Mirage: Cross-Embodiment Zero-Shot Policy Transfer with Cross-Painting

0

Sign in to get full access
Overview
- This paper presents a novel approach called "Mirage" that enables cross-embodiment zero-shot policy transfer with cross-painting.
- The key idea is to leverage generative modeling and meta-learning to transfer manipulation skills from one robotic embodiment to another, without the need for any fine-tuning or adaptation.
- The proposed method is evaluated on a range of robotic manipulation tasks, demonstrating its ability to enable effective skill transfer across different robot morphologies and dynamics.
Plain English Explanation
The paper describes a new technique called "Mirage" that allows robots to learn a skill in one body and then use that knowledge to perform the same task in a completely different body, without any additional training. This is an important capability, as it can save time and resources when deploying robots in new environments or with different physical characteristics.
The core of the Mirage approach is to use generative modeling and meta-learning to capture the essential features of a manipulation skill, rather than just memorizing the specific motions required for a particular robot. This "learned essence" of the skill can then be transferred to a new robot, which can then use it to perform the task effectively, even if its body shape, weight, or other properties are quite different from the original.
The researchers demonstrate the effectiveness of Mirage on a variety of robotic manipulation tasks, showing that it can enable smooth skill transfer across a wide range of robotic embodiments. This is a significant advance over traditional methods, which typically require extensive fine-tuning or adaptation when moving a skill from one robot to another.
Technical Explanation
The Mirage framework [https://aimodels.fyi/papers/arxiv/cross-embodiment-robot-manipulation-skill-transfer-using] consists of two key components: a generative painting module and a meta-learning policy transfer module.
The generative painting module [https://aimodels.fyi/papers/arxiv/imagination-policy-using-generative-point-cloud-models] learns a latent representation of the robot's state and action space, which can then be used to generate novel point cloud "paintings" of the robot's motion. These paintings capture the essential features of the skill, rather than just the specific joint trajectories.
The meta-learning policy transfer module [https://aimodels.fyi/papers/arxiv/one-shot-imitation-learning-invariance-matching-robotic, https://aimodels.fyi/papers/arxiv/meta-evolve-continuous-robot-evolution-one-to] then takes these generative paintings and uses them to train a policy that can be directly transferred to a new robot embodiment, without any fine-tuning or adaptation.
The researchers evaluate Mirage on a range of robotic manipulation tasks, including reaching, grasping, and in-hand manipulation. They show that Mirage can enable effective skill transfer across different robot morphologies and dynamics, outperforming traditional methods that require extensive adaptation.
Critical Analysis
The Mirage approach addresses an important challenge in robotics – the ability to transfer skills across different embodiments without costly retraining. The authors provide a compelling technical solution and present thorough experimental results to validate its effectiveness.
However, the paper does not discuss some potential limitations or areas for further research. For example, it is unclear how well Mirage would scale to more complex manipulation tasks or to situations where the target robot's capabilities differ more significantly from the source robot. Additionally, the paper does not explore the sample efficiency of the meta-learning approach or its robustness to noisy or imperfect sensor data.
Furthermore, while the authors mention the importance of cross-embodiment skill transfer for real-world deployment, they do not provide any analysis of the practical implications or potential societal impacts of this technology. Exploring these aspects could help situate the research within a broader context and identify important considerations for future development.
Conclusion
The Mirage framework presented in this paper represents a significant advance in the field of robotic manipulation skill transfer. By leveraging generative modeling and meta-learning, the approach enables zero-shot transfer of skills across diverse robotic embodiments, without the need for costly fine-tuning or adaptation.
The experimental results demonstrate the effectiveness of Mirage on a range of manipulation tasks, suggesting that it could have important practical applications in areas such as industrial automation, service robotics, and disaster response. As the authors note, the ability to rapidly deploy robotic skills across different platforms could lead to more efficient and flexible robotic systems, with potential benefits for both industry and society.
Overall, the Mirage paper presents a novel and promising solution to a key challenge in robotics, and the insights and techniques developed could have broader implications for other areas of machine learning and autonomous systems research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mirage: Cross-Embodiment Zero-Shot Policy Transfer with Cross-Painting
Lawrence Yunliang Chen, Kush Hari, Karthik Dharmarajan, Chenfeng Xu, Quan Vuong, Ken Goldberg
The ability to reuse collected data and transfer trained policies between robots could alleviate the burden of additional data collection and training. While existing approaches such as pretraining plus finetuning and co-training show promise, they do not generalize to robots unseen in training. Focusing on common robot arms with similar workspaces and 2-jaw grippers, we investigate the feasibility of zero-shot transfer. Through simulation studies on 8 manipulation tasks, we find that state-based Cartesian control policies can successfully zero-shot transfer to a target robot after accounting for forward dynamics. To address robot visual disparities for vision-based policies, we introduce Mirage, which uses cross-painting--masking out the unseen target robot and inpainting the seen source robot--during execution in real time so that it appears to the policy as if the trained source robot were performing the task. Mirage applies to both first-person and third-person camera views and policies that take in both states and images as inputs or only images as inputs. Despite its simplicity, our extensive simulation and physical experiments provide strong evidence that Mirage can successfully zero-shot transfer between different robot arms and grippers with only minimal performance degradation on a variety of manipulation tasks such as picking, stacking, and assembly, significantly outperforming a generalist policy. Project website: https://robot-mirage.github.io/
Read more9/10/2024
0
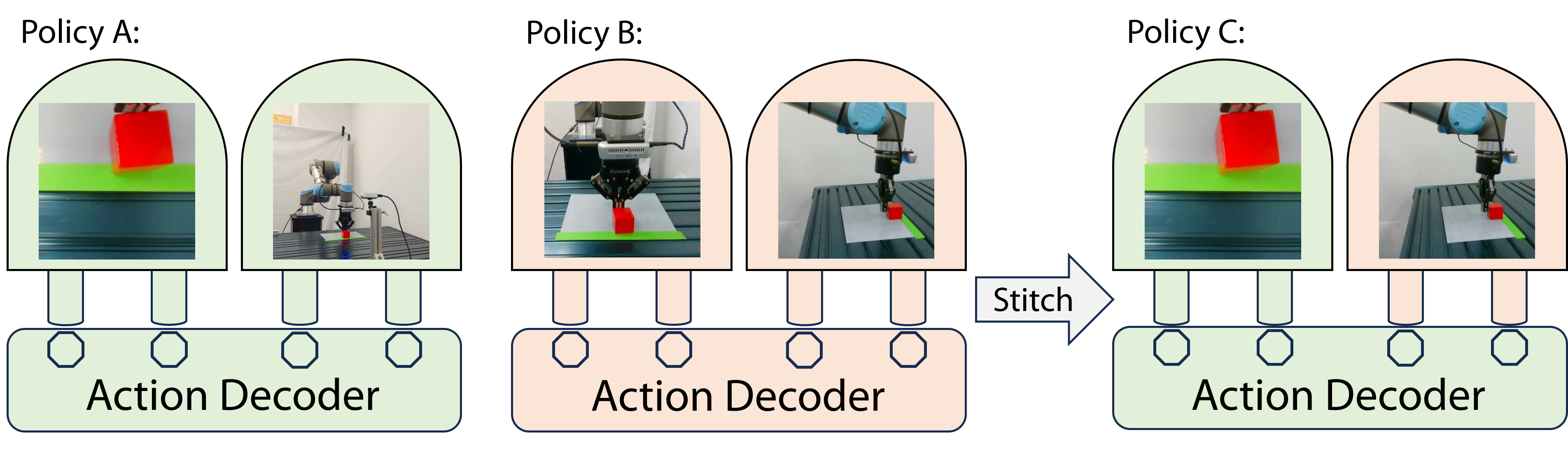
Perception Stitching: Zero-Shot Perception Encoder Transfer for Visuomotor Robot Policies
Pingcheng Jian, Easop Lee, Zachary Bell, Michael M. Zavlanos, Boyuan Chen
Vision-based imitation learning has shown promising capabilities of endowing robots with various motion skills given visual observation. However, current visuomotor policies fail to adapt to drastic changes in their visual observations. We present Perception Stitching that enables strong zero-shot adaptation to large visual changes by directly stitching novel combinations of visual encoders. Our key idea is to enforce modularity of visual encoders by aligning the latent visual features among different visuomotor policies. Our method disentangles the perceptual knowledge with the downstream motion skills and allows the reuse of the visual encoders by directly stitching them to a policy network trained with partially different visual conditions. We evaluate our method in various simulated and real-world manipulation tasks. While baseline methods failed at all attempts, our method could achieve zero-shot success in real-world visuomotor tasks. Our quantitative and qualitative analysis of the learned features of the policy network provides more insights into the high performance of our proposed method.
Read more7/1/2024

0
Cross-Embodiment Robot Manipulation Skill Transfer using Latent Space Alignment
Tianyu Wang, Dwait Bhatt, Xiaolong Wang, Nikolay Atanasov
This paper focuses on transferring control policies between robot manipulators with different morphology. While reinforcement learning (RL) methods have shown successful results in robot manipulation tasks, transferring a trained policy from simulation to a real robot or deploying it on a robot with different states, actions, or kinematics is challenging. To achieve cross-embodiment policy transfer, our key insight is to project the state and action spaces of the source and target robots to a common latent space representation. We first introduce encoders and decoders to associate the states and actions of the source robot with a latent space. The encoders, decoders, and a latent space control policy are trained simultaneously using loss functions measuring task performance, latent dynamics consistency, and encoder-decoder ability to reconstruct the original states and actions. To transfer the learned control policy, we only need to train target encoders and decoders that align a new target domain to the latent space. We use generative adversarial training with cycle consistency and latent dynamics losses without access to the task reward or reward tuning in the target domain. We demonstrate sim-to-sim and sim-to-real manipulation policy transfer with source and target robots of different states, actions, and embodiments. The source code is available at url{https://github.com/ExistentialRobotics/cross_embodiment_transfer}.
Read more6/5/2024

0
Scaling Cross-Embodied Learning: One Policy for Manipulation, Navigation, Locomotion and Aviation
Ria Doshi, Homer Walke, Oier Mees, Sudeep Dasari, Sergey Levine
Modern machine learning systems rely on large datasets to attain broad generalization, and this often poses a challenge in robot learning, where each robotic platform and task might have only a small dataset. By training a single policy across many different kinds of robots, a robot learning method can leverage much broader and more diverse datasets, which in turn can lead to better generalization and robustness. However, training a single policy on multi-robot data is challenging because robots can have widely varying sensors, actuators, and control frequencies. We propose CrossFormer, a scalable and flexible transformer-based policy that can consume data from any embodiment. We train CrossFormer on the largest and most diverse dataset to date, 900K trajectories across 20 different robot embodiments. We demonstrate that the same network weights can control vastly different robots, including single and dual arm manipulation systems, wheeled robots, quadcopters, and quadrupeds. Unlike prior work, our model does not require manual alignment of the observation or action spaces. Extensive experiments in the real world show that our method matches the performance of specialist policies tailored for each embodiment, while also significantly outperforming the prior state of the art in cross-embodiment learning.
Read more8/22/2024