Tiny Titans: Can Smaller Large Language Models Punch Above Their Weight in the Real World for Meeting Summarization?
2402.00841
1
0
💬
Abstract
Large Language Models (LLMs) have demonstrated impressive capabilities to solve a wide range of tasks without being explicitly fine-tuned on task-specific datasets. However, deploying LLMs in the real world is not trivial, as it requires substantial computing resources. In this paper, we investigate whether smaller, compact LLMs are a good alternative to the comparatively Larger LLMs2 to address significant costs associated with utilizing LLMs in the real world. In this regard, we study the meeting summarization task in a real-world industrial environment and conduct extensive experiments by comparing the performance of fine-tuned compact LLMs (e.g., FLAN-T5, TinyLLaMA, LiteLLaMA) with zero-shot larger LLMs (e.g., LLaMA-2, GPT-3.5, PaLM-2). We observe that most smaller LLMs, even after fine-tuning, fail to outperform larger zero-shot LLMs in meeting summarization datasets. However, a notable exception is FLAN-T5 (780M parameters), which performs on par or even better than many zero-shot Larger LLMs (from 7B to above 70B parameters), while being significantly smaller. This makes compact LLMs like FLAN-T5 a suitable cost-efficient solution for real-world industrial deployment.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large Language Models (LLMs) have shown impressive abilities to solve a wide range of tasks without being specifically trained on those tasks.
- However, using LLMs in real-world applications can be challenging due to their high computational requirements.
- This paper investigates whether smaller, more compact LLMs could be a cost-effective alternative to larger LLMs for real-world deployment, focusing on the task of meeting summarization.
Plain English Explanation
Large language models (LLMs) are artificial intelligence systems that can perform a wide variety of tasks, like generating human-like text, answering questions, and even writing code. These LLMs have become incredibly capable, often matching or exceeding human performance on many tasks. This paper explores whether smaller, more efficient LLMs could be a good replacement for the larger, more resource-intensive LLMs that are currently used.
The key idea is that the bigger LLMs, while highly capable, require a lot of computing power and resources to run. This can make them difficult and expensive to use in real-world applications, like in a company or organization. The researchers wanted to see if smaller, more compact LLMs could provide similar performance at a lower cost.
To test this, they focused on the task of summarizing meeting transcripts - taking a long record of a meeting and boiling it down to the key points. They compared the performance of several smaller, fine-tuned LLMs (like FLAN-T5 and TinyLLaMA) against larger, zero-shot LLMs (like GPT-3.5 and PaLM-2) on this task. Interestingly, they found that one of the smaller models, FLAN-T5, was able to perform just as well or even better than the larger LLMs, while being significantly smaller and more efficient. This suggests that compact LLMs like FLAN-T5 could be a good, cost-effective solution for real-world applications that need to use large language models.
Technical Explanation
The paper compares the performance of fine-tuned compact LLMs (e.g., FLAN-T5, TinyLLaMA, LiteLLaMA) against zero-shot larger LLMs (e.g., LLaMA-2, GPT-3.5, PaLM-2) on the task of meeting summarization in a real-world industrial setting.
The researchers conducted extensive experiments to evaluate the different models. They found that most of the smaller, fine-tuned LLMs failed to outperform the larger, zero-shot LLMs on meeting summarization datasets. However, an exception was FLAN-T5, a 780 million parameter model, which performed on par or even better than many of the larger LLMs (which ranged from 7 billion to over 70 billion parameters).
This suggests that compact LLMs like FLAN-T5 could be a suitable, cost-efficient solution for real-world industrial deployment, as they can match the performance of much larger LLMs while requiring significantly fewer computational resources. The paper highlights the potential of these smaller models to address the substantial costs associated with utilizing large language models in practical applications.
Critical Analysis
The paper provides a valuable exploration of the trade-offs between larger and smaller LLMs for real-world deployment. The researchers acknowledge that their findings are limited to the specific task of meeting summarization, and further research would be needed to generalize the results to other domains.
Additionally, the paper does not delve deeply into the underlying reasons why FLAN-T5 was able to outperform the larger LLMs. It would be interesting to understand the architectural or training differences that contribute to this performance gap.
While the paper demonstrates the potential of compact LLMs, it also highlights the need for continued research and development in this area to further improve the capabilities of smaller models and address their limitations. As the use of large language models becomes more widespread, finding cost-effective solutions will be crucial for enabling their real-world adoption.
Conclusion
This paper explores the potential of smaller, more compact LLMs as a cost-effective alternative to larger LLMs for real-world industrial deployment. The researchers focus on the task of meeting summarization and find that a compact model, FLAN-T5, is able to match or even exceed the performance of much larger LLMs, while requiring significantly fewer computational resources.
These findings suggest that compact LLMs could be a suitable solution for organizations and businesses that want to leverage the capabilities of large language models but are constrained by the high costs and resource requirements. The paper highlights the importance of continued research in this area to further improve the capabilities of smaller models and make them more viable for a wider range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
A Zero-shot and Few-shot Study of Instruction-Finetuned Large Language Models Applied to Clinical and Biomedical Tasks
Yanis Labrak, Mickael Rouvier, Richard Dufour
0
0
We evaluate four state-of-the-art instruction-tuned large language models (LLMs) -- ChatGPT, Flan-T5 UL2, Tk-Instruct, and Alpaca -- on a set of 13 real-world clinical and biomedical natural language processing (NLP) tasks in English, such as named-entity recognition (NER), question-answering (QA), relation extraction (RE), etc. Our overall results demonstrate that the evaluated LLMs begin to approach performance of state-of-the-art models in zero- and few-shot scenarios for most tasks, and particularly well for the QA task, even though they have never seen examples from these tasks before. However, we observed that the classification and RE tasks perform below what can be achieved with a specifically trained model for the medical field, such as PubMedBERT. Finally, we noted that no LLM outperforms all the others on all the studied tasks, with some models being better suited for certain tasks than others.
4/30/2024
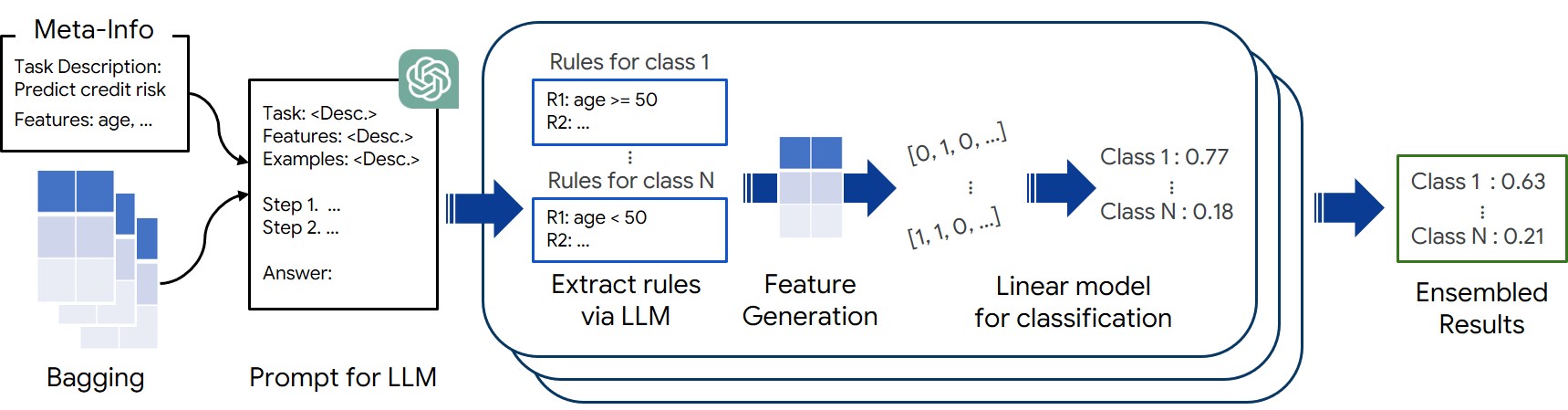
Large Language Models Can Automatically Engineer Features for Few-Shot Tabular Learning
Sungwon Han, Jinsung Yoon, Sercan O Arik, Tomas Pfister
0
0
Large Language Models (LLMs), with their remarkable ability to tackle challenging and unseen reasoning problems, hold immense potential for tabular learning, that is vital for many real-world applications. In this paper, we propose a novel in-context learning framework, FeatLLM, which employs LLMs as feature engineers to produce an input data set that is optimally suited for tabular predictions. The generated features are used to infer class likelihood with a simple downstream machine learning model, such as linear regression and yields high performance few-shot learning. The proposed FeatLLM framework only uses this simple predictive model with the discovered features at inference time. Compared to existing LLM-based approaches, FeatLLM eliminates the need to send queries to the LLM for each sample at inference time. Moreover, it merely requires API-level access to LLMs, and overcomes prompt size limitations. As demonstrated across numerous tabular datasets from a wide range of domains, FeatLLM generates high-quality rules, significantly (10% on average) outperforming alternatives such as TabLLM and STUNT.
5/7/2024

A Systematic Evaluation of Large Language Models for Natural Language Generation Tasks
Xuanfan Ni, Piji Li
0
0
Recent efforts have evaluated large language models (LLMs) in areas such as commonsense reasoning, mathematical reasoning, and code generation. However, to the best of our knowledge, no work has specifically investigated the performance of LLMs in natural language generation (NLG) tasks, a pivotal criterion for determining model excellence. Thus, this paper conducts a comprehensive evaluation of well-known and high-performing LLMs, namely ChatGPT, ChatGLM, T5-based models, LLaMA-based models, and Pythia-based models, in the context of NLG tasks. We select English and Chinese datasets encompassing Dialogue Generation and Text Summarization. Moreover, we propose a common evaluation setting that incorporates input templates and post-processing strategies. Our study reports both automatic results, accompanied by a detailed analysis.
5/17/2024
🐍
Tele-FLM Technical Report
Xiang Li, Yiqun Yao, Xin Jiang, Xuezhi Fang, Chao Wang, Xinzhang Liu, Zihan Wang, Yu Zhao, Xin Wang, Yuyao Huang, Shuangyong Song, Yongxiang Li, Zheng Zhang, Bo Zhao, Aixin Sun, Yequan Wang, Zhongjiang He, Zhongyuan Wang, Xuelong Li, Tiejun Huang
0
0
Large language models (LLMs) have showcased profound capabilities in language understanding and generation, facilitating a wide array of applications. However, there is a notable paucity of detailed, open-sourced methodologies on efficiently scaling LLMs beyond 50 billion parameters with minimum trial-and-error cost and computational resources. In this report, we introduce Tele-FLM (aka FLM-2), a 52B open-sourced multilingual large language model that features a stable, efficient pre-training paradigm and enhanced factual judgment capabilities. Tele-FLM demonstrates superior multilingual language modeling abilities, measured by BPB on textual corpus. Besides, in both English and Chinese foundation model evaluation, it is comparable to strong open-sourced models that involve larger pre-training FLOPs, such as Llama2-70B and DeepSeek-67B. In addition to the model weights, we share the core designs, engineering practices, and training details, which we expect to benefit both the academic and industrial communities.
4/26/2024