Mitigate the Gap: Investigating Approaches for Improving Cross-Modal Alignment in CLIP
2406.17639
0
0
Abstract
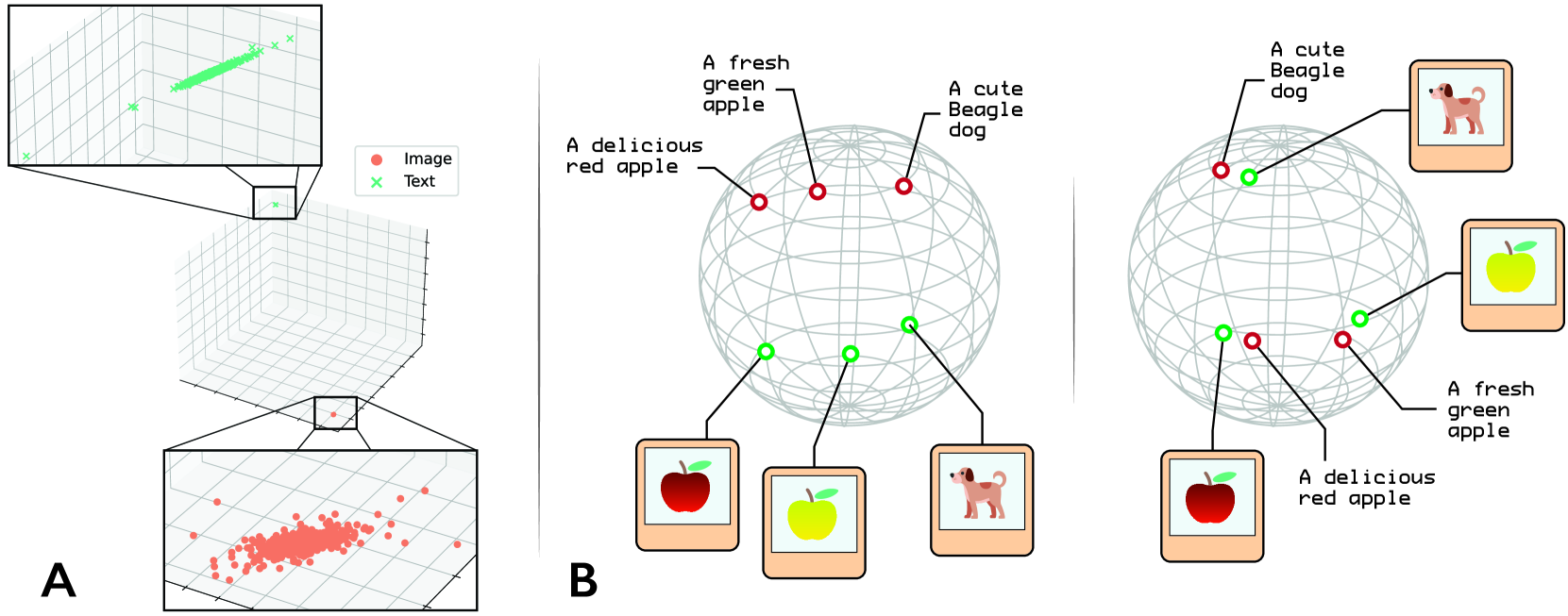
Contrastive Language--Image Pre-training (CLIP) has manifested remarkable improvements in zero-shot classification and cross-modal vision-language tasks. Yet, from a geometrical point of view, the CLIP embedding space has been found to have a pronounced modality gap. This gap renders the embedding space overly sparse and disconnected, with different modalities being densely distributed in distinct subregions of the hypersphere. In this work, we aim at answering two main questions: 1. Does sharing the parameter space between the multi-modal encoders reduce the modality gap? 2. Can the gap be mitigated by pushing apart the uni-modal embeddings via intra-modality separation? We design AlignCLIP, in order to answer these questions and show that answers to both questions are positive. Through extensive experiments, we show that AlignCLIP achieves noticeable enhancements in the cross-modal alignment of the embeddings, and thereby, reduces the modality gap, while maintaining the performance across several downstream evaluations, such as zero-shot image classification, zero-shot multi-modal retrieval and zero-shot semantic text similarity.
Create account to get full access
Overview
- This paper investigates approaches for improving cross-modal alignment in CLIP, a popular machine learning model that learns to associate images with their corresponding text descriptions.
- The researchers aim to mitigate the "modality gap" - the mismatch between representations learned from images and text, which can lead to suboptimal performance on various tasks.
- The paper explores different techniques, including Its Not Modality Gap: Characterizing and Addressing Contrastive, Topological Perspectives on Optimal Multimodal Embedding Spaces, Gentle CLIP: Exploring Aligned Semantic and Low-Quality, Two Effects, One Trigger: Modality Gap in Object, and Linking Representations for Multimodal Contrastive Learning, to improve the cross-modal alignment in CLIP.
Plain English Explanation
The paper focuses on improving a machine learning model called CLIP, which can associate images with their corresponding text descriptions. However, there is often a "gap" between the representations (or internal understanding) that CLIP develops for images versus text, which can lead to suboptimal performance on various tasks.
The researchers explore different techniques to "mitigate the gap" and improve the cross-modal alignment in CLIP. This means helping CLIP to better match its understanding of images and text, so that it can more accurately connect them.
Some of the key ideas they investigate include:
- Addressing the Contrastive Gap: Looking at the mismatch between how CLIP learns from positive and negative examples during training, and how to fix this.
- Optimal Multimodal Embedding Spaces: Exploring the best way to represent images and text in a shared space so they are well-aligned.
- Leveraging Low-Quality Data: Using lower quality or less relevant data in training to help CLIP learn more robust cross-modal associations.
- Modality-Specific Effects: Understanding how the different modalities (images vs text) impact CLIP's learning in distinct ways.
- Linking Representations: Developing new training approaches to more tightly connect CLIP's image and text representations.
By exploring these different techniques, the researchers aim to improve CLIP's ability to accurately match images and their corresponding text descriptions, which has important applications in areas like image captioning, visual question answering, and retrieval.
Technical Explanation
The paper investigates several approaches to mitigate the "modality gap" in CLIP, which refers to the mismatch between the representations learned from images and text. This gap can lead to suboptimal performance on various cross-modal tasks.
One key idea explored is addressing the contrastive gap - looking at how CLIP learns from positive and negative examples during training, and how to better align these learning signals across modalities.
The researchers also investigate optimal multimodal embedding spaces - exploring the best way to represent images and text in a shared space so they are well-aligned.
Another technique explored is leveraging low-quality data - using lower quality or less relevant data in training to help CLIP learn more robust cross-modal associations.
The paper also examines modality-specific effects - understanding how the different modalities (images vs text) impact CLIP's learning in distinct ways.
Finally, the researchers propose new techniques for linking representations - developing training approaches to more tightly connect CLIP's image and text representations.
Through these diverse investigations, the paper aims to advance the state-of-the-art in cross-modal alignment for CLIP and similar models, with important implications for applications like image captioning, visual question answering, and retrieval.
Critical Analysis
The paper presents a comprehensive exploration of techniques to mitigate the modality gap in CLIP, a widely-used multimodal machine learning model. The authors thoughtfully investigate several different approaches, drawing insights from related work in this active area of research.
One potential limitation is that the paper's focus is primarily on improving CLIP's cross-modal alignment, rather than examining the broader implications or societal impacts of these models. As CLIP and similar systems become more widely deployed, it will be important to consider potential biases, fairness issues, and ethical considerations that may arise.
Additionally, while the paper provides detailed technical explanations of the various approaches, some of the concepts may still be challenging for a general audience to fully grasp. Further work to translate these ideas into more accessible, plain-language terms could help broaden the impact and understanding of this research.
That said, the paper makes a valuable contribution by rigorously investigating different strategies to enhance cross-modal alignment in CLIP. As models like CLIP become increasingly influential in real-world applications, continued research to improve their capabilities and address their limitations will be crucial. This work lays important groundwork in that direction.
Conclusion
This paper presents a thorough investigation of approaches to mitigate the modality gap in CLIP, a prominent machine learning model that associates images with corresponding text descriptions. By exploring techniques like addressing the contrastive gap, optimizing multimodal embedding spaces, leveraging low-quality data, understanding modality-specific effects, and linking representations, the researchers aim to improve the cross-modal alignment in CLIP.
These advancements have important implications for applications like image captioning, visual question answering, and retrieval, where accurate cross-modal associations are crucial. As models like CLIP become more widely adopted, continued research to enhance their capabilities and address their limitations will be essential. This work represents a valuable step forward in that direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Its Not a Modality Gap: Characterizing and Addressing the Contrastive Gap
Abrar Fahim, Alex Murphy, Alona Fyshe
0
0
Multi-modal contrastive models such as CLIP achieve state-of-the-art performance in zero-shot classification by embedding input images and texts on a joint representational space. Recently, a modality gap has been reported in two-encoder contrastive models like CLIP, meaning that the image and text embeddings reside in disjoint areas of the latent space. Previous studies suggest that this gap exists due to 1) the cone effect, 2) mismatched pairs in the dataset, and 3) insufficient training. We show that, even when accounting for all these factors, and even when using the same modality, the contrastive loss actually creates a gap during training. As a result, We propose that the modality gap is inherent to the two-encoder contrastive loss and rename it the contrastive gap. We present evidence that attributes this contrastive gap to low uniformity in CLIP space, resulting in embeddings that occupy only a small portion of the latent space. To close the gap, we adapt the uniformity and alignment properties of unimodal contrastive loss to the multi-modal setting and show that simply adding these terms to the CLIP loss distributes the embeddings more uniformly in the representational space, closing the gap. In our experiments, we show that the modified representational space achieves better performance than default CLIP loss in downstream tasks such as zero-shot image classification and multi-modal arithmetic.
6/10/2024

Topological Perspectives on Optimal Multimodal Embedding Spaces
Abdul Aziz A. B, A. B Abdul Rahim
0
0
Recent strides in multimodal model development have ignited a paradigm shift in the realm of text-to-image generation. Among these advancements, CLIP stands out as a remarkable achievement which is a sophisticated autoencoder adept at encoding both textual and visual information within a unified latent space. This paper delves into a comparative analysis between CLIP and its recent counterpart, CLOOB. To unravel the intricate distinctions within the embedding spaces crafted by these models, we employ topological data analysis. Our approach encompasses a comprehensive examination of the modality gap drivers, the clustering structures existing across both high and low dimensions, and the pivotal role that dimension collapse plays in shaping their respective embedding spaces. Empirical experiments substantiate the implications of our analyses on downstream performance across various contextual scenarios. Through this investigation, we aim to shed light on the nuanced intricacies that underlie the comparative efficacy of CLIP and CLOOB, offering insights into their respective strengths and weaknesses, and providing a foundation for further refinement and advancement in multimodal model research.
5/30/2024

Gentle-CLIP: Exploring Aligned Semantic In Low-Quality Multimodal Data With Soft Alignment
Zijia Song, Zelin Zang, Yelin Wang, Guozheng Yang, Jiangbin Zheng, Kaicheng yu, Wanyu Chen, Stan Z. Li
0
0
Multimodal fusion breaks through the barriers between diverse modalities and has already yielded numerous impressive performances. However, in various specialized fields, it is struggling to obtain sufficient alignment data for the training process, which seriously limits the use of previously elegant models. Thus, semi-supervised learning attempts to achieve multimodal alignment with fewer matched pairs but traditional methods like pseudo-labeling are difficult to apply in domains with no label information. To address these problems, we transform semi-supervised multimodal alignment into a manifold matching problem and propose a new method based on CLIP, named Gentle-CLIP. Specifically, we design a novel semantic density distribution loss to explore implicit semantic alignment information from unpaired multimodal data by constraining the latent representation distribution with fine granularity, thus eliminating the need for numerous strictly matched pairs. Meanwhile, we introduce multi-kernel maximum mean discrepancy as well as self-supervised contrastive loss to pull separate modality distributions closer and enhance the stability of the representation distribution. In addition, the contrastive loss used in CLIP is employed on the supervised matched data to prevent negative optimization. Extensive experiments conducted on a range of tasks in various fields, including protein, remote sensing, and the general vision-language field, demonstrate the effectiveness of our proposed Gentle-CLIP.
6/11/2024

Two Effects, One Trigger: On the Modality Gap, Object Bias, and Information Imbalance in Contrastive Vision-Language Representation Learning
Simon Schrodi, David T. Hoffmann, Max Argus, Volker Fischer, Thomas Brox
0
0
Contrastive vision-language models like CLIP have gained popularity for their versatile applicable learned representations in various downstream tasks. Despite their successes in some tasks, like zero-shot image recognition, they also perform surprisingly poor on other tasks, like attribute detection. Previous work has attributed these challenges to the modality gap, a separation of image and text in the shared representation space, and a bias towards objects over other factors, such as attributes. In this work we investigate both phenomena. We find that only a few embedding dimensions drive the modality gap. Further, we propose a measure for object bias and find that object bias does not lead to worse performance on other concepts, such as attributes. But what leads to the emergence of the modality gap and object bias? To answer this question we carefully designed an experimental setting which allows us to control the amount of shared information between the modalities. This revealed that the driving factor behind both, the modality gap and the object bias, is the information imbalance between images and captions.
4/12/2024