MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
2404.06395
3
23
Abstract
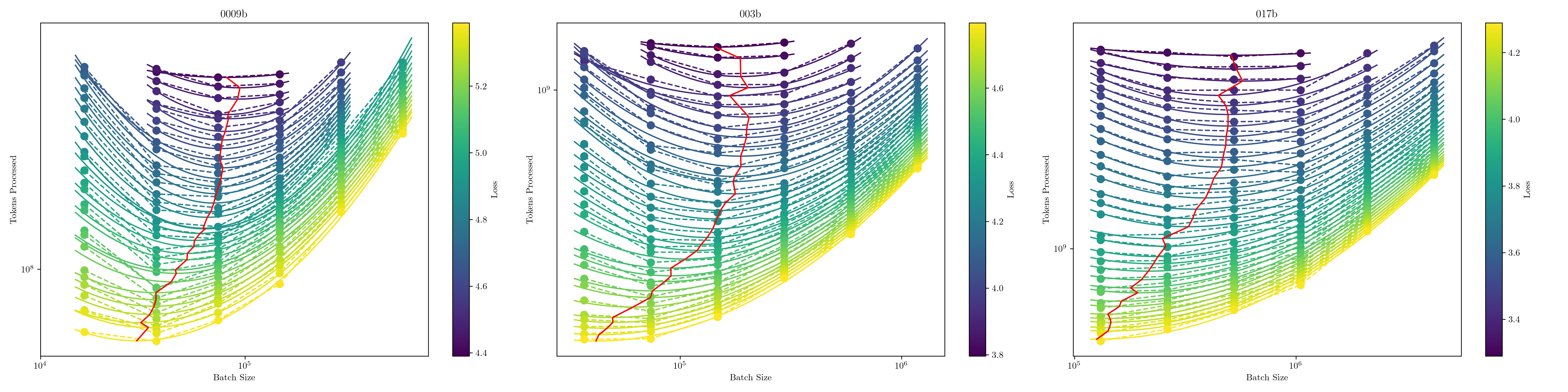
The burgeoning interest in developing Large Language Models (LLMs) with up to trillion parameters has been met with concerns regarding resource efficiency and practical expense, particularly given the immense cost of experimentation. This scenario underscores the importance of exploring the potential of Small Language Models (SLMs) as a resource-efficient alternative. In this context, we introduce MiniCPM, specifically the 1.2B and 2.4B non-embedding parameter variants, not only excel in their respective categories but also demonstrate capabilities on par with 7B-13B LLMs. While focusing on SLMs, our approach exhibits scalability in both model and data dimensions for future LLM research. Regarding model scaling, we employ extensive model wind tunnel experiments for stable and optimal scaling. For data scaling, we introduce a Warmup-Stable-Decay (WSD) learning rate scheduler (LRS), conducive to continuous training and domain adaptation. We present an in-depth analysis of the intriguing training dynamics that occurred in the WSD LRS. With WSD LRS, we are now able to efficiently study data-model scaling law without extensive retraining experiments on both axes of model and data, from which we derive the much higher compute optimal data-model ratio than Chinchilla Optimal. Additionally, we introduce MiniCPM family, including MiniCPM-DPO, MiniCPM-MoE and MiniCPM-128K, whose excellent performance further cementing MiniCPM's foundation in diverse SLM applications. MiniCPM models are available publicly at https://github.com/OpenBMB/MiniCPM .
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces MiniCPM, a new approach for training small language models to unlock their potential.
- The researchers developed scalable training strategies to efficiently train compact models without compromising performance.
- MiniCPM models demonstrate strong results on a variety of benchmarks, showcasing the viability of small, cost-effective language models.
Plain English Explanation
The researchers behind this paper have developed a new way to train small language models, called MiniCPM. Language models are large artificial intelligence systems that can understand and generate human-like text. They are typically very large and expensive to train, which limits their accessibility.
The goal of this work was to show that small, compact language models can still perform well if trained effectively. The researchers developed special training strategies to efficiently train these smaller models without sacrificing their capabilities. Through extensive experiments, they demonstrated that MiniCPM models can achieve strong results on a range of benchmarks, rivaling the performance of much larger and more resource-intensive models.
This is an important advancement because it opens the door for more affordable and accessible language AI systems. Small models require less computing power and are cheaper to develop, allowing a wider range of organizations and individuals to take advantage of this technology. By unleashing the potential of small language models, this research could enable new applications and wider adoption of natural language AI.
Technical Explanation
The core innovation introduced in this paper is the MiniCPM framework, which allows for the scalable training of small language models. The researchers developed specialized training techniques, including layerwise training, progressive scaling, and selective parameter sharing, to efficiently learn compact model architectures.
Through extensive "model wind tunnel" experiments, the team evaluated MiniCPM models of varying sizes on a diverse set of language understanding and generation benchmarks. The results show that MiniCPM models are able to achieve strong performance, often matching or exceeding the capabilities of much larger language models.
Notably, the researchers found that MiniCPM models exhibit favorable scaling properties, where doubling the model size leads to consistent performance improvements. This suggests that the training strategies are effective at extracting maximal capability from small-scale models.
The paper also investigates the role of model depth and width, demonstrating that depth is a more critical factor than width for achieving high performance in compact language models. This provides valuable insights for designing efficient model architectures.
Critical Analysis
The researchers acknowledge several limitations and areas for future work. For example, they note that MiniCPM models may struggle with tasks that require extensive world knowledge or reasoning abilities, as their compact nature inherently limits the information they can store.
Additionally, the paper does not explore the performance of MiniCPM models on real-world applications, such as dialogue systems or content generation. Further research is needed to understand how these small models would fare in practical, end-to-end deployments.
Another potential concern is the environmental impact of training numerous small models, as the cumulative energy consumption could still be significant. The paper does not address the carbon footprint or sustainability implications of this approach.
Despite these caveats, the MiniCPM framework represents an important step forward in making language AI more accessible and scalable. By unlocking the potential of small models, this work paves the way for more affordable and widespread adoption of natural language processing technologies.
Conclusion
This paper introduces MiniCPM, a novel approach for training small language models that can rival the performance of much larger and more resource-intensive systems. Through innovative training strategies, the researchers were able to extract maximal capability from compact model architectures, opening up new possibilities for cost-effective and accessible natural language AI.
The strong results demonstrated on a range of benchmarks suggest that MiniCPM could enable a new generation of language models that are more widely deployable and impactful. As the field of natural language processing continues to evolve, this research represents an important contribution towards making advanced language technologies more attainable and scalable.
Related Papers
🔮
nanoLM: an Affordable LLM Pre-training Benchmark via Accurate Loss Prediction across Scales
Yiqun Yao, Siqi fan, Xiusheng Huang, Xuezhi Fang, Xiang Li, Ziyi Ni, Xin Jiang, Xuying Meng, Peng Han, Shuo Shang, Kang Liu, Aixin Sun, Yequan Wang
0
0
As language models scale up, it becomes increasingly expensive to verify research ideas because conclusions on small models do not trivially transfer to large ones. A possible solution is to establish a generic system that accurately predicts certain metrics for large models without training them. Existing scaling laws require hyperparameter search on the largest models, limiting their predicative capability. In this paper, we present an approach (namely {mu}Scaling) to predict the pre-training loss, based on our observations that Maximal Update Parametrization ({mu}P) enables accurate fitting of scaling laws close to common loss basins in hyperparameter space. With {mu}Scaling, different model designs can be compared on large scales by training only their smaller counterparts. Further, we introduce nanoLM: an affordable LLM pre-training benchmark that facilitates this new research paradigm. With around 14% of the one-time pre-training cost, we can accurately forecast the loss for models up to 52B. Our goal with nanoLM is to empower researchers with limited resources to reach meaningful conclusions on large models. We also aspire for our benchmark to serve as a bridge between the academic community and the industry. Code for {mu}Scaling is available at https://github.com/cofe-ai/Mu-scaling. Code for nanoLLM will be available later.
4/9/2024

SambaLingo: Teaching Large Language Models New Languages
Zoltan Csaki, Bo Li, Jonathan Li, Qiantong Xu, Pian Pawakapan, Leon Zhang, Yun Du, Hengyu Zhao, Changran Hu, Urmish Thakker
0
0
Despite the widespread availability of LLMs, there remains a substantial gap in their capabilities and availability across diverse languages. One approach to address these issues has been to take an existing pre-trained LLM and continue to train it on new languages. While prior works have experimented with language adaptation, many questions around best practices and methodology have not been covered. In this paper, we present a comprehensive investigation into the adaptation of LLMs to new languages. Our study covers the key components in this process, including vocabulary extension, direct preference optimization and the data scarcity problem for human alignment in low-resource languages. We scale these experiments across 9 languages and 2 parameter scales (7B and 70B). We compare our models against Llama 2, Aya-101, XGLM, BLOOM and existing language experts, outperforming all prior published baselines. Additionally, all evaluation code and checkpoints are made public to facilitate future research.
4/10/2024
Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model
Xinrun Du, Zhouliang Yu, Songyang Gao, Ding Pan, Yuyang Cheng, Ziyang Ma, Ruibin Yuan, Xingwei Qu, Jiaheng Liu, Tianyu Zheng, Xinchen Luo, Guorui Zhou, Binhang Yuan, Wenhu Chen, Jie Fu, Ge Zhang
0
0
In this study, we introduce CT-LLM, a 2B large language model (LLM) that illustrates a pivotal shift towards prioritizing the Chinese language in developing LLMs. Uniquely initiated from scratch, CT-LLM diverges from the conventional methodology by primarily incorporating Chinese textual data, utilizing an extensive corpus of 1,200 billion tokens, including 800 billion Chinese tokens, 300 billion English tokens, and 100 billion code tokens. This strategic composition facilitates the model's exceptional proficiency in understanding and processing Chinese, a capability further enhanced through alignment techniques. Demonstrating remarkable performance on the CHC-Bench, CT-LLM excels in Chinese language tasks, and showcases its adeptness in English through SFT. This research challenges the prevailing paradigm of training LLMs predominantly on English corpora and then adapting them to other languages, broadening the horizons for LLM training methodologies. By open-sourcing the full process of training a Chinese LLM, including a detailed data processing procedure with the obtained Massive Appropriate Pretraining Chinese Corpus (MAP-CC), a well-chosen multidisciplinary Chinese Hard Case Benchmark (CHC-Bench), and the 2B-size Chinese Tiny LLM (CT-LLM), we aim to foster further exploration and innovation in both academia and industry, paving the way for more inclusive and versatile language models.
4/10/2024
💬
Tiny Titans: Can Smaller Large Language Models Punch Above Their Weight in the Real World for Meeting Summarization?
Xue-Yong Fu, Md Tahmid Rahman Laskar, Elena Khasanova, Cheng Chen, Shashi Bhushan TN
0
0
Large Language Models (LLMs) have demonstrated impressive capabilities to solve a wide range of tasks without being explicitly fine-tuned on task-specific datasets. However, deploying LLMs in the real world is not trivial, as it requires substantial computing resources. In this paper, we investigate whether smaller, compact LLMs are a good alternative to the comparatively Larger LLMs2 to address significant costs associated with utilizing LLMs in the real world. In this regard, we study the meeting summarization task in a real-world industrial environment and conduct extensive experiments by comparing the performance of fine-tuned compact LLMs (e.g., FLAN-T5, TinyLLaMA, LiteLLaMA) with zero-shot larger LLMs (e.g., LLaMA-2, GPT-3.5, PaLM-2). We observe that most smaller LLMs, even after fine-tuning, fail to outperform larger zero-shot LLMs in meeting summarization datasets. However, a notable exception is FLAN-T5 (780M parameters), which performs on par or even better than many zero-shot Larger LLMs (from 7B to above 70B parameters), while being significantly smaller. This makes compact LLMs like FLAN-T5 a suitable cost-efficient solution for real-world industrial deployment.
4/16/2024