Mind the Interference: Retaining Pre-trained Knowledge in Parameter Efficient Continual Learning of Vision-Language Models

0
Sign in to get full access
Overview
- This paper proposes a novel approach to enable parameter-efficient continual learning of vision-language models while retaining pre-trained knowledge.
- The key idea is to leverage a lightweight module that can be efficiently trained on new tasks without interference with the pre-trained model.
- The approach outperforms existing continual learning methods on various vision-language benchmarks while requiring significantly fewer parameters to be updated.
Plain English Explanation
The paper presents a way to allow vision-language models to continuously learn new tasks and information without forgetting what they already know. This is an important problem, as these models are often pre-trained on large datasets and then need to be adapted to new domains or applications.
The researchers' approach involves adding a lightweight "module" to the pre-trained model. This module can be efficiently trained on new tasks without interfering with the pre-trained knowledge stored in the main model. By isolating the changes to this small module, the pre-trained knowledge is preserved, allowing the model to learn new skills while retaining its original capabilities.
[This relates to the work on disease-informed adaptation of vision-language models and lightweight model pre-training via language guidance.]
The key benefit of this method is that it enables continual learning - the ability to keep learning new things over time - in a parameter-efficient way. The model only needs to update a small part of itself to learn new tasks, rather than having to retrain the entire model from scratch or fine-tune all its parameters. This makes the approach more practical for real-world applications where compute resources may be limited.
Technical Explanation
The paper proposes a continual learning framework for vision-language models called MILE (Memory-Isolated Lightweight Extension). The core idea is to augment a pre-trained vision-language model with a lightweight "extension" module that can be efficiently updated on new tasks without interfering with the pre-trained knowledge stored in the main model.
The extension module consists of a small network that is attached to the pre-trained model's feature backbone. This module learns task-specific parameters that can be trained in isolation, without affecting the pre-trained weights. The authors introduce several techniques to enable this memory-isolated learning, including a distillation loss to transfer knowledge from the pre-trained model to the extension module, and a regularization term to encourage the extension to learn task-specific features orthogonal to the pre-trained representations.
[This builds on prior work on boosting continual learning of vision-language models and advancing cross-domain discriminability in continual learning.]
The authors evaluate MILE on various vision-language benchmarks, including image-text retrieval, visual question answering, and visual commonsense reasoning. They show that MILE outperforms state-of-the-art continual learning methods while requiring significantly fewer parameters to be updated (e.g., only 3-5% of the total model size).
Critical Analysis
The paper presents a compelling approach to enable parameter-efficient continual learning of vision-language models. The key strength is the ability to isolate task-specific learning to a lightweight extension module, preserving the pre-trained knowledge in the main model. This is an important advancement, as it makes continual learning more practical for real-world applications with limited compute resources.
However, the paper does not address potential limitations or explore the broader implications of this approach. For example, it is unclear how the extension module's performance and memory usage scales as the number of tasks grows over time. There may also be concerns around the interpretability and robustness of the learned extension modules.
Additionally, the paper focuses on standard vision-language benchmarks, but it would be interesting to see how MILE performs on more challenging or realistic scenarios, such as adapting to new modalities, domains, or task distributions. Exploring the transfer of the extension modules to new pre-trained models could also be a fruitful direction for future research.
[This relates to the work on distilling implicit multimodal knowledge into large language models and its potential implications for continual learning.]
Overall, the paper presents a valuable contribution to the field of continual learning for vision-language models. However, further research is needed to fully understand the limitations and broader applicability of this approach.
Conclusion
This paper introduces a novel framework for parameter-efficient continual learning of vision-language models. By augmenting a pre-trained model with a lightweight extension module that can be trained in isolation, the approach enables the model to learn new tasks and information without forgetting its pre-trained knowledge.
The key benefit of this approach is its practicality for real-world applications, where compute resources may be limited. The authors demonstrate significant improvements over existing continual learning methods while requiring much fewer parameters to be updated.
While the paper focuses on standard benchmarks, the proposed MILE framework represents an important step forward in making continual learning more accessible and deployable for vision-language models. Future research should explore the scalability, interpretability, and broader applicability of this approach to continue advancing the state of the art in this critical area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mind the Interference: Retaining Pre-trained Knowledge in Parameter Efficient Continual Learning of Vision-Language Models
Longxiang Tang, Zhuotao Tian, Kai Li, Chunming He, Hantao Zhou, Hengshuang Zhao, Xiu Li, Jiaya Jia
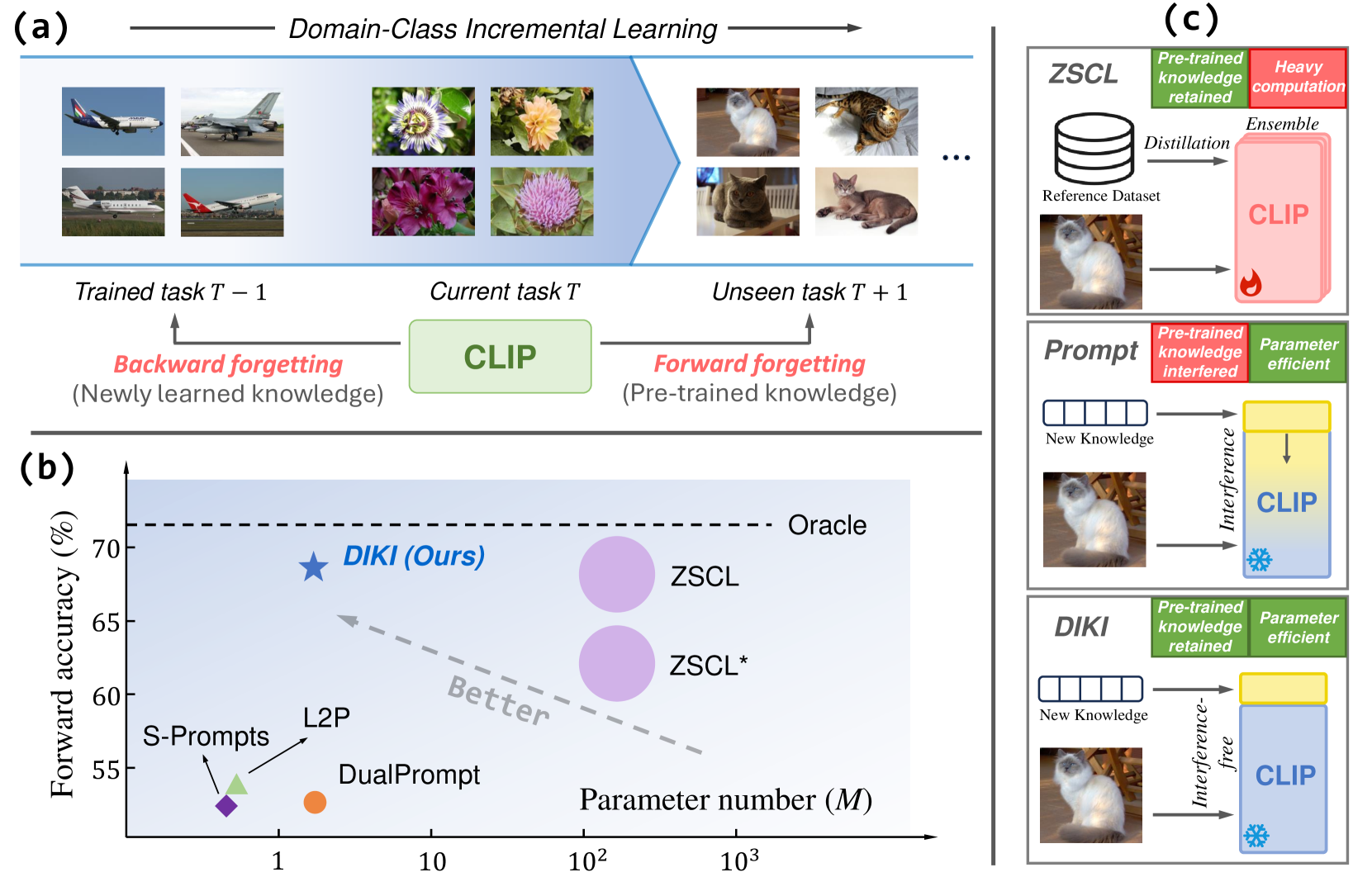
This study addresses the Domain-Class Incremental Learning problem, a realistic but challenging continual learning scenario where both the domain distribution and target classes vary across tasks. To handle these diverse tasks, pre-trained Vision-Language Models (VLMs) are introduced for their strong generalizability. However, this incurs a new problem: the knowledge encoded in the pre-trained VLMs may be disturbed when adapting to new tasks, compromising their inherent zero-shot ability. Existing methods tackle it by tuning VLMs with knowledge distillation on extra datasets, which demands heavy computation overhead. To address this problem efficiently, we propose the Distribution-aware Interference-free Knowledge Integration (DIKI) framework, retaining pre-trained knowledge of VLMs from a perspective of avoiding information interference. Specifically, we design a fully residual mechanism to infuse newly learned knowledge into a frozen backbone, while introducing minimal adverse impacts on pre-trained knowledge. Besides, this residual property enables our distribution-aware integration calibration scheme, explicitly controlling the information implantation process for test data from unseen distributions. Experiments demonstrate that our DIKI surpasses the current state-of-the-art approach using only 0.86% of the trained parameters and requiring substantially less training time. Code is available at: https://github.com/lloongx/DIKI .
Read more7/9/2024
0
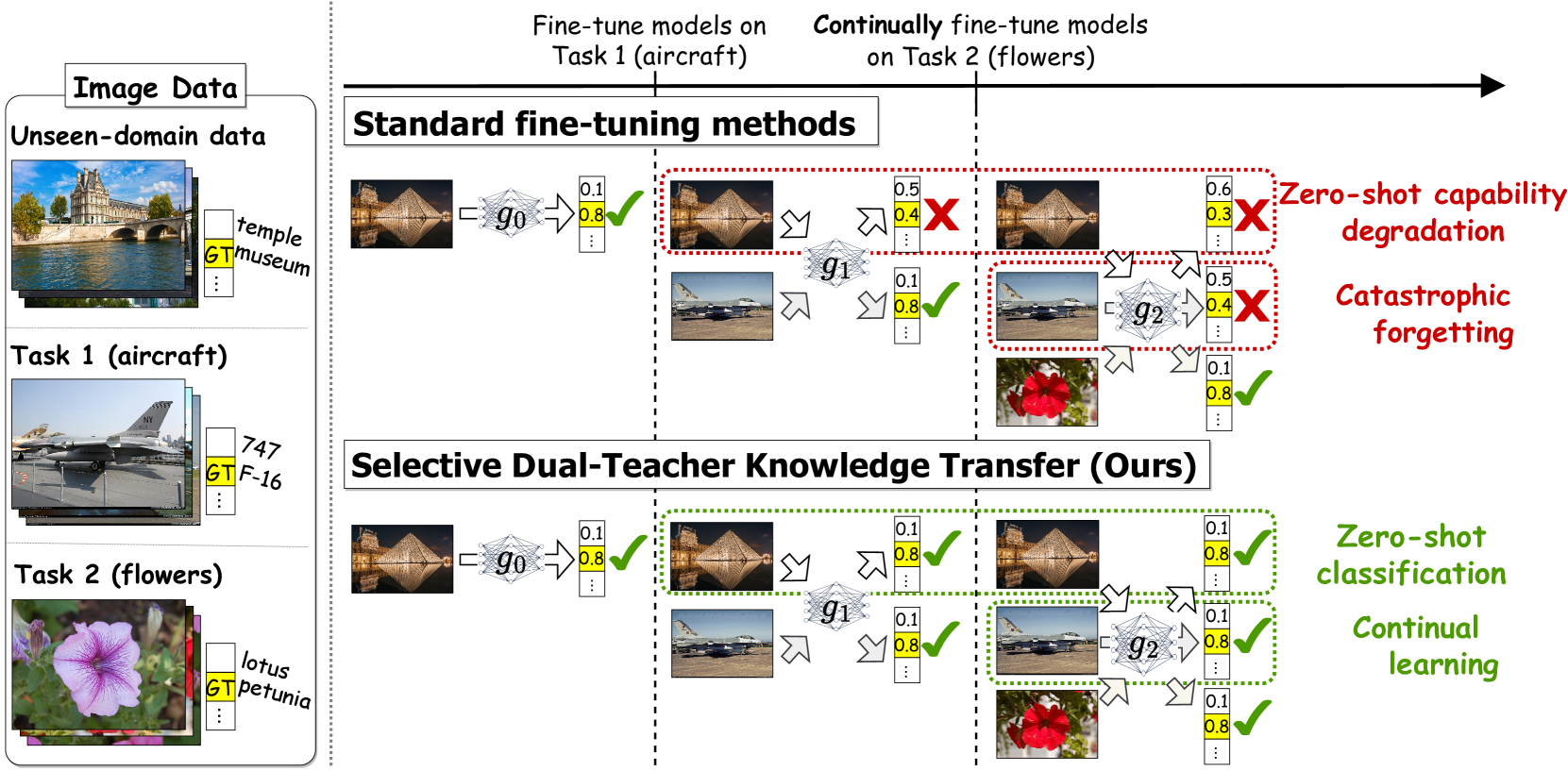
Select and Distill: Selective Dual-Teacher Knowledge Transfer for Continual Learning on Vision-Language Models
Yu-Chu Yu, Chi-Pin Huang, Jr-Jen Chen, Kai-Po Chang, Yung-Hsuan Lai, Fu-En Yang, Yu-Chiang Frank Wang
Large-scale vision-language models (VLMs) have shown a strong zero-shot generalization capability on unseen-domain data. However, adapting pre-trained VLMs to a sequence of downstream tasks often leads to the forgetting of previously learned knowledge and a reduction in zero-shot classification performance. To tackle this problem, we propose a unique Selective Dual-Teacher Knowledge Transfer framework that leverages the most recent fine-tuned and the original pre-trained VLMs as dual teachers to preserve the previously learned knowledge and zero-shot capabilities, respectively. With only access to an unlabeled reference dataset, our proposed framework performs a selective knowledge distillation mechanism by measuring the feature discrepancy from the dual-teacher VLMs. Consequently, our selective dual-teacher knowledge distillation mitigates catastrophic forgetting of previously learned knowledge while preserving the zero-shot capabilities of pre-trained VLMs. Extensive experiments on benchmark datasets demonstrate that our framework is favorable against state-of-the-art continual learning approaches for preventing catastrophic forgetting and zero-shot degradation. Project page: https://chuyu.org/research/snd
Read more7/18/2024

0
VLM-KD: Knowledge Distillation from VLM for Long-Tail Visual Recognition
Zaiwei Zhang, Gregory P. Meyer, Zhichao Lu, Ashish Shrivastava, Avinash Ravichandran, Eric M. Wolff
For visual recognition, knowledge distillation typically involves transferring knowledge from a large, well-trained teacher model to a smaller student model. In this paper, we introduce an effective method to distill knowledge from an off-the-shelf vision-language model (VLM), demonstrating that it provides novel supervision in addition to those from a conventional vision-only teacher model. Our key technical contribution is the development of a framework that generates novel text supervision and distills free-form text into a vision encoder. We showcase the effectiveness of our approach, termed VLM-KD, across various benchmark datasets, showing that it surpasses several state-of-the-art long-tail visual classifiers. To our knowledge, this work is the first to utilize knowledge distillation with text supervision generated by an off-the-shelf VLM and apply it to vanilla randomly initialized vision encoders.
Read more9/2/2024

0
Disease-informed Adaptation of Vision-Language Models
Jiajin Zhang, Ge Wang, Mannudeep K. Kalra, Pingkun Yan
In medical image analysis, the expertise scarcity and the high cost of data annotation limits the development of large artificial intelligence models. This paper investigates the potential of transfer learning with pre-trained vision-language models (VLMs) in this domain. Currently, VLMs still struggle to transfer to the underrepresented diseases with minimal presence and new diseases entirely absent from the pretraining dataset. We argue that effective adaptation of VLMs hinges on the nuanced representation learning of disease concepts. By capitalizing on the joint visual-linguistic capabilities of VLMs, we introduce disease-informed contextual prompting in a novel disease prototype learning framework. This approach enables VLMs to grasp the concepts of new disease effectively and efficiently, even with limited data. Extensive experiments across multiple image modalities showcase notable enhancements in performance compared to existing techniques.
Read more5/27/2024