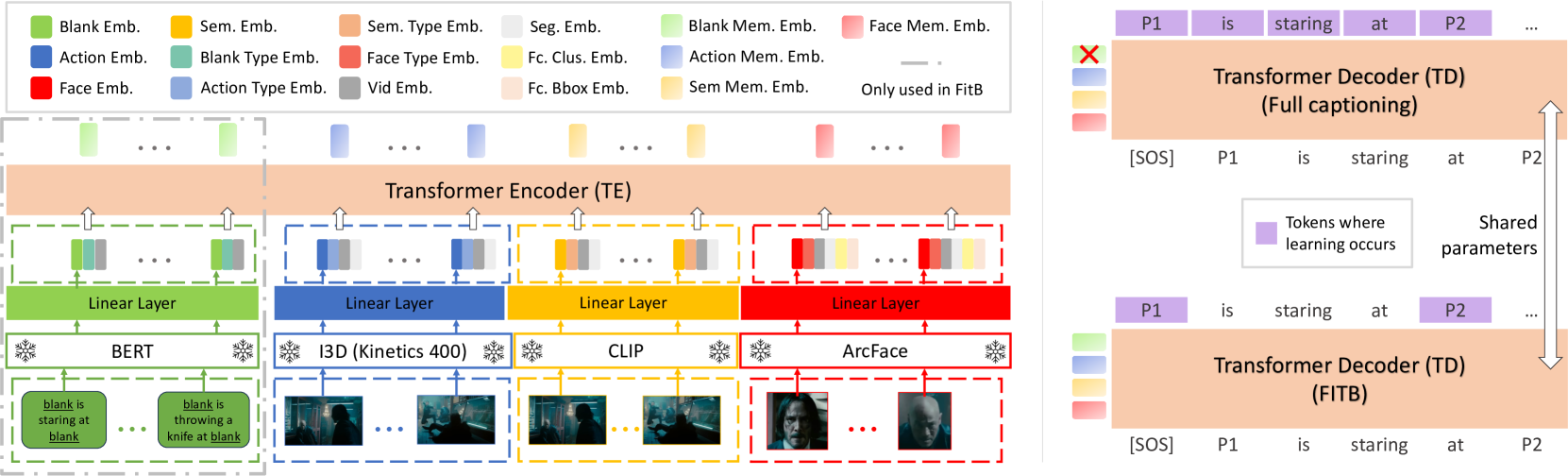
0
MICap: A Unified Model for Identity-aware Movie Descriptions
Haran Raajesh, Naveen Reddy Desanur, Zeeshan Khan, Makarand Tapaswi
Characters are an important aspect of any storyline and identifying and including them in descriptions is necessary for story understanding. While previous work has largely ignored identity and generated captions with someone (anonymized names), recent work formulates id-aware captioning as a fill-in-the-blanks (FITB) task, where, given a caption with blanks, the goal is to predict person id labels. However, to predict captions with ids, a two-stage approach is required: first predict captions with someone, then fill in identities. In this work, we present a new single stage approach that can seamlessly switch between id-aware caption generation or FITB when given a caption with blanks. Our model, Movie-Identity Captioner (MICap), uses a shared auto-regressive decoder that benefits from training with FITB and full-caption generation objectives, while the encoder can benefit from or disregard captions with blanks as input. Another challenge with id-aware captioning is the lack of a metric to capture subtle differences between person ids. To this end, we introduce iSPICE, a caption evaluation metric that focuses on identity tuples created through intermediate scene graphs. We evaluate MICap on Large-Scale Movie Description Challenge (LSMDC), where we show a 4.2% improvement in FITB accuracy, and a 1-2% bump in classic captioning metrics.
Read more5/21/2024