Distilling Implicit Multimodal Knowledge into LLMs for Zero-Resource Dialogue Generation

0
Sign in to get full access
Overview
- This paper explores a novel approach to distilling implicit multimodal knowledge into large language models (LLMs) for zero-resource dialogue generation.
- The researchers aim to enhance the dialogue generation capabilities of LLMs by leveraging the rich, multimodal knowledge that humans possess but may not be explicitly expressed in text-only training data.
- The proposed method involves a knowledge distillation process that transfers this implicit multimodal knowledge from specialized models into the LLM, enabling it to generate more natural and engaging dialogues without requiring any additional task-specific training data.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, these models are typically trained on text-only data, which means they may lack the rich, multimodal knowledge that humans acquire through their senses and experiences.
This paper presents a way to address this limitation by "distilling" implicit multimodal knowledge into LLMs. The researchers used specialized models that were trained on multimodal data, such as images and videos, to capture the underlying connections between visual, auditory, and textual information. They then transferred this knowledge into the LLM, effectively teaching it to understand and reason about the world in a more holistic, human-like manner.
The key benefit of this approach is that it allows the LLM to generate more natural and engaging dialogues, even in situations where no task-specific training data is available. By tapping into the implicit multimodal knowledge, the LLM can draw upon a deeper understanding of the world to produce more contextually appropriate and coherent responses.
This could be particularly useful for applications like zero-resource dialogue generation, where the system needs to engage in meaningful conversations without any prior training on the specific domain or task. By leveraging the distilled multimodal knowledge, the LLM can adapt and respond more flexibly, leading to more natural and enjoyable interactions.
Technical Explanation
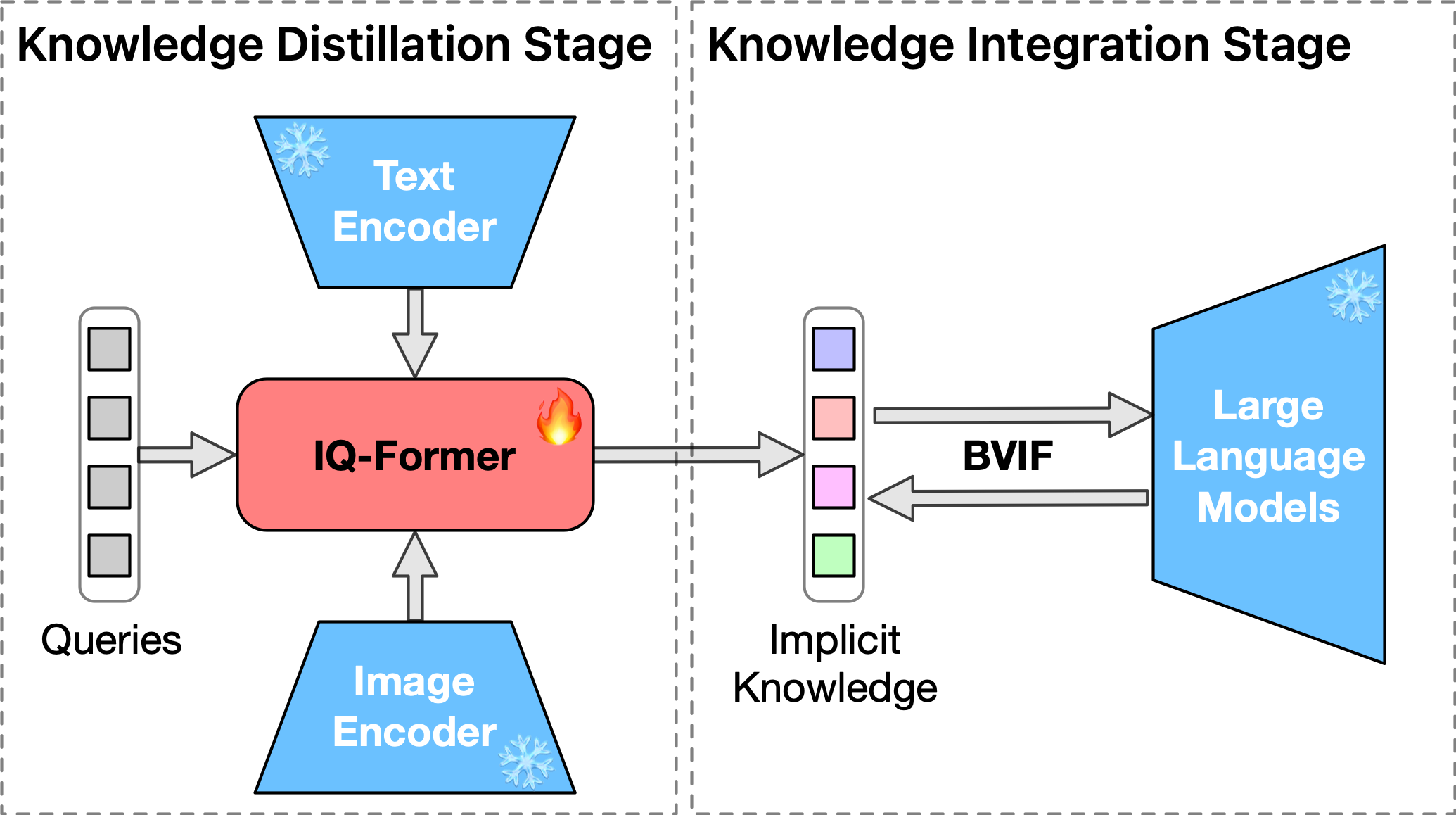
The researchers propose a knowledge distillation approach to transfer implicit multimodal knowledge from specialized models into a large language model (LLM). They start by training separate models on different modalities, such as text-only and multimodal data. These specialized models are then used to guide the learning of the LLM, using techniques like knowledge distillation and query rewriting.
The key steps in the proposed method are:
- Multimodal Model Training: The researchers train separate models on text-only and multimodal data, capturing the unique knowledge from each domain.
- Knowledge Distillation: They then use the specialized models to guide the learning of the LLM, transferring the implicit multimodal knowledge into the language model.
- Zero-Resource Dialogue Generation: The enhanced LLM can now generate more natural and engaging dialogues, even in scenarios where no task-specific training data is available.
The experiments conducted in the paper demonstrate the effectiveness of this approach, showing that the LLM enhanced with multimodal knowledge outperforms baseline models in various dialogue generation tasks.
Critical Analysis
The researchers acknowledge several limitations and areas for future work in their paper. While the proposed method effectively distills multimodal knowledge into the LLM, it relies on the availability of specialized models trained on diverse multimodal data, which may not always be feasible.
Additionally, the paper does not explore the robustness of the distilled knowledge or how it might adapt to different dialogue scenarios. There could be concerns about the potential for biases or inconsistencies to be introduced during the knowledge transfer process.
Further research could investigate techniques to extract and consolidate multimodal knowledge from multiple sources, as well as mechanisms to ensure the coherence and reliability of the distilled knowledge within the LLM. Exploring the interpretability and explainability of the multimodal reasoning process could also be a valuable avenue for future work.
Conclusion
This paper presents a novel approach to enhancing the dialogue generation capabilities of large language models by distilling implicit multimodal knowledge into the model. By leveraging specialized models trained on diverse data sources, the researchers demonstrate how LLMs can be imbued with richer, more human-like understanding of the world, leading to more natural and engaging dialogues, even in zero-resource scenarios.
The proposed method offers a promising direction for advancing the state-of-the-art in language modeling and dialogue systems, with potential applications in a wide range of domains, from chatbots and virtual assistants to educational and therapeutic tools. As the field of AI continues to evolve, techniques like this that bridge the gap between textual and multimodal knowledge will be crucial for developing truly intelligent and adaptive systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Distilling Implicit Multimodal Knowledge into LLMs for Zero-Resource Dialogue Generation
Bo Zhang, Hui Ma, Jian Ding, Jian Wang, Bo Xu, Hongfei Lin
Integrating multimodal knowledge into large language models (LLMs) represents a significant advancement in dialogue generation capabilities. However, the effective incorporation of such knowledge in zero-resource scenarios remains a substantial challenge due to the scarcity of diverse, high-quality dialogue datasets. To address this, we propose the Visual Implicit Knowledge Distillation Framework (VIKDF), an innovative approach aimed at enhancing LLMs for enriched dialogue generation in zero-resource contexts by leveraging implicit multimodal knowledge. VIKDF comprises two main stages: knowledge distillation, using an Implicit Query Transformer to extract and encode visual implicit knowledge from image-text pairs into knowledge vectors; and knowledge integration, employing a novel Bidirectional Variational Information Fusion technique to seamlessly integrate these distilled vectors into LLMs. This enables the LLMs to generate dialogues that are not only coherent and engaging but also exhibit a deep understanding of the context through implicit multimodal cues, effectively overcoming the limitations of zero-resource scenarios. Our extensive experimentation across two dialogue datasets shows that VIKDF outperforms existing state-of-the-art models in generating high-quality dialogues. The code will be publicly available following acceptance.
Read more5/17/2024

0
VLM-KD: Knowledge Distillation from VLM for Long-Tail Visual Recognition
Zaiwei Zhang, Gregory P. Meyer, Zhichao Lu, Ashish Shrivastava, Avinash Ravichandran, Eric M. Wolff
For visual recognition, knowledge distillation typically involves transferring knowledge from a large, well-trained teacher model to a smaller student model. In this paper, we introduce an effective method to distill knowledge from an off-the-shelf vision-language model (VLM), demonstrating that it provides novel supervision in addition to those from a conventional vision-only teacher model. Our key technical contribution is the development of a framework that generates novel text supervision and distills free-form text into a vision encoder. We showcase the effectiveness of our approach, termed VLM-KD, across various benchmark datasets, showing that it surpasses several state-of-the-art long-tail visual classifiers. To our knowledge, this work is the first to utilize knowledge distillation with text supervision generated by an off-the-shelf VLM and apply it to vanilla randomly initialized vision encoders.
Read more9/2/2024

0
LLAVADI: What Matters For Multimodal Large Language Models Distillation
Shilin Xu, Xiangtai Li, Haobo Yuan, Lu Qi, Yunhai Tong, Ming-Hsuan Yang
The recent surge in Multimodal Large Language Models (MLLMs) has showcased their remarkable potential for achieving generalized intelligence by integrating visual understanding into Large Language Models.Nevertheless, the sheer model size of MLLMs leads to substantial memory and computational demands that hinder their widespread deployment. In this work, we do not propose a new efficient model structure or train small-scale MLLMs from scratch. Instead, we focus on what matters for training small-scale MLLMs through knowledge distillation, which is the first step from the multimodal distillation perspective. Our extensive studies involve training strategies, model choices, and distillation algorithms in the knowledge distillation process. These results show that joint alignment for both tokens and logit alignment plays critical roles in teacher-student frameworks. In addition, we draw a series of intriguing observations from this study. By evaluating different benchmarks and proper strategy, even a 2.7B small-scale model can perform on par with larger models with 7B or 13B parameters. Our code and models will be publicly available for further research.
Read more7/30/2024
💬
0
Multimodal Dialog Systems with Dual Knowledge-enhanced Generative Pretrained Language Model
Xiaolin Chen, Xuemeng Song, Liqiang Jing, Shuo Li, Linmei Hu, Liqiang Nie
Text response generation for multimodal task-oriented dialog systems, which aims to generate the proper text response given the multimodal context, is an essential yet challenging task. Although existing efforts have achieved compelling success, they still suffer from two pivotal limitations: 1) overlook the benefit of generative pre-training, and 2) ignore the textual context related knowledge. To address these limitations, we propose a novel dual knowledge-enhanced generative pretrained language model for multimodal task-oriented dialog systems (DKMD), consisting of three key components: dual knowledge selection, dual knowledge-enhanced context learning, and knowledge-enhanced response generation. To be specific, the dual knowledge selection component aims to select the related knowledge according to both textual and visual modalities of the given context. Thereafter, the dual knowledge-enhanced context learning component targets seamlessly integrating the selected knowledge into the multimodal context learning from both global and local perspectives, where the cross-modal semantic relation is also explored. Moreover, the knowledge-enhanced response generation component comprises a revised BART decoder, where an additional dot-product knowledge-decoder attention sub-layer is introduced for explicitly utilizing the knowledge to advance the text response generation. Extensive experiments on a public dataset verify the superiority of the proposed DKMD over state-of-the-art competitors.
Read more5/14/2024