Scaling Cross-Embodied Learning: One Policy for Manipulation, Navigation, Locomotion and Aviation

0

Sign in to get full access
Overview
- The research paper explores a novel approach for scaling cross-embodied learning, allowing a single policy to handle diverse tasks such as manipulation, navigation, locomotion, and aviation.
- The proposed method aims to enable robots to perform a wide range of skills by training a universal policy that can be applied across different embodiments and scenarios.
- The study investigates the feasibility of learning a single policy that can effectively handle various robotic tasks, going beyond the typical specialization of policies for individual skills.
Plain English Explanation
The paper presents a new way to teach robots a wide variety of skills using a single set of instructions, or "policy." Typically, robots are trained to perform specific tasks like manipulating objects, navigating through environments, or flying drones. In this research, the scientists wanted to see if they could train a single policy that could handle all of these different types of tasks, regardless of the robot's physical form or capabilities.
The key idea is to create a universal policy that can be applied across various robotic embodiments, allowing the same set of instructions to control robots with different bodies, such as arms, legs, or wings. This could be very useful in the real world, where robots might need to adapt to different situations and tasks. Instead of having to train a separate policy for each new task, the researchers wanted to see if they could develop a single policy that could handle a diverse range of robotic abilities.
By creating a more flexible and versatile policy, the researchers hope to enable robots to be more useful and adaptable in real-world scenarios, where they may need to switch between different skills and capabilities to accomplish their goals.
Technical Explanation
The paper proposes a novel approach for scaling cross-embodied learning, which aims to learn a single policy that can be applied across diverse robotic tasks and embodiments. This includes manipulation, navigation, locomotion, and even aviation.
The key innovation is the development of a universal policy that can be applied across different robotic embodiments, allowing a single set of instructions to control a wide range of skills and capabilities. This contrasts with the typical approach of training specialized policies for individual tasks.
The researchers conducted experiments to evaluate the feasibility of this cross-embodied learning approach, assessing the policy's performance across various robotic domains. The results demonstrate the potential for a single policy to effectively handle diverse robotic tasks, paving the way for more adaptable and versatile robot systems.
Critical Analysis
The paper presents an ambitious and promising approach to scaling cross-embodied learning, but it also acknowledges several caveats and areas for further research. The authors note that while the proposed method shows promising results, there are still challenges in achieving truly universal policies that can seamlessly transfer between vastly different embodiments and scenarios.
One potential limitation is the reliance on simulated environments for training and evaluation. The researchers suggest that further work is needed to validate the approach in real-world settings, where the complexities of physical interactions and environmental factors may pose additional challenges.
Furthermore, the paper highlights the need for continued advancements in areas such as embodiment-aware policy learning and zero-shot policy transfer to fully realize the potential of cross-embodied learning.
Overall, the research presented in this paper represents an important step towards more flexible and adaptable robot systems, but further exploration and validation will be necessary to address the remaining challenges and limitations.
Conclusion
This research paper introduces a novel approach for scaling cross-embodied learning, enabling a single policy to handle a diverse range of robotic tasks, including manipulation, navigation, locomotion, and even aviation.
The key contribution is the development of a universal policy that can be applied across different robotic embodiments, allowing a single set of instructions to control a wide range of skills and capabilities. This represents a significant advancement towards more adaptable and versatile robot systems, which could have far-reaching implications for real-world applications.
While the research demonstrates promising results, the authors also identify areas for further exploration, such as validating the approach in physical environments and addressing the challenges of achieving truly seamless cross-embodied policy transfer. Continued advancements in embodiment-aware policy learning and zero-shot policy transfer will be crucial in realizing the full potential of this cross-embodied learning paradigm.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Scaling Cross-Embodied Learning: One Policy for Manipulation, Navigation, Locomotion and Aviation
Ria Doshi, Homer Walke, Oier Mees, Sudeep Dasari, Sergey Levine
Modern machine learning systems rely on large datasets to attain broad generalization, and this often poses a challenge in robot learning, where each robotic platform and task might have only a small dataset. By training a single policy across many different kinds of robots, a robot learning method can leverage much broader and more diverse datasets, which in turn can lead to better generalization and robustness. However, training a single policy on multi-robot data is challenging because robots can have widely varying sensors, actuators, and control frequencies. We propose CrossFormer, a scalable and flexible transformer-based policy that can consume data from any embodiment. We train CrossFormer on the largest and most diverse dataset to date, 900K trajectories across 20 different robot embodiments. We demonstrate that the same network weights can control vastly different robots, including single and dual arm manipulation systems, wheeled robots, quadcopters, and quadrupeds. Unlike prior work, our model does not require manual alignment of the observation or action spaces. Extensive experiments in the real world show that our method matches the performance of specialist policies tailored for each embodiment, while also significantly outperforming the prior state of the art in cross-embodiment learning.
Read more8/22/2024
0
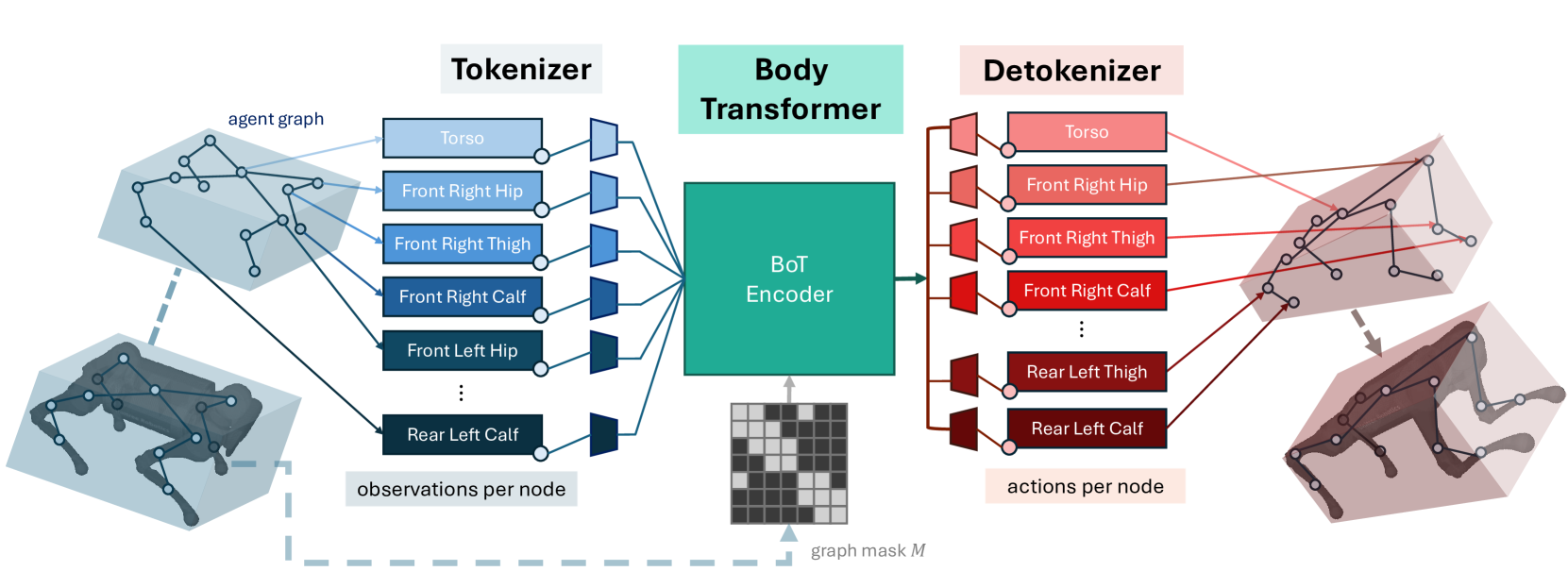
Body Transformer: Leveraging Robot Embodiment for Policy Learning
Carmelo Sferrazza, Dun-Ming Huang, Fangchen Liu, Jongmin Lee, Pieter Abbeel
In recent years, the transformer architecture has become the de facto standard for machine learning algorithms applied to natural language processing and computer vision. Despite notable evidence of successful deployment of this architecture in the context of robot learning, we claim that vanilla transformers do not fully exploit the structure of the robot learning problem. Therefore, we propose Body Transformer (BoT), an architecture that leverages the robot embodiment by providing an inductive bias that guides the learning process. We represent the robot body as a graph of sensors and actuators, and rely on masked attention to pool information throughout the architecture. The resulting architecture outperforms the vanilla transformer, as well as the classical multilayer perceptron, in terms of task completion, scaling properties, and computational efficiency when representing either imitation or reinforcement learning policies. Additional material including the open-source code is available at https://sferrazza.cc/bot_site.
Read more8/13/2024

0
Cross-Embodiment Robot Manipulation Skill Transfer using Latent Space Alignment
Tianyu Wang, Dwait Bhatt, Xiaolong Wang, Nikolay Atanasov
This paper focuses on transferring control policies between robot manipulators with different morphology. While reinforcement learning (RL) methods have shown successful results in robot manipulation tasks, transferring a trained policy from simulation to a real robot or deploying it on a robot with different states, actions, or kinematics is challenging. To achieve cross-embodiment policy transfer, our key insight is to project the state and action spaces of the source and target robots to a common latent space representation. We first introduce encoders and decoders to associate the states and actions of the source robot with a latent space. The encoders, decoders, and a latent space control policy are trained simultaneously using loss functions measuring task performance, latent dynamics consistency, and encoder-decoder ability to reconstruct the original states and actions. To transfer the learned control policy, we only need to train target encoders and decoders that align a new target domain to the latent space. We use generative adversarial training with cycle consistency and latent dynamics losses without access to the task reward or reward tuning in the target domain. We demonstrate sim-to-sim and sim-to-real manipulation policy transfer with source and target robots of different states, actions, and embodiments. The source code is available at url{https://github.com/ExistentialRobotics/cross_embodiment_transfer}.
Read more6/5/2024

0
One Policy to Run Them All: an End-to-end Learning Approach to Multi-Embodiment Locomotion
Nico Bohlinger, Grzegorz Czechmanowski, Maciej Krupka, Piotr Kicki, Krzysztof Walas, Jan Peters, Davide Tateo
Deep Reinforcement Learning techniques are achieving state-of-the-art results in robust legged locomotion. While there exists a wide variety of legged platforms such as quadruped, humanoids, and hexapods, the field is still missing a single learning framework that can control all these different embodiments easily and effectively and possibly transfer, zero or few-shot, to unseen robot embodiments. We introduce URMA, the Unified Robot Morphology Architecture, to close this gap. Our framework brings the end-to-end Multi-Task Reinforcement Learning approach to the realm of legged robots, enabling the learned policy to control any type of robot morphology. The key idea of our method is to allow the network to learn an abstract locomotion controller that can be seamlessly shared between embodiments thanks to our morphology-agnostic encoders and decoders. This flexible architecture can be seen as a potential first step in building a foundation model for legged robot locomotion. Our experiments show that URMA can learn a locomotion policy on multiple embodiments that can be easily transferred to unseen robot platforms in simulation and the real world.
Read more9/11/2024