Minimax and Communication-Efficient Distributed Best Subset Selection with Oracle Property

0

Sign in to get full access
Overview
- The paper introduces a communication-efficient distributed algorithm for best subset selection with oracle property.
- The algorithm aims to identify the optimal subset of features from a high-dimensional dataset in a distributed setting.
- It provides theoretical guarantees on the performance and communication complexity of the proposed method.
Plain English Explanation
The paper presents a new approach for selecting the best subset of features from a large dataset in a distributed computing environment. This is an important problem in high-dimensional data analysis and machine learning.
The key idea is to design a distributed algorithm that can identify the optimal subset of features efficiently, while minimizing the amount of communication between the different computing nodes. This is important because in a distributed setting, communication can be a bottleneck and can limit the scalability of the algorithm.
The proposed algorithm has several desirable properties:
- Oracle property: The selected subset of features is guaranteed to have the same performance as the optimal subset that would be selected if the full dataset was available on a single machine.
- Communication-efficiency: The algorithm minimizes the amount of communication required between the computing nodes, making it scalable to large datasets.
- Theoretical guarantees: The paper provides theoretical analysis to show that the algorithm achieves near-optimal performance in terms of both accuracy and communication complexity.
By addressing these challenges, the proposed method can be useful for a wide range of applications that involve high-dimensional data analysis and distributed learning.
Technical Explanation
The paper presents a minimax-optimal and communication-efficient distributed algorithm for best subset selection. The problem setting involves a high-dimensional dataset that is distributed across multiple computing nodes, and the goal is to identify the optimal subset of features that best explains the target variable.
The key technical contributions of the paper are:
-
Distributed Algorithm: The authors propose a distributed algorithm that iteratively selects the best subset of features by coordinating among the computing nodes. The algorithm uses a novel communication protocol to minimize the amount of data transferred between nodes.
-
Theoretical Analysis: The paper provides a thorough theoretical analysis of the proposed algorithm. It proves that the algorithm achieves the oracle property, meaning the selected subset of features performs as well as if the full dataset was available on a single machine. The authors also derive tight bounds on the communication complexity of the algorithm.
-
Experimental Evaluation: The authors evaluate the proposed algorithm on both synthetic and real-world datasets, and show that it outperforms existing distributed best subset selection methods in terms of both accuracy and communication efficiency.
Critical Analysis
The paper presents a well-designed and theoretically-grounded approach to the challenging problem of distributed best subset selection. The authors have carefully addressed several important practical considerations, such as communication efficiency and scalability, which are crucial for the real-world deployment of such algorithms.
One potential limitation of the approach is that it assumes the dataset is distributed across computing nodes in a specific way (i.e., each node has a random subset of the features). In practice, the distribution of the data across nodes may not always follow this assumption, and the algorithm's performance may degrade in such cases.
Additionally, the paper focuses on the asymptotic performance of the algorithm, but does not provide much guidance on the practical considerations for deploying the algorithm in real-world scenarios, such as the choice of hyperparameters or the impact of dataset size and dimensionality on the algorithm's performance.
Conclusion
The paper introduces a communication-efficient distributed algorithm for best subset selection that provides theoretical guarantees on its performance. By addressing the challenges of high-dimensional data analysis and distributed learning, the proposed method has the potential to be widely applicable in fields such as feature engineering, model selection, and distributed optimization. The authors have provided a solid theoretical foundation and experimental results to support the efficacy of their approach, but further research may be needed to address practical deployment considerations and expand the scope of the algorithm to handle more general data distributions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Minimax and Communication-Efficient Distributed Best Subset Selection with Oracle Property
Jingguo Lan, Hongmei Lin, Xueqin Wang
The explosion of large-scale data in fields such as finance, e-commerce, and social media has outstripped the processing capabilities of single-machine systems, driving the need for distributed statistical inference methods. Traditional approaches to distributed inference often struggle with achieving true sparsity in high-dimensional datasets and involve high computational costs. We propose a novel, two-stage, distributed best subset selection algorithm to address these issues. Our approach starts by efficiently estimating the active set while adhering to the $ell_0$ norm-constrained surrogate likelihood function, effectively reducing dimensionality and isolating key variables. A refined estimation within the active set follows, ensuring sparse estimates and matching the minimax $ell_2$ error bound. We introduce a new splicing technique for adaptive parameter selection to tackle subproblems under $ell_0$ constraints and a Generalized Information Criterion (GIC). Our theoretical and numerical studies show that the proposed algorithm correctly finds the true sparsity pattern, has the oracle property, and greatly lowers communication costs. This is a big step forward in distributed sparse estimation.
Read more9/2/2024

0
Dynamic Incremental Optimization for Best Subset Selection
Shaogang Ren, Xiaoning Qian
Best subset selection is considered the `gold standard' for many sparse learning problems. A variety of optimization techniques have been proposed to attack this non-smooth non-convex problem. In this paper, we investigate the dual forms of a family of $ell_0$-regularized problems. An efficient primal-dual algorithm is developed based on the primal and dual problem structures. By leveraging the dual range estimation along with the incremental strategy, our algorithm potentially reduces redundant computation and improves the solutions of best subset selection. Theoretical analysis and experiments on synthetic and real-world datasets validate the efficiency and statistical properties of the proposed solutions.
Read more6/5/2024

0
On the Computational Complexity of Private High-dimensional Model Selection
Saptarshi Roy, Zehua Wang, Ambuj Tewari
We consider the problem of model selection in a high-dimensional sparse linear regression model under privacy constraints. We propose a differentially private best subset selection method with strong utility properties by adopting the well-known exponential mechanism for selecting the best model. We propose an efficient Metropolis-Hastings algorithm and establish that it enjoys polynomial mixing time to its stationary distribution. Furthermore, we also establish approximate differential privacy for the estimates of the mixed Metropolis-Hastings chain. Finally, we perform some illustrative experiments that show the strong utility of our algorithm.
Read more5/27/2024
0
Localized Distributional Robustness in Submodular Multi-Task Subset Selection
Ege C. Kaya, Abolfazl Hashemi
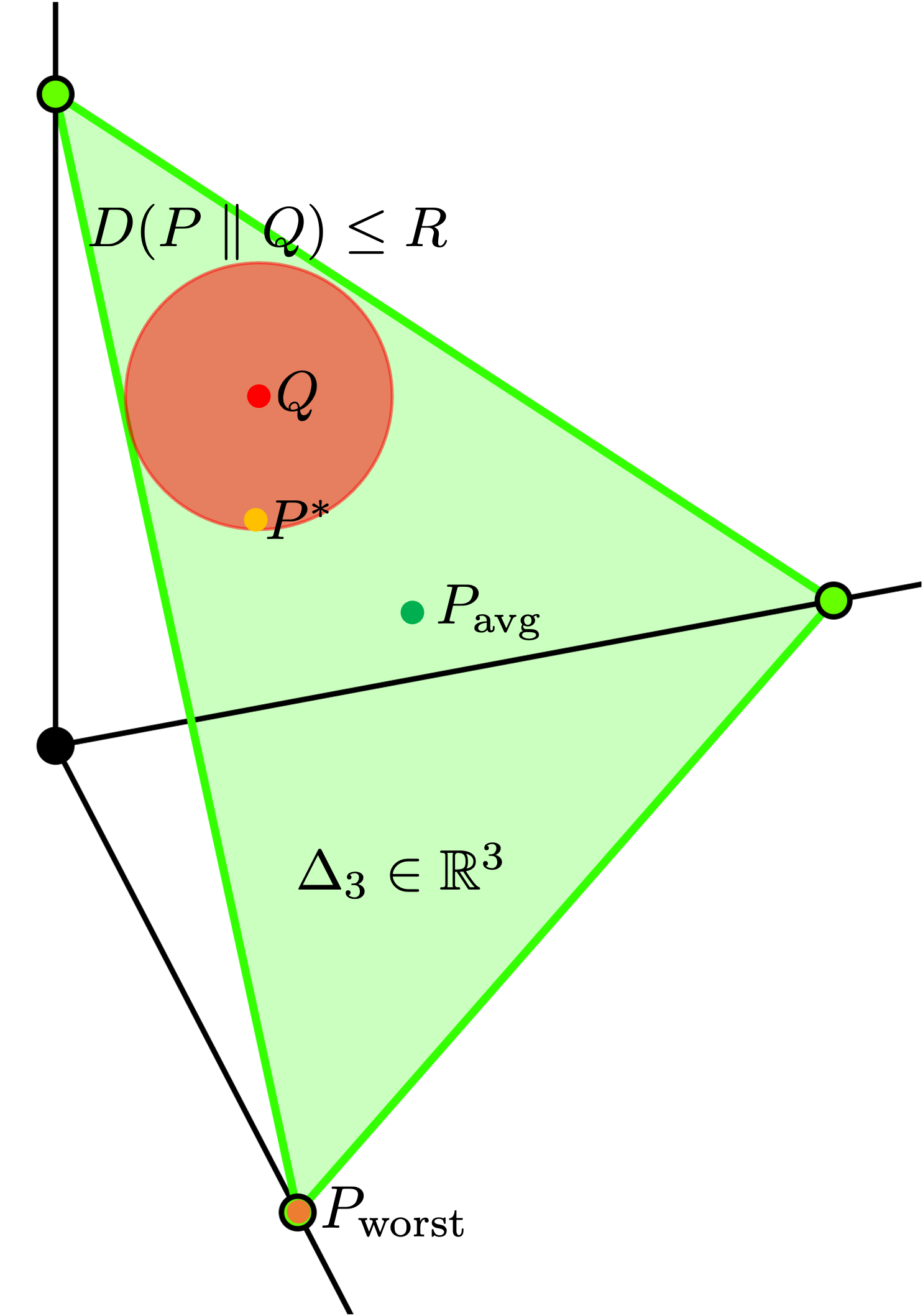
In this work, we approach the problem of multi-task submodular optimization with the perspective of local distributional robustness, within the neighborhood of a reference distribution which assigns an importance score to each task. We initially propose to introduce a regularization term which makes use of the relative entropy to the standard multi-task objective. We then demonstrate through duality that this novel formulation itself is equivalent to the maximization of a submodular function, which may be efficiently carried out through standard greedy selection methods. This approach bridges the existing gap in the optimization of performance-robustness trade-offs in multi-task subset selection. To numerically validate our theoretical results, we test the proposed method in two different setting, one involving the selection of satellites in low Earth orbit constellations in the context of a sensor selection problem, and the other involving an image summarization task using neural networks. Our method is compared with two other algorithms focused on optimizing the performance of the worst-case task, and on directly optimizing the performance on the reference distribution itself. We conclude that our novel formulation produces a solution that is locally distributional robust, and computationally inexpensive.
Read more4/8/2024