Perception Stitching: Zero-Shot Perception Encoder Transfer for Visuomotor Robot Policies

0
Sign in to get full access
Overview
- This paper introduces a "perception stitching" approach to enable zero-shot transfer of visuomotor robot policies.
- The key idea is to learn a perception encoder that can be transferred to novel environments, rather than learning a full end-to-end policy from scratch.
- This allows for efficient policy learning and deployment in new settings, without requiring costly data collection and training from the ground up.
Plain English Explanation
The paper presents a method called "perception stitching" that allows robot policies to be transferred to new environments without having to completely retrain the policy from the beginning. The key insight is to separate the perception (understanding what the robot is seeing) from the control (deciding how the robot should move).
By learning a general perception encoder that can be transferred to new settings, the robot can quickly adapt its policy to work in the new environment, rather than having to learn both perception and control from scratch. This is important because collecting large amounts of training data in new environments can be very time-consuming and expensive for robotic systems.
The perception stitching approach aims to make robot policies more flexible and efficient, allowing them to be deployed across a wider range of scenarios without the need for extensive retraining. This could enable robotic systems to be more readily applied to real-world tasks in diverse settings.
Technical Explanation
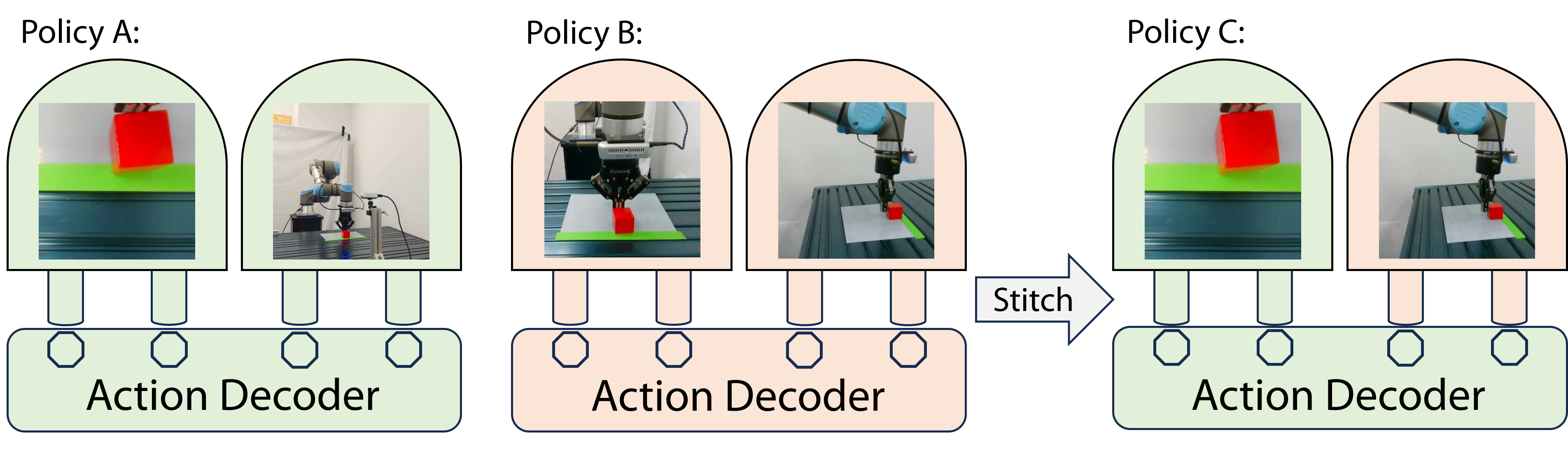
The paper proposes a "perception stitching" approach to enable zero-shot policy transfer for visuomotor robot control. The core idea is to decouple the perception and control components of the policy, and learn a transferable perception encoder that can be combined with a task-specific control module.
The key steps are:
- Train a perception encoder on a diverse set of visual data, using self-supervised learning techniques like contrastive loss.
- Freeze the perception encoder and train a control module (e.g. a policy network) on a specific task in a source environment.
- To deploy in a new target environment, simply transfer the pre-trained perception encoder and fine-tune the control module, rather than training the entire policy from scratch.
This "perception stitching" approach allows the robot to rapidly adapt to new settings by leveraging the transferable perception capabilities, rather than having to relearn visual understanding for each new task and environment. The authors demonstrate the effectiveness of this approach on several simulated robot manipulation tasks.
Critical Analysis
The perception stitching approach presented in this paper addresses an important challenge in robotic learning - the ability to efficiently transfer policies to new environments without costly retraining. By decoupling perception and control, the method allows the robot to leverage its learned visual understanding when deploying in novel settings.
However, a key limitation is that the method still requires fine-tuning of the control module for each new target environment. While this is more efficient than training the entire policy from scratch, it may still be burdensome in some real-world applications where rapid deployment is critical.
Additionally, the paper only evaluates the approach in simulation, so further research is needed to understand how well it would translate to physical robot systems and more complex real-world environments. Robustness to domain shift, sensor noise, and other practical challenges would be important to assess.
Overall, the perception stitching concept is a promising step towards more flexible and efficient robotic learning, but additional work is needed to fully realize its potential and address its current limitations. Continued research into zero-shot policy transfer and prompt-based visual alignment could further enhance the capabilities of this approach.
Conclusion
The "perception stitching" method presented in this paper offers a novel approach to enabling zero-shot transfer of visuomotor robot policies. By decoupling perception and control, the technique allows robotic systems to leverage their learned visual understanding when deployed in new environments, rather than having to completely retrain from scratch.
This has the potential to significantly improve the efficiency and flexibility of robotic learning, enabling more widespread deployment of these systems in diverse real-world applications. While the current work is limited to simulation, further research into related zero-shot transfer and neural ODE techniques could lead to even more capable and adaptable robotic policies in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Perception Stitching: Zero-Shot Perception Encoder Transfer for Visuomotor Robot Policies
Pingcheng Jian, Easop Lee, Zachary Bell, Michael M. Zavlanos, Boyuan Chen
Vision-based imitation learning has shown promising capabilities of endowing robots with various motion skills given visual observation. However, current visuomotor policies fail to adapt to drastic changes in their visual observations. We present Perception Stitching that enables strong zero-shot adaptation to large visual changes by directly stitching novel combinations of visual encoders. Our key idea is to enforce modularity of visual encoders by aligning the latent visual features among different visuomotor policies. Our method disentangles the perceptual knowledge with the downstream motion skills and allows the reuse of the visual encoders by directly stitching them to a policy network trained with partially different visual conditions. We evaluate our method in various simulated and real-world manipulation tasks. While baseline methods failed at all attempts, our method could achieve zero-shot success in real-world visuomotor tasks. Our quantitative and qualitative analysis of the learned features of the policy network provides more insights into the high performance of our proposed method.
Read more7/1/2024

0
View-Invariant Policy Learning via Zero-Shot Novel View Synthesis
Stephen Tian, Blake Wulfe, Kyle Sargent, Katherine Liu, Sergey Zakharov, Vitor Guizilini, Jiajun Wu
Large-scale visuomotor policy learning is a promising approach toward developing generalizable manipulation systems. Yet, policies that can be deployed on diverse embodiments, environments, and observational modalities remain elusive. In this work, we investigate how knowledge from large-scale visual data of the world may be used to address one axis of variation for generalizable manipulation: observational viewpoint. Specifically, we study single-image novel view synthesis models, which learn 3D-aware scene-level priors by rendering images of the same scene from alternate camera viewpoints given a single input image. For practical application to diverse robotic data, these models must operate zero-shot, performing view synthesis on unseen tasks and environments. We empirically analyze view synthesis models within a simple data-augmentation scheme that we call View Synthesis Augmentation (VISTA) to understand their capabilities for learning viewpoint-invariant policies from single-viewpoint demonstration data. Upon evaluating the robustness of policies trained with our method to out-of-distribution camera viewpoints, we find that they outperform baselines in both simulated and real-world manipulation tasks. Videos and additional visualizations are available at https://s-tian.github.io/projects/vista.
Read more9/6/2024

0
Mirage: Cross-Embodiment Zero-Shot Policy Transfer with Cross-Painting
Lawrence Yunliang Chen, Kush Hari, Karthik Dharmarajan, Chenfeng Xu, Quan Vuong, Ken Goldberg
The ability to reuse collected data and transfer trained policies between robots could alleviate the burden of additional data collection and training. While existing approaches such as pretraining plus finetuning and co-training show promise, they do not generalize to robots unseen in training. Focusing on common robot arms with similar workspaces and 2-jaw grippers, we investigate the feasibility of zero-shot transfer. Through simulation studies on 8 manipulation tasks, we find that state-based Cartesian control policies can successfully zero-shot transfer to a target robot after accounting for forward dynamics. To address robot visual disparities for vision-based policies, we introduce Mirage, which uses cross-painting--masking out the unseen target robot and inpainting the seen source robot--during execution in real time so that it appears to the policy as if the trained source robot were performing the task. Mirage applies to both first-person and third-person camera views and policies that take in both states and images as inputs or only images as inputs. Despite its simplicity, our extensive simulation and physical experiments provide strong evidence that Mirage can successfully zero-shot transfer between different robot arms and grippers with only minimal performance degradation on a variety of manipulation tasks such as picking, stacking, and assembly, significantly outperforming a generalist policy. Project website: https://robot-mirage.github.io/
Read more9/10/2024
0
Dreamitate: Real-World Visuomotor Policy Learning via Video Generation
Junbang Liang, Ruoshi Liu, Ege Ozguroglu, Sruthi Sudhakar, Achal Dave, Pavel Tokmakov, Shuran Song, Carl Vondrick
A key challenge in manipulation is learning a policy that can robustly generalize to diverse visual environments. A promising mechanism for learning robust policies is to leverage video generative models, which are pretrained on large-scale datasets of internet videos. In this paper, we propose a visuomotor policy learning framework that fine-tunes a video diffusion model on human demonstrations of a given task. At test time, we generate an example of an execution of the task conditioned on images of a novel scene, and use this synthesized execution directly to control the robot. Our key insight is that using common tools allows us to effortlessly bridge the embodiment gap between the human hand and the robot manipulator. We evaluate our approach on four tasks of increasing complexity and demonstrate that harnessing internet-scale generative models allows the learned policy to achieve a significantly higher degree of generalization than existing behavior cloning approaches.
Read more6/26/2024